
哪个更好:一个通用模型还是多个专用模型?
大数据文摘
共 11120字,需浏览 23分钟
· 2023-01-29
 大数据文摘授权转载自数据派THU
作者:Samuele Mazzanti
翻译:欧阳锦
校对:赵茹萱
大数据文摘授权转载自数据派THU
作者:Samuele Mazzanti
翻译:欧阳锦
校对:赵茹萱
我最近听到一家公司宣称:“我们在生产中有60个流失模型。”(注:流失模型是一种通过数学来建模流失对业务的影响。)我问他们为什么这么多。他们回答说,他们拥有 5 个品牌,在 12 个国家/地区运营,并且由于他们想为每个品牌和国家/地区的组合开发一种模型,因此共计 60 种模型。于是,我问他们:“你试过只用一种模型吗?”
他们认为这没有意义,因为他们的品牌彼此之间非常不同,他们经营的目标国家也是如此:“你不能训练一个单一的模型并期望它对品牌 A 的美国客户和对品牌 B 的德国客户”。
由于在业内经常听到这样的说法,我很好奇这个论点是否反映在数据中,或者只是没有事实支持的猜测。
这就是为什么在本文中,我将系统地比较两种方法:
- 将所有数据提供给一个模型,也就是一个通用模型(general model);
- 为每个细分市场构建一个模型(在前面的示例中,品牌和国家/地区的组合),也就是许多专业模型(specialized models)。
我将在流行的Python库Pycaret提供的12个真实数据集上测试这两种策略。
通用模型与专用模型
这两种方法究竟是如何工作的?
假设我们有一个数据集。数据集由预测变量矩阵(称为X)和目标变量(称为y)组成。此外,X包含一个或多个可用于分割数据集的列(在前面的示例中,这些列是“品牌”和“国家/地区”)。
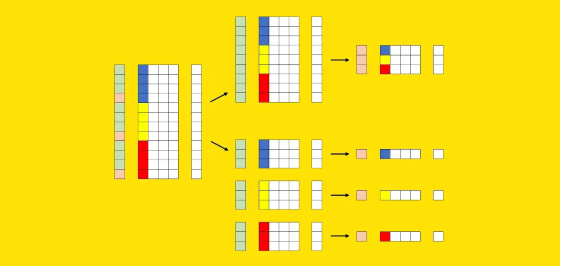
