
DeepMind研究科学家:NLP基准测试的现在、过去和未来

什么是基准?
基准测试简史
指标很重要
考虑下游用例
细粒度评估
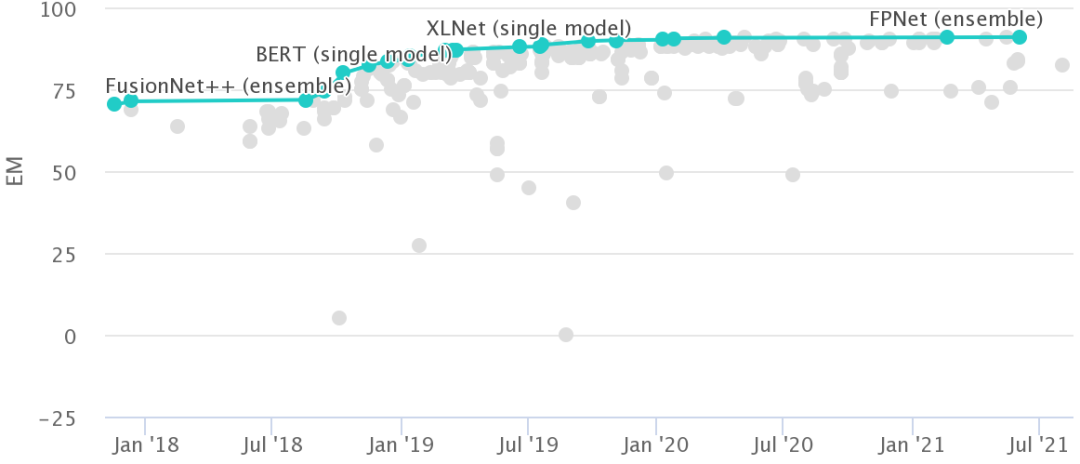
基准性能的长尾 大规模持续评估
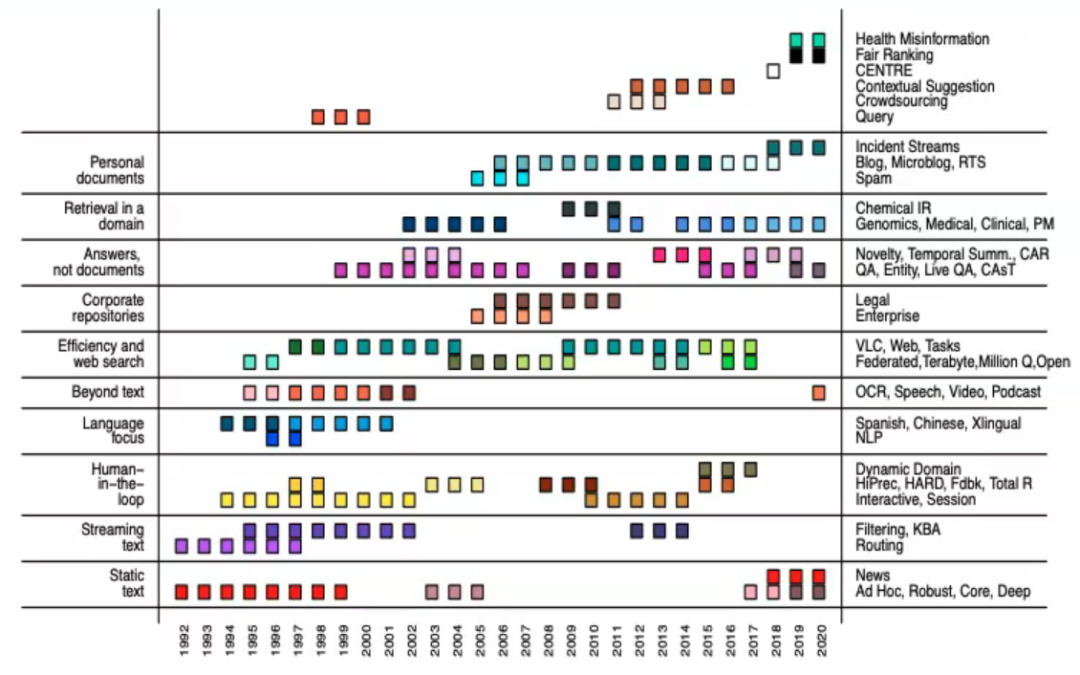
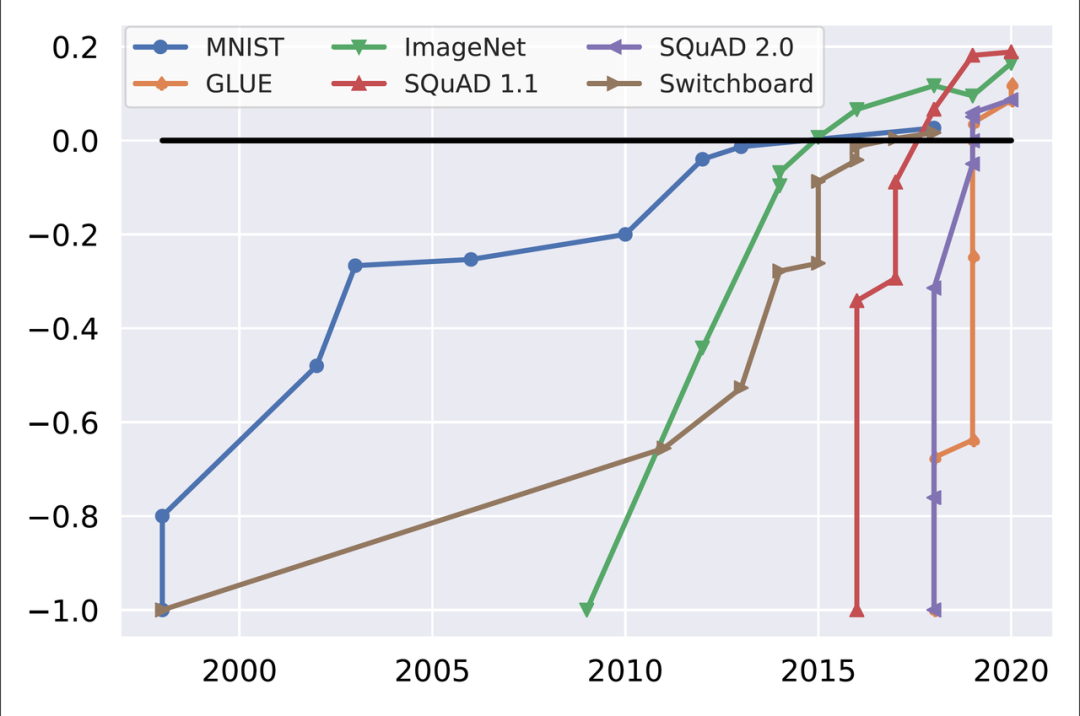

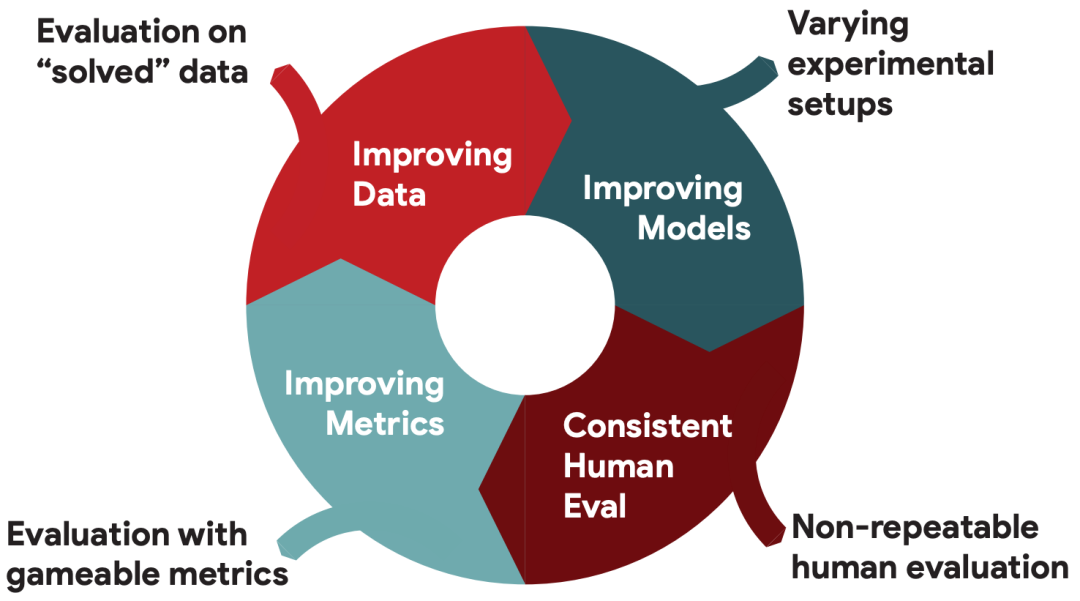
考虑更适合下游任务和语言的度量。
考虑强调下游设置权衡的指标。
随着时间的推移更新和完善指标。
设计基准及其评估,使其反映真实世界的用例。
评估域内和域外泛化。
收集数据并评估其他语言的模型。
