
腾讯实验室提出GOLO | 实在优雅!一个简洁的像YOLO的DETR目标检测器来啦!!
共 23842字,需浏览 48分钟
· 2023-10-09
点击下方卡片,关注「AI视界引擎」公众号

自从DETR发布以来,基于 Query 的目标检测器已经取得了显著的进展。然而,大多数现有方法仍然依赖于多阶段的编码器和解码器,或者两者的结合。尽管多阶段范式(通常包括6个阶段)可以实现高精度,但它面临诸如重计算负担等问题,这促使作者重新考虑其必要性。
在本文中,作者探索了多种增强基于 Query 的检测器的技术,并基于这些发现提出了一种名为GOLO(Global Once and Local Once)的新模型,该模型遵循了一个两阶段的解码范式。与其他主流的基于 Query 的模型相比,作者的模型在使用更少的解码器阶段的情况下仍然能够取得相当好的性能。在COCO数据集上的实验结果证明了作者方法的有效性。
1、简介
目标检测是计算机视觉中的一个关键任务,涉及在图像中定位和分类目标。卷积神经网络在这个领域表现出色。然而,这些模型在训练和推断过程中仍然依赖于许多手工设计的组件,限制了它们的灵活性和泛化能力。
基于 Query 的检测器的出现,如DETR,引入了一类新的目标检测器,消除了像NMS这样的手工设计组件的需要。这些模型以其简单性和高性能而闻名。然而,它们通常严重依赖于多阶段编码器或解码器,通常由六个阶段组成。在其中,多阶段解码器被认为比多阶段编码器更关键,这可以通过各种检测器来证明。尽管这些多阶段解码器起着至关重要的作用,但多个阶段的引入导致了计算复杂性的增加、训练时间的延长和推断速度的减慢。然而,由于基于 Query 的检测器在训练和推断过程中依赖于逐步和动态的精细化,多阶段解码器对于实现所需的性能至关重要。
鉴于这一挑战,问题就出现了:作者如何减少阶段的数量并提高基于 Query 的检测器的效率?
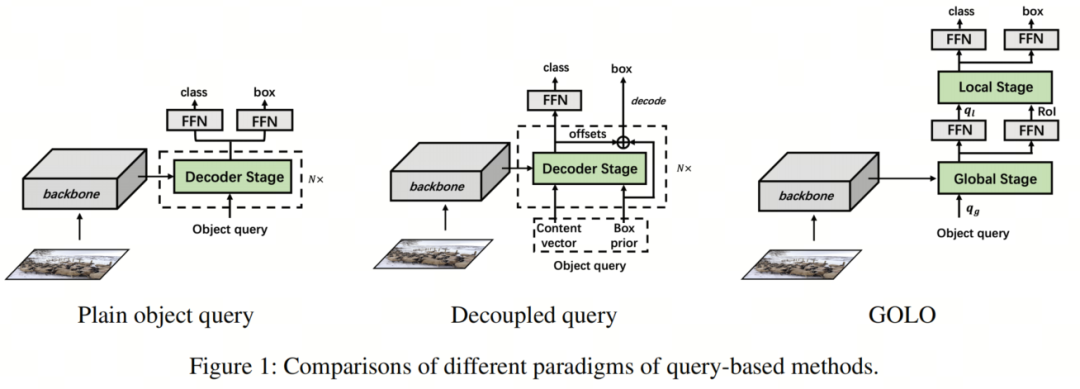
在这项工作中,作者提出了一个名为GOLO(Global Once and Local Once)的两阶段解决方案,以解决作者的关切。全局定位和局部细化的结合将作为消除多阶段范式需求的方向。如图1右侧所示,GOLO首先在全局尺度上粗略定位感兴趣区域(RoIs),然后在局部尺度上对每个RoI执行精确的回归和分类。每个阶段都包括了若干创新技术。
在全局目标定位阶段,作者提出了一种有效的方法,将来自多个尺度的特征进行整合,使得每个 Query 能够以相对较低的成本逐渐感知整个图像的多尺度特征。同时,作者采用了一个二分类方案来区分前景和背景,而不考虑具体的目标类别,这加速了模型在早期训练阶段的收敛,而不会影响性能。
此外,与随机初始化相比,作者设计了一个基于元学习的 Query 初始化方法,以在最小成本的情况下增强了初始化 Query 之间的相关性,从而提高了训练效果。作者还开发了一种双向自适应采样方法,允许更有效地利用与尺度相关的信息,并促进了从Backbone特征图中全局整合特征的过程,这也在后续的局部阶段中使用。
在局部细化阶段,作者设计了一种基于 Query 引导的特征增强方法,旨在更好地增强基于区域的特征。此外,作者设计了一种增强的损失策略,有助于实现更好的模型优化,这在之前的全局阶段中也是有效的。通过全面应用这两种创新技术,作者能够在只进行一次局部细化过程的情况下实现令人满意的检测结果。
将所有上述改进纳入考虑,作者成功将模型的解码器阶段减少到只有两个:一个全局阶段和一个局部阶段。这种减少在计算成本和推断准确性之间取得了良好的平衡。在COCO数据集上的广泛实验验证了作者提出的方法的有效性。
2、Query 设计范式
目前,解释和初始化 Query 的基于 Query 的目标检测器主要有3种设计范式,如图1所示。
普通目标 Query
第一种范式是通过对随机初始化的 Query 应用一系列操作后,从最终输出的 Query 中解码目标分类和边界框,类似于原始的DETR架构。
分离 Query
第二种范式将 Query 的内容向量和空间向量分开,同时优化它们,然后使用它们分别解码目标的分类和边界框。虽然这种设计减少了优化难度并提高了模型性能,但其空间向量的初始化通常独立于图像,并需要多次迭代才能接近地面真值。存在一些方法试图从密集特征中选择初始 Query (或空间向量),但它们要么引入了手工设计的组件,要么需要更大的计算资源。
本文的方法
与前两种范式相比,作者为 Query 提供了一种不同的设计。作者首先使用全局阶段使 Query 能够区分前景和背景,并估计大致的目标边界框。然后,作者允许 Query 使用局部阶段完成基于区域的详细分类和回归。这种方法有助于实现更好的训练收敛性,并与传统的两阶段目标检测范式相一致。
3、提出的方法
作者提出的模型GOLO遵循基于 Query 的范式,但试图只使用两个解码器阶段,一个全局阶段和一个局部阶段,以实现可比较的性能。
3.1、总体流程
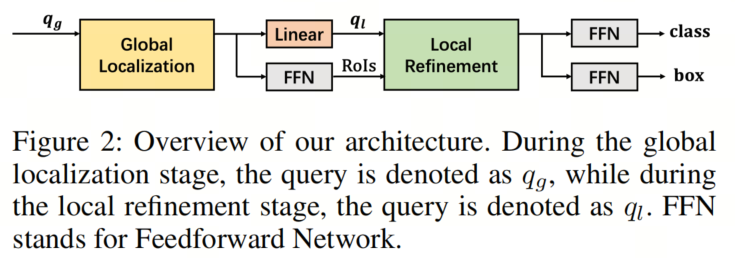
如图2所示,作者的模型完全以基于 Query 的方式运行。它由两个主要阶段组成:全局目标定位和局部特征引导细化。
-
在第一阶段中,执行全局目标定位以生成一组候选感兴趣区域(RoIs),这有助于避免由于 Query 初始化的随机性而需要级联解码器。 -
在第二阶段中,利用RoIs获取局部独特特征,用于细化最终的分类和边界框回归。
3.2、全局定位
详细的主要结构