现在让我们尝试以图形方式表示这些元素。我们可以使用X的其中一列来可视化这些段:每种颜色(蓝色、黄色和红色)标识不同的段。我们还需要一个额外的向量来表示训练集(绿色)和测试集(粉色)的划分。

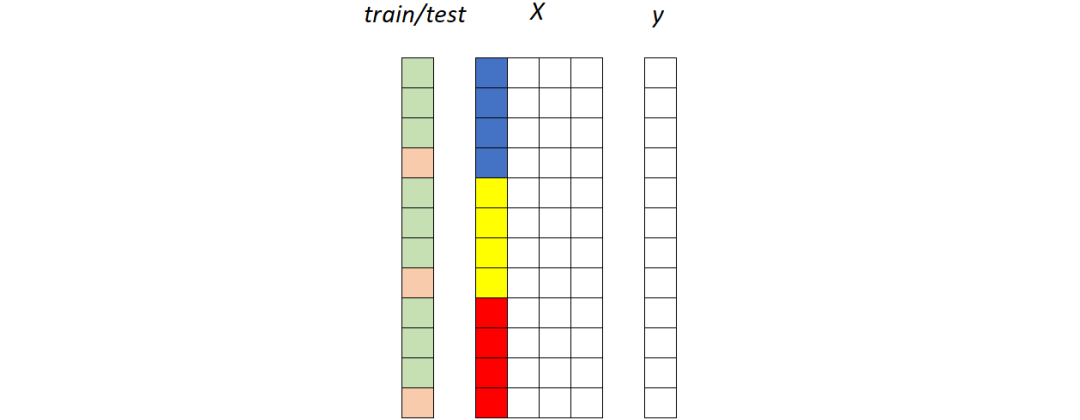 训练集的行标记为绿色,而测试集的行标记为粉红色。X 的彩色列是分段列:每种颜色标识不同的分段(例如,蓝色是美国,黄色是英国,红色是德国)。图源作者。
训练集的行标记为绿色,而测试集的行标记为粉红色。X 的彩色列是分段列:每种颜色标识不同的分段(例如,蓝色是美国,黄色是英国,红色是德国)。图源作者。
鉴于这些要素,以下是这两种方法的不同之处。
第一种策略:通用模型
在整个训练集上拟合一个独特的模型,然后在整个测试集上测量其性能:
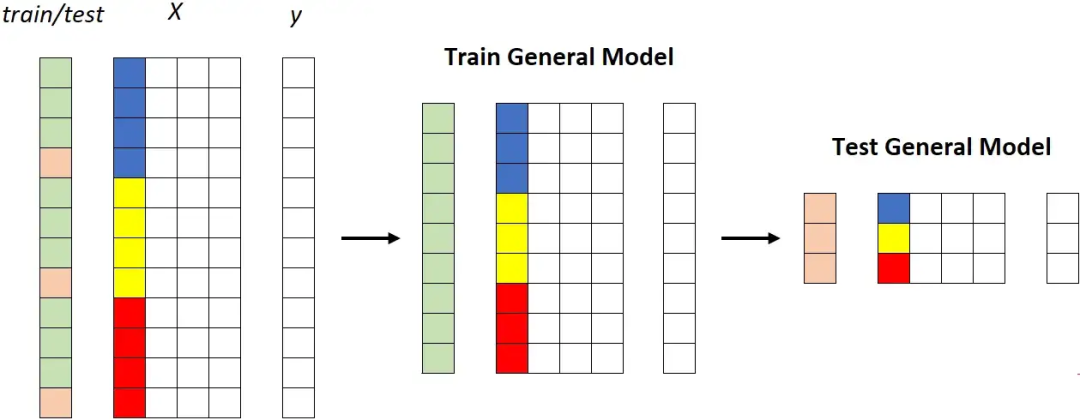 通用模型。所有片段(蓝色、黄色和红色)都被馈送到同一个模型。图源作者
通用模型。所有片段(蓝色、黄色和红色)都被馈送到同一个模型。图源作者
第二个策略:专业模型
第二种策略涉及为每个段建立模型,这意味着重复训练/测试过程k次(其中k是片段数,在本例中为 3)。
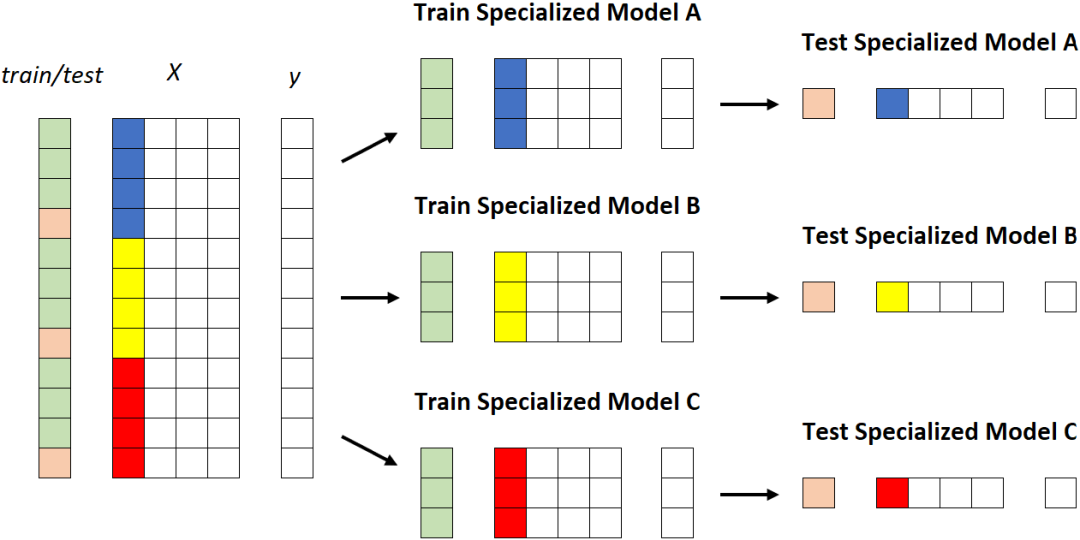 专用模型。每个段被馈送到不同的模型。[作者图片]
专用模型。每个段被馈送到不同的模型。[作者图片]
请注意,在实际用例中,分段的数量可能是相关的,从几十个到数百个不等。因此,与使用一个通用模型相比,使用专用模型存在几个实际缺点,例如:
- 更高的维护工作量;
- 更高的系统复杂度;
- 更高的(累积的)培训时间;
- 更高的计算成本:
- 更高的存储成本。
那么,为什么会有人想要这样做呢?
