
本周优秀开源项目分享,人员检测和跟踪、OCR工具库、汉字字符特征提取工具 等8大开源项目
Deep-SORT-YOLOv4 使用Tensorflow进行人员检测和跟踪
将YOLO v3替换成了YOLO v4,并添加了用于异步处理的选项,这大大提高了FPS。但是,使用异步处理时FPS监视将被禁用,因为它不准确。
从本文中提取了算法,并将其实现到deep_sort / track.py中。确认轨迹的原始方法仅基于检测到对象的次数而不考虑检测置信度,从而在发生不可靠的检测时(即低置信度真阳性或高置信度假阳性)导致高跟踪误报率。
轨道过滤算法通过在确认轨道之前计算一组检测次数的平均检测置信度,从而大大降低了这一点。

请注意,此处使用的跟踪模型仅针对跟踪人员进行了训练,因此您需要自己训练模型以跟踪其他对象。
项目环境:
Tensorflow GPU 1.14
Keras 2.3.1
opencv-python 4.2.0
imutils 0.5.3
numpy 1.18.2
sklearn
项目地址:
https://github.com/LeonLok/Deep-SORT-YOLOv4
PytorchOCR 基于Pytorch的OCR工具库
PytorchOCR旨在打造一套训练,推理,部署一体的OCR引擎库。支持常用的文字检测和识别算法。

crnn训练与python版预测
DB训练与python版预测
imagenet预训练模型
环境配置:
pytorch 1.4+
torchvision 0.5+
gcc 4.9+ (pse,pan会用到)
在ICDAR2015文本检测公开数据集上,算法效果如下:

项目地址:
https://github.com/WenmuZhou/PytorchOC
PixelLib 图像和视频分割库


Pixellib是用于对图像和视频进行分割的库。它支持两种主要类型的图像分割:
语义分割
实例分割
您可以用几行代码实现语义和实例分割。
有两种类型的Deeplabv3 +模型可用于通过PixelLib执行语义分割:
使用Xception作为网络主干的Deeplabv3 +模型在Ade20k数据集上训练,该数据集包含150类对象。
使用Xception作为网络主干的Deeplabv3 +模型在Pascalvoc数据集上训练,该数据集包含20类对象。
通过在可数据集上训练的Mask R-CNN模型,使用PixelLib实现实例分割。
项目地址:
https://github.com/ayoolaolafenwa/PixelLib
TextGenerator是一个用来生成ocr数据,文字检测数据,字体识别的最方便的工具。
实现功能:
生成基于不同语料的,不同字体、字号、颜色、旋转角度的文字贴图;
支持多进程快速生成;
文字贴图按照指定的布局模式填充到布局块中;
在图像中寻找平滑区域当作布局块;
支持文字区域的图块抠取导出(导出json文件,txt文件和图片文件,可生成voc数据,ICDAR_LSVT数据集格式!);
支持每个文字级别的标注(存入了lsvt的json文件中);
支持用户自己配置各项生成配(图像读取,生成路径,各种概率);

项目地址:
https://github.com/BboyHanat/TextGenerator
char_featurizer 汉字字符特征提取工具
char_featurizer 是一个汉字字符特征提取工具,他可以提取汉字的字音(包括声母、韵母、声调)、字形(偏旁、部首)、四角符号等信息。
同时可以将这些特征信息转换为tensor,作为模型的输入特征。这个项目是在安德森大佬的 字符提取工具 的基础上做了优化整合。
目前 char_featurizer 支持的功能有:
字形特征提取
字音特征提取
四角编码提取
tensor转换

项目地址:
https://github.com/charlesXu86/char_featurizer
yolov3-keras-tf2 yoloV3 V4在keras和Tensorflow 2.2中的实现
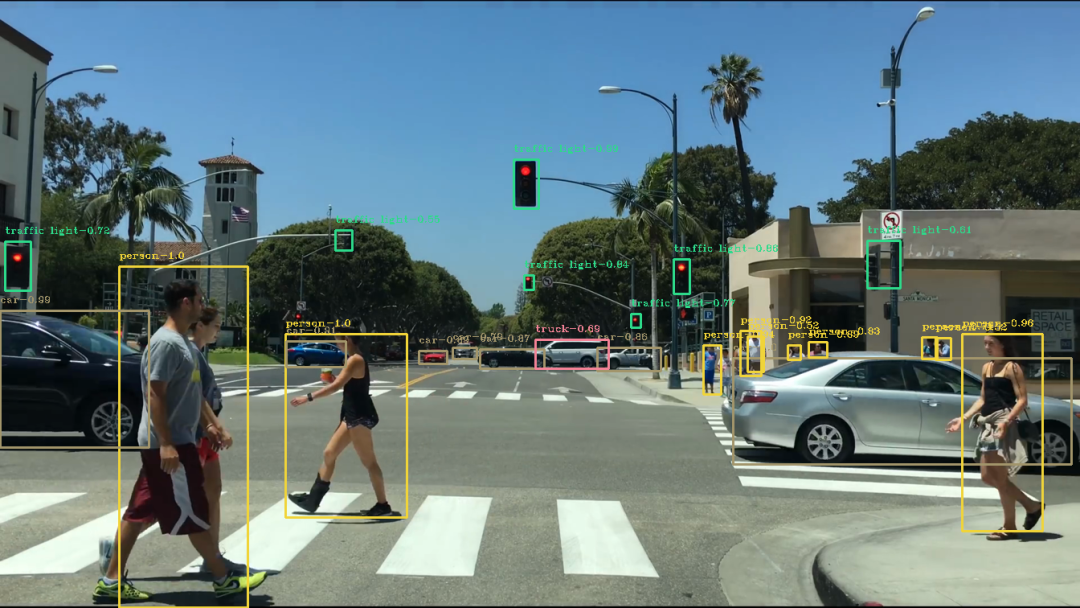
yolov3-keras-tf2最初是yolov3的实现(训练和推论),并添加了YoloV4支持(2020年6月6日)。
它是最新的实时对象检测系统非常快速且准确。有许多支持tensorflow的实现,只有少数支持tensorflow v2,并且由于找不到适合需求的版本,因此决定创建此版本,该版本非常灵活且可自定义。
它要求Python解释器版本3.6、3.7、3.7+不是特定于平台的,并且是MIT许可的,这意味着您可以随意使用,复制,修改,分发该软件。
特点:
直接从.cfg文件加载的DarkNet模型
YoloV4支持
Tensorflow 2.2和keras api
CPU和GPU支持
随机权重和DarkNet权重支持
项目地址:
https://github.com/emadboctorx/yolov3-keras-tf2
TransformerTTS 基于非自回归Transformer的神经网络的文本到语音的实现

基于非自回归变压器的文本到语音(TTS)神经网络的实现。项目基于以下论文:
Neural Speech Synthesis with Transformer Network
FastSpeech: Fast, Robust and Controllable Text to Speech
我们的预训练LJSpeech模型与来自以下方面的预训练声码器兼容:
WaveRNN
MelGAN
由于是非自回归的,因此该Transformer模型为:
鲁棒性:对于挑战性句子,没有重复和注意力模式失败。
快速:没有自回归,预测只需花费一小部分时间。
可控制的:可以控制所产生话语的速度。
项目地址:
https://github.com/as-ideas/TransformerTTS