从语言技术的现实应用中获得灵感。
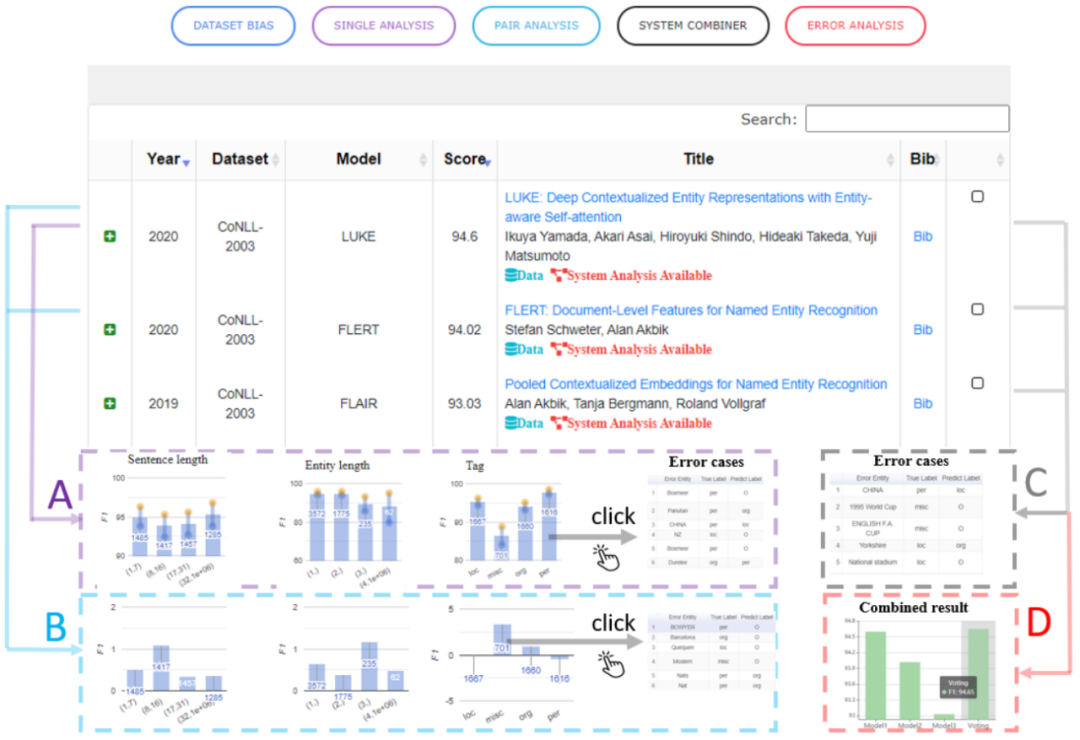
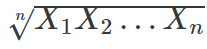
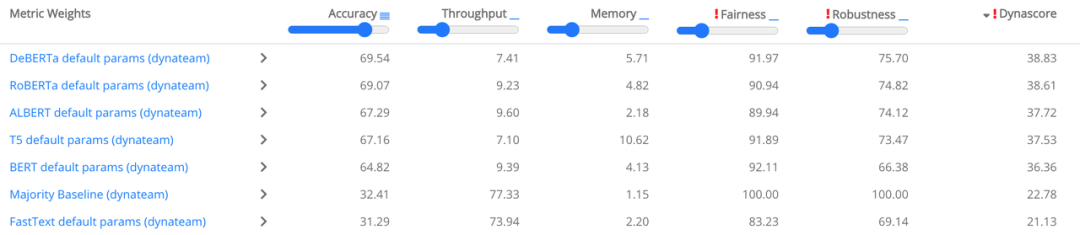
不再使用单一指标进行性能评估。
评估社会偏见和效率。
对模型执行细粒度评估。
考虑如何聚合多个指标。
在基准中包括许多和/或困难样本。
进行统计学显著性检验。
为不明确的示例收集多个注释。
报告注释者协议。
考虑收集和评估大型、多样化、版本化的 NLP 任务集合。
原文链接:https://ruder.io/nlp-benchmarking/
作者简介:
SEBASTIAN RUDER,是伦敦 DeepMind 语言团队的一名研究科学家。
2015-2019年就读于爱尔兰国立高威大学,工程与信息学院,自然语言处理博士毕业。
2017.4-2017.6在哥本哈根大学,自然语言处理组,计算机科学系研究访问。
2014.09-2015.01爱尔兰都柏林三一学院,海外学期,计算机科学与统计学院,计算机科学与语言
2012.10-2015.09就读于Ruprecht-Karls-Universität Heidelberg 德国海德堡计算语言学研究所,文学学士计算语言学、英语语言学。
SEBASTIAN RUDER在学习期间,曾与Microsoft、IBM 的 Extreme Blue、Google Summer of Code和SAP等机构合作。他对 NLP 的迁移学习使 ML 和 NLP 被大众所了解。

评论