对通用模型的偏见
专用模型的支持者声称,独特的通用模型在给定的细分市场(比如美国客户)上可能不太精确,因为它还了解了不同细分市场(例如欧洲客户)的特征。
我认为这是因使用简单模型(例如逻辑回归)而产生的错误认识。让我用一个例子来解释。
假设我们有一个汽车数据集,由三列组成:
- 汽车类型(经典或现代);
- 汽车时代;
- 车价。
我们想使用前两个特征来预测汽车价格。这些是数据点:
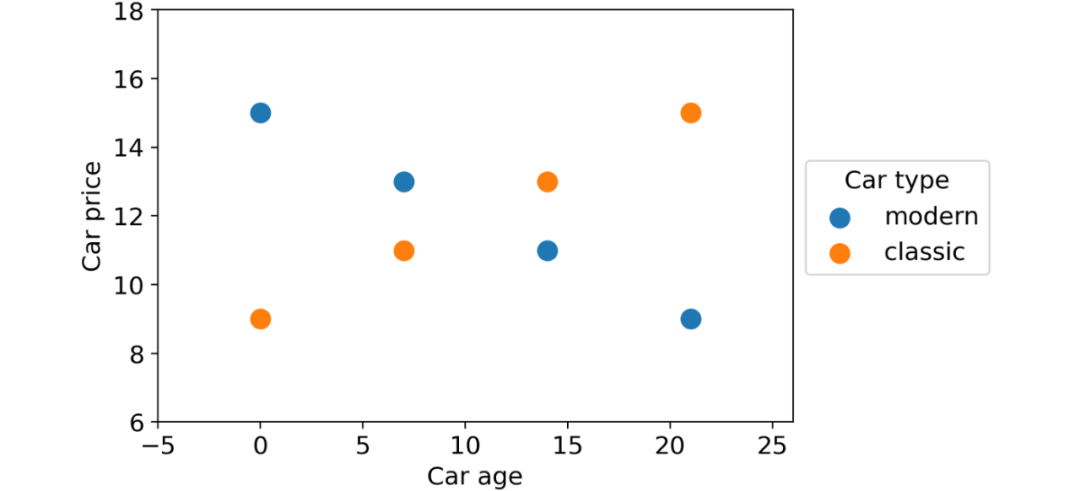 具有两个部分(经典汽车和现代汽车)的数据集,显示出与目标变量相关的非常不同的行为。图源作者
具有两个部分(经典汽车和现代汽车)的数据集,显示出与目标变量相关的非常不同的行为。图源作者
如您所见,根据汽车类型,有两种完全不同的行为:随着时间的推移,现代汽车贬值,而老爷车价格上涨。
现在,如果我们在完整数据集上训练线性回归:
linear_regression = LinearRegression().fit(df[[ "car_type_classic" , "car_age" ]], df[ "car_price" ]
得到的系数是:
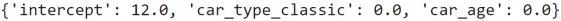 在数据集上训练的线性回归系数。图源作者
在数据集上训练的线性回归系数。图源作者
这意味着模型将始终为任何输入预测相同的值12。
通常,如果数据集包含不同的行为(除非您进行额外的特征工程),简单模型将无法正常工作。因此,在这种情况下,人们可能会想训练两种专门的模型:一种用于经典汽车,一种用于现代汽车。
但是让我们看看如果我们使用决策树而不是线性回归会发生什么。为了使比较公平,我们将生成一棵有3个分支的树(即3个决策阈值),因为线性回归也有3个参数(3个系数)。
decision_tree = DecisionTreeRegressor(max_depth= 2 ).fit(df[
[ "car_type_classic" , "car_age" ]], df[ "car_price" ])
这是结果:
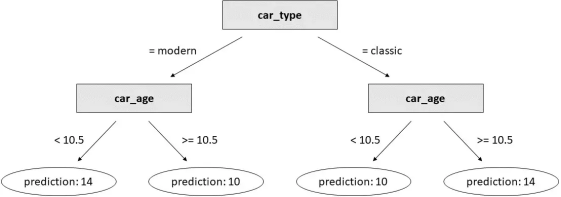 在玩具数据集上训练的决策树。[作者图片]
在玩具数据集上训练的决策树。[作者图片]
这比我们用线性回归得到的结果要好得多!
关键是基于树的模型(例如 XGBoost、LightGBM 或 Catboost)能够处理不同的行为,因为它们天生就可以很好地处理特征交互。
这就是为什么在理论上没有理由比一个通用模型更喜欢几个专用模型的主要原因。但是,一如既往,我们并不满足于理论解释。我们还想确保这一猜想得到真实数据的支持。
实验细节
在本段中,我们将看到测试哪种策略效果更好所需的 Python 代码。如果您对细节不感兴趣,可以直接跳到下一段,我将在这里讨论结果。
我们的目标是定量比较两种策略:
- 训练一个通用模型;
- 训练许多个专用模型。
比较它们的最明显方法如下:
1. 获取数据集; 2. 根据一列的值选择数据集的一部分; 3. 将数据集拆分为训练数据集和测试数据集; 4. 在整个训练数据集上训练通用模型; 5. 在属于该段的训练数据集部分上训练专用模型; 6. 比较通用模型和专用模型在属于该段的测试数据集部分上的性能。
图形化:
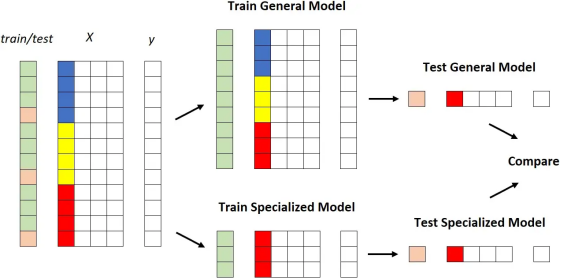 X 中的彩色列是我们用来对数据集进行分层的列。[作者图片]
X 中的彩色列是我们用来对数据集进行分层的列。[作者图片]
这工作得很好,但是,由于我们不想被随机性愚弄,我们将重复这个过程:
- 对于不同的数据集;
- 使用不同的列来分割数据集本身;
- 使用同一列的不同值来定义段。
换句话说,这就是我们要用伪代码做的:
for each dataset:
train general model on the training set
for each column of the dataset:
for each value of the column:
train specialized model on the portion of the training set for which column = value
compare performance of general model vs. specialized model
实际上,我们需要对这个过程做一些微小的调整。
首先,我们说过我们正在使用数据集的列来分割数据集本身。这适用于分类列和具有很少值的离散数字列。对于剩余的数字列,我们必须通过分箱(binning)使它们分类。
其次,我们不能简单地使用所有的列。如果我们这样做,我们将会惩罚专用模型。事实上,如果我们根据与目标变量无关的列选择细分,就没有理由相信专门的模型可以表现得更好。为避免这种情况,我们将只使用与目标变量有某种关系的列。
此外,出于类似的原因,我们不会使用所有细分列的值。我们将避免过于频繁(超过50%)的值,因为期望在大多数数据集上训练的模型与在完整数据集上训练的模型具有不同的性能是没有意义的。我们还将避免测试集中少于100个案例的值,因为结果肯定不会很重要。
鉴于此,这是我使用的完整代码:
for dataset_name in tqdm(dataset_names):
# get data
y, num_features, cat_features, n_classes = get_dataset(dataset_name)
# split index in training and test set, then train general model on the training set
ix_test = train_test_split(X.index, test_size=.25, stratify=y)
model_general = CatBoostClassifier().fit(X=X.loc[ix_train,:], y=y.loc[ix_train], cat_features=cat_features, silent=True)
pred_general = pd.DataFrame(model_general.predict_proba(X.loc[ix_test, :]), index=ix_test, columns=model_general.classes_)
# create a dataframe where all the columns are categorical:
# numerical columns with more than 5 unique values are binnized
X_cat = X.copy()
:, num_features] = X_cat.loc[:, num_features].fillna(X_cat.loc[:, num_features].median()).apply(lambda col: col if col.nunique() <= 5 else binnize(col))
# get a list of columns that are not (statistically) independent
# from y according to chi 2 independence test
candidate_columns = get_dependent_columns(X_cat, y)
for segmentation_column in candidate_columns:
# get a list of candidate values such that each candidate:
# - has at least 100 examples in the test set
# - is not more common than 50%
vc_test = X_cat.loc[ix_test, segmentation_column].value_counts()
nu_train = y.loc[ix_train].groupby(X_cat.loc[ix_train, segmentation_column]).nunique()
nu_test = y.loc[ix_test].groupby(X_cat.loc[ix_test, segmentation_column]).nunique()
candidate_values = vc_test[(vc_test>=100) & (vc_test/len(ix_test)<.5) & (nu_train==n_classes) & (nu_test==n_classes)].index.to_list()
for value in candidate_values:
# split index in training and test set, then train specialized model
# on the portion of the training set that belongs to the segment
ix_value = X_cat.loc[X_cat.loc[:, segmentation_column] == value, segmentation_column].index
ix_train_specialized = list(set(ix_value).intersection(ix_train))
ix_test_specialized = list(set(ix_value).intersection(ix_test))
model_specialized = CatBoