
旷视YOLOX:更快更强!
本文转载自机器之心 编辑:杜伟、陈萍
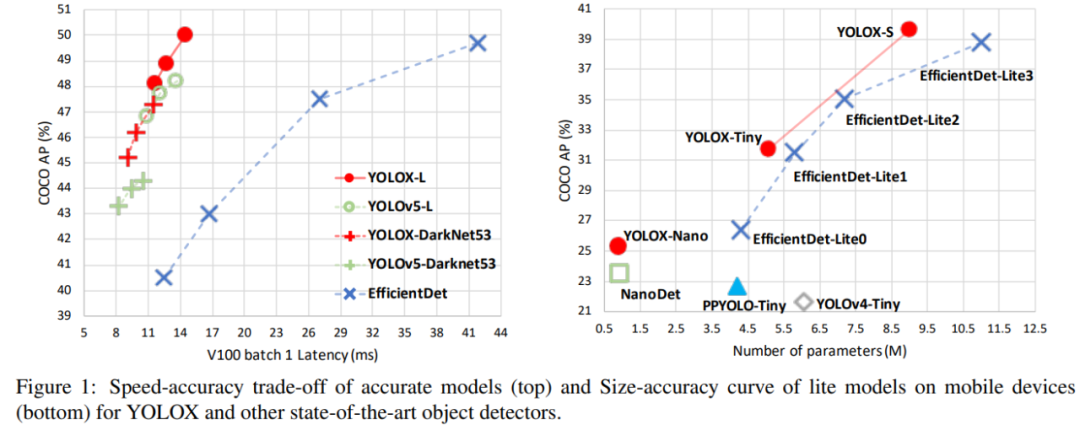
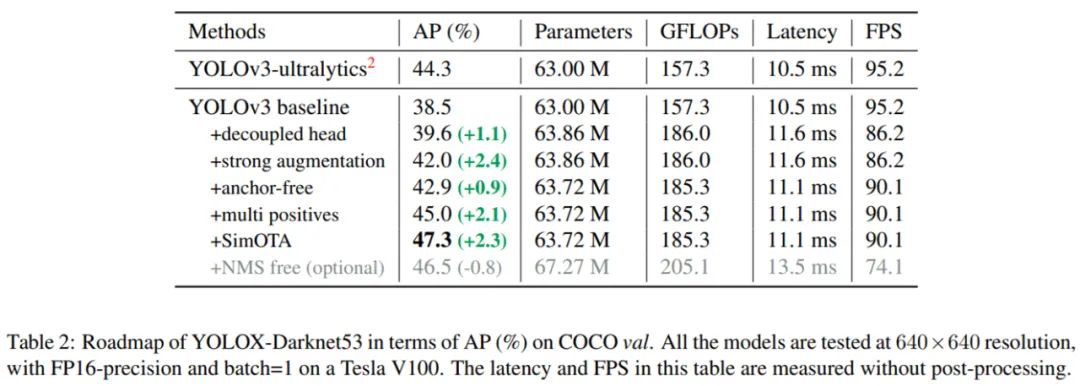
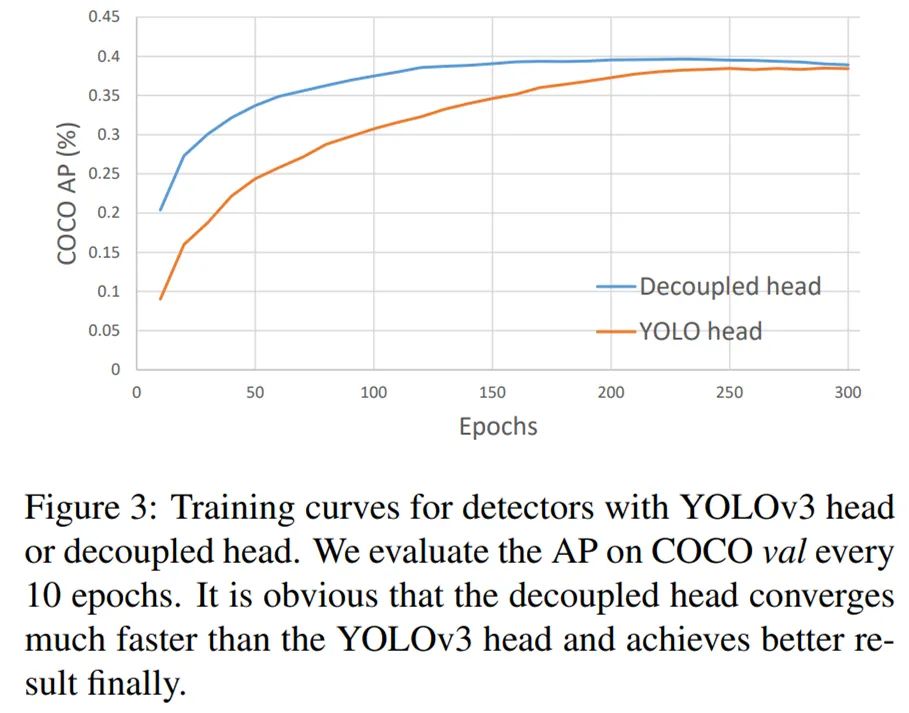
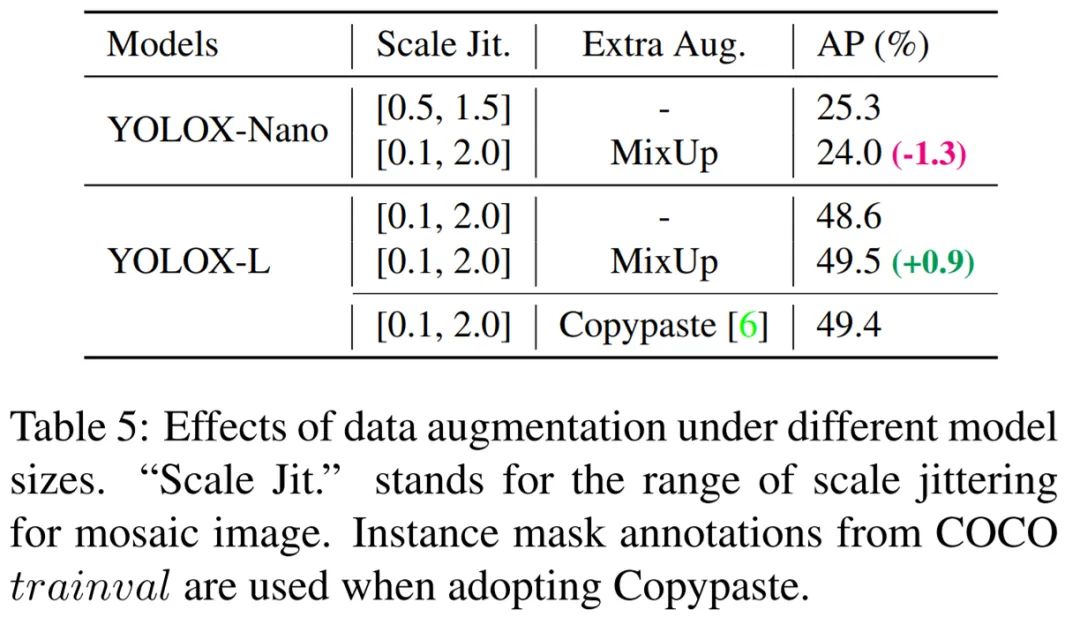
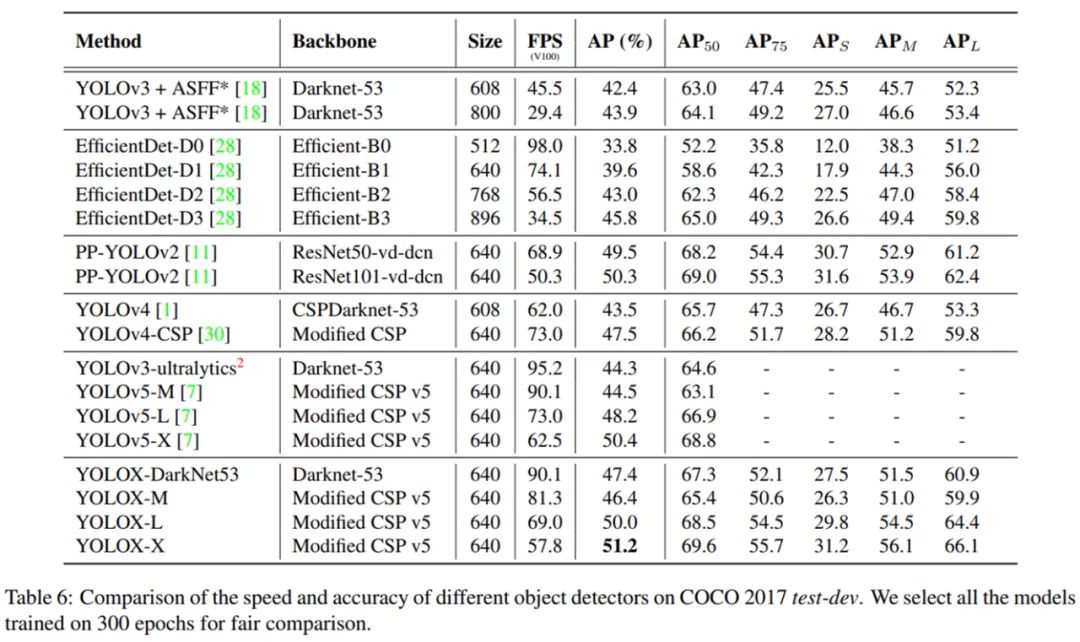
在本文中,来自旷视的研究者提出高性能检测器 YOLOX,并对 YOLO 系列进行了经验性改进,将 Anchor-free、数据增强等目标检测领域先进技术引入 YOLO。获得了超越 YOLOv3、YOLOv4 和 YOLOv5 的 AP,而且取得了极具竞争力的推理速度。

论文地址:https://arxiv.org/abs/2107.08430
项目地址:https://github.com/Megvii-BaseDetection/YOLOX





猜您喜欢:
CVPR 2021 | GAN的说话人驱动、3D人脸论文汇总
附下载 |《TensorFlow 2.0 深度学习算法实战》
附下载 | 超100篇!CVPR 2020最全GAN论文梳理汇总!
评论