该阶段包括以下主要组件:交叉注意力、自注意力、点状特征采样和混合。所有这些组件都在图3中进行了说明。交叉注意力和自注意力采用了多头注意力机制。为了便于点状特征采样和混合,作者首先使用作者提出的双向自适应采样方法来获取加权特征。稍后将提供有关该方法的全面介绍。然后,作者执行自适应通道混合和自适应空间混合,与原始论文保持一致的参数设置。
有必要详细解释作者的交叉注意力是如何实现的,因为它使每个 Query 能够感知图像的全局信息并定位其自己对应的RoI。作者利用目标 Query Q以及来自图像的特征K和V,其中K和V来自前述的多尺度特征融合。交叉注意力操作可以表示如下:

其中Q是由n个不同目标 Query 组成的矩阵, 是目标 Query 的总数。 和 是从多尺度特征融合输出进行线性变换得到的。线性变换应用于 的最后一个维度,得到一个变量 。然后分离 的最后一个维度,并将分离变量的第一和第二维度展平,分别得到 和 ,其形状与 相同。
在交叉注意力之后,下一步是自注意力,它有助于在 Query 之间交换信息。这个机制使每个 Query 能够识别最合适的匹配并做出明智的分类决策。交叉注意力和自注意力机制的结合为 Query 提供了定位和分类所需的信息,使其能够更有效地关注输入的相关区域。
为了进一步增强 Query 提取和表示信息的能力,在该阶段的最后一步作者执行了一轮点状特征采样和混合。这允许每个 Query 从整个图像中提取特征并将其与自己的特征融合,提高了定位和前景/背景区分的准确性。
基于元学习的 Query 初始化
作者假设目标 Query 应该隐含地包含有关目标的基本条件的组合,比如它们的基本视觉特征(例如颜色、形状、大小、方向等)。这些独特的组合因不同 Query 而异,负责区分不同的目标。
基于上述考虑,作者提出引入一组代表前述基本特征的"元"向量。通过这样做,可以将目标 Query 表示为这些"元"向量的线性组合。
具体来说,作者引入了一组维度为 的可学习"元"向量,它们表示目标的基本视觉特征。作者默认设置 , 。这些"元"向量被线性组合成目标 Query 。更正式地,假设 表示目标 Query ,作者可以将每个 Query 表示为 个"元"向量 的线性组合:

其中 是分配给第 个 Query 的第 个"元"向量的权重。在训练过程中,"元"向量 和权重 都是可学习的。实验证明,这种初始化可以在训练过程中改善目标特征的表示,并导致更好的模型性能。
多尺度特征融合
作者使用这个模块来从Backbone网络中汇集不同尺度的特征,用于对图像进行粗略的全局目标定位。作者使用ResNet架构作为Backbone网络,从输入图像生成多尺度的特征图。作者在模型中包括P2-P5 Level,每个Level的分辨率是前一个Level的一半,由256个通道组成。所有特征图都进行通道变换,以与最小特征图相同的大小生成全局特征图,其大小为 ,其中 和 是最小特征图的高度和宽度, 是通道数,通常为256, 表示在特征图上的相同位置输出的Kernel数量,默认设置为64。详细过程如图4所示。
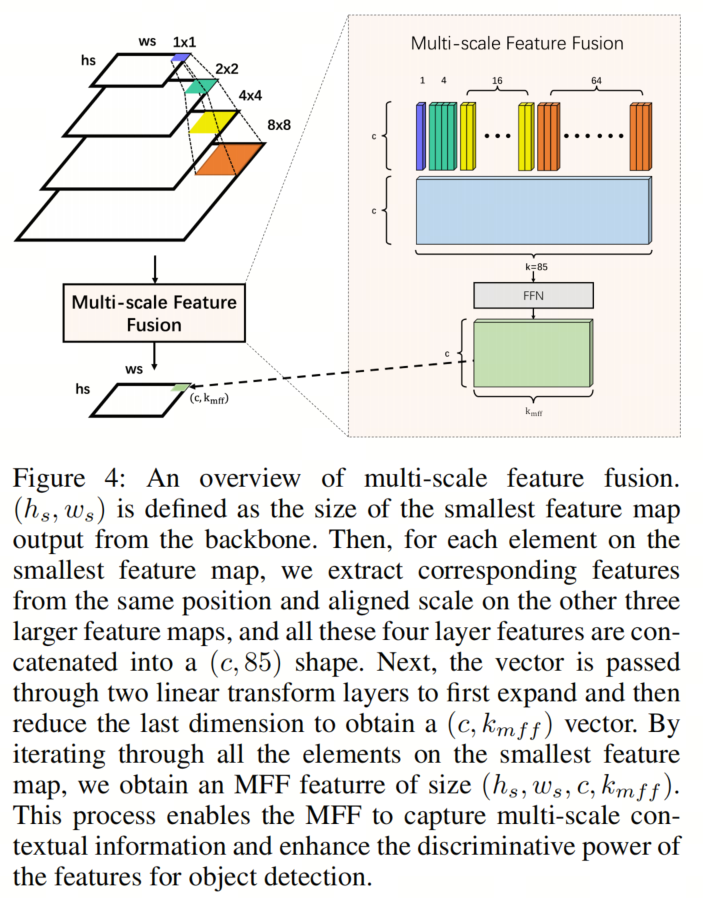
请注意,作者的方法与Featurized Query R-CNN或DINO中提出的方法不同。在那些工作中,他们尝试基于从特征图中选择的特征定义规则。然后使用这些选定的特征使用某些初始化技术初始化 Query 。此过程涉及到多个手动设计的组件,例如阈值选择或前k点选择。
相反,作者的方法旨在通过上述方法直接全局感知整个图像特征。随后,通过在全局阶段的训练, Query 可以自动区分前景区域。整个过程不涉及任何手动组件。考虑到基于 Query 的检测器的一个主要优势是其设计的简单性以及它们在实际应用中带来的稳健性,作者认为作者的设计更符合发展趋势。
双向自适应采样
在全局或局部阶段的自注意力之后,作者根据 Query 自身的特征对Backbone特征图执行自适应特征采样,然后融合采样的特征以增强 Query 。融合过程使用了自适应通道混合和自适应空间混合。但是考虑到采样方法,它可能不太适用于具有显着宽高比差异的目标。在这种情况下,需要考虑一种更合理的多尺度特征采样方法。
假设目标的边界框具有宽度和高度 。在不好的情况下, 和 的尺度可能会显著不同,比如 ≫ 。在这种情况下,应该选择 和 方向上不同尺度的特征。因此,作者提出了双向自适应采样,以根据 Query 生成的双向尺度信息对Backbone特征图上的特征进行采样。
具体来说,作者将特征图的 轴坐标表示为 ,其中 是第 个特征图的下采样步幅。设 是 Query 的线性变换 ,
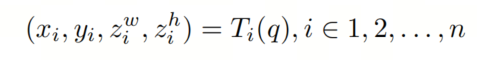
和 是 Query 要采样的点的平面坐标, 和 分别是它们在 和 方向上的 轴方向的坐标, 是要采样的点的数量。然后,作者的加权采样可以表示如下:

是特征图的总数。 是通过标准差为2的高斯函数计算的分配给第 个特征图的权重:
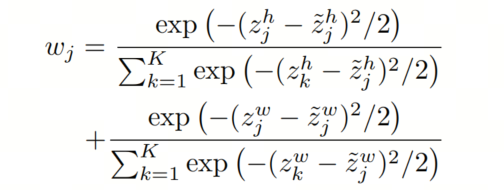
是第 个特征图中点 处的特征值, 是加权采样的特征。通过使用这种双向自适应采样方法,作者断言获得的采样特征更适合 Query 。
3.3、局部细化
详细结构
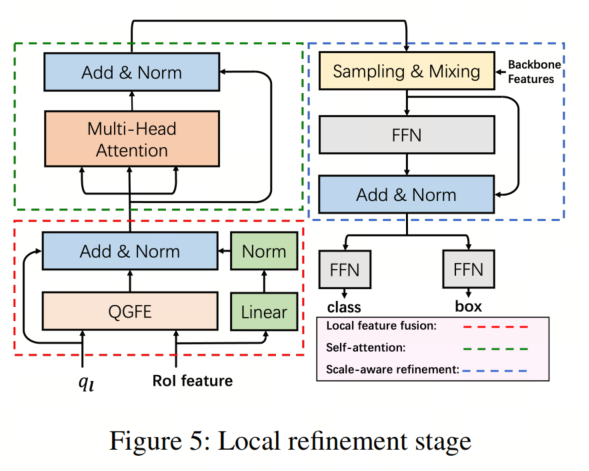
局部细化阶段也包括三个阶段:Query 引导的特征增强(QGFE),自注意力和逐点特征采样和混合,如图5所示。在第一个阶段中,从上一个阶段获得的RoI框B用于从Backbone特征中提取每个RoI内的图像特征。作者使用RoIAlign来完成这一步。然后,将提取的特征与来自上一个阶段的目标 Query 交互和融合,以将RoI特征合并到 Query 中。
在特征融合之后,与全局定位阶段类似,局部细化阶段中的 Query 经历自注意力机制以交换信息,主要目的是提高分类性能。然后,进行一轮逐点特征采样和混合,以加强 Query 中包含的信息。最后,使用分类Head和框Head分别获得每个 Query 的分类和边界框回归结果。Head设置与Faster R-CNN相同。
Query 引导的特征增强
形式上,对于给定的 Query ,其来自RoIAlign的相应特征被表示为fi,具有维度 ,让 是关于 的 Query 引导的特征增强,

其中在算法1中详细说明了QGFE的计算过程,考虑了 Query 和其RoI特征的一对。它根据 Query 的信息自适应增强了ROI特征。让 是将 进行两次线性变换的结果,其中包括层归一化和ReLU激活:
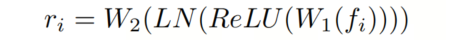
其中 和 是两次线性变换,LN表示层归一化,ReLU表示修正线性单元。区域融合的 Query 通过逐元素相加 , 和 获得,即


4、损失增强策略
作者的模型在全局和局部阶段均采用匹配损失进行训练监督,定义为:
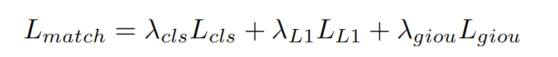
其中 , 和 分别表示分类损失,L1回归损失和GIoU损失。超参数 , 和 控制它们的相对重要性。
作者还在两个阶段中都使用辅助损失, 和 ,用于目标定位和分类。在每个阶段中考虑了三个步骤:与图像特征的交叉注意力(或特征融合),没有图像交互的自注意力以及具有采样的尺度感知细化。重要的是要注意,第二步自注意力不依赖于图像特征的交互,这意味着 Query 在第一步之后应该已经具备了定位目标所需的信息。
此外,自注意力的主要目的是让 Query 相互交流,确定最佳匹配并为每个 Query 做出分类决策,而不是目标定位。
受此启发,作者在两个阶段中的第一步和第二步分别引入了辅助边界框损失和分类损失,用于目标定位和分类。这些损失的真实值由每个阶段中的最终匹配关系确定,确保了一致的定位和分类。这种方法不仅加快了训练过程中的收敛速度,还将性能提高了0.2 AP。
总损失L是匹配损失和辅助损失的线性组合:
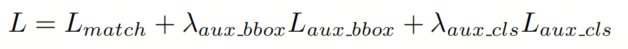
1、SOTA实验

作者提出的GOLO与其他传统或基于 Query 的模型的性能比较如表1所示。为了确保公平比较,作者对解码器阶段的数量设置了限制,最多允许两个阶段。这个限制在各种模型中都一致地应用。在Faster R-CNN中,这两个阶段由RPN和Faster RCNN表示。同样,在Sparse RCNN和Adamixer中,作者明确将迭代解码器阶段的数量设置为两个。在作者的模型GOLO中,解码器包括一个全局定位阶段和一个局部细化阶段。
作者的实验结果表明,作者提出的模型在将解码器阶段数量限制为2时实现了42.8的高AP,这是最好的性能。这证明了作者的策略,即首先执行全局定位,然后进行局部细化,对于基于 Query 的目标检测器来说是有效的。
具体而言,GOLO比两阶段的Sparse R-CNN和Adamixer分别高出8.2 AP和2.3 AP。值得注意的是,使用ResNet-50Backbone,GOLO胜过了使用ResNet-101的经典Faster R-CNN。这些发现突显了作者的整体设计在具有有限解码器阶段的情况下的有效性,这正是作者工作的重点。
2、消融实验
在本节中,作者分析了GOLO中的关键创新。在所有实验中,作者使用ResNet-50作为Backbone网络,并训练模型36个Epoch。
Query 数量

作者研究了改变 Query 数量对GOLO性能的影响,以在计算成本和性能之间找到平衡。如表2所示,将 Query 数量从100增加到300导致AP增加了3.1,但进一步增加到500并没有导致显著改善。因此,作者采用300个 Query 作为默认配置。
基于元启发式 Query 初始化的影响
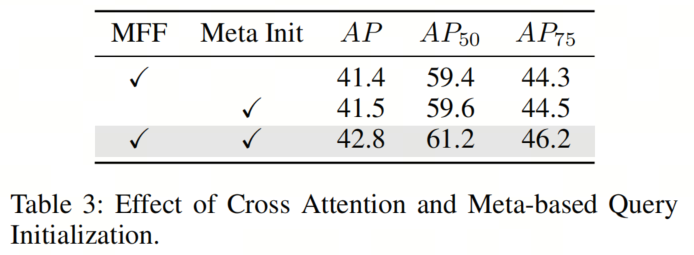
与以前的基于 Query 的检测器不同,GOLO使用一组“元”向量来初始化 Query 。作者在表3中研究了基于元的 Query 初始化的影响,发现引入“元”向量可以提高1.3个AP。
多尺度特征融合的影响
在全局定位阶段,作者对Backbone特征实施了多尺度融合机制。在进行自注意力之前,作者允许 Query 通过交叉注意力与融合特征进行交互,使每个 Query 能够感知全局图像特征并粗略定位其对应的RoI。如表3所示,这种设计可以提高1.4个AP。
双向自适应特征采样的影响
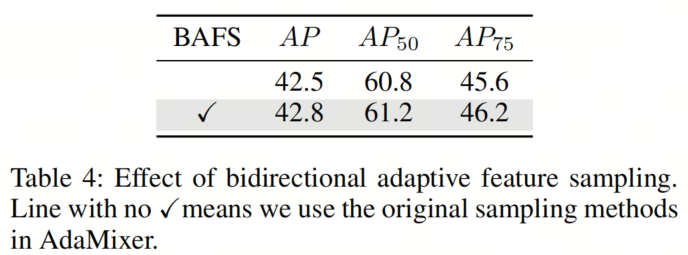
作者在全局定位和局部细化阶段均引入了双向自适应特征采样,认为这是一种更具尺度感知的采样方法。表4显示了0.3个AP的增加,证明了它的有效性。
特征采样和混合的综合效果

在这里,作者全面考察了自适应特征采样和随后的特征混合的综合效果。在完成之前,全局和局部两个阶段都使用了这个过程,如表5所示,共同提高了6.4个AP。
参考
[1]. Can the Query-based Object Detector Be Designed with Fewer Stages?.
推荐阅读
SA-UNet开源 | StyleGAN2与UNet的完美邂逅,成就更好的语义分割模型
即插即用 | Uni-Head这个学霸让ATSS/TOOD/RetinaNet/FreeAnchor通通涨点!!!

点击上方卡片,关注「AI视界引擎」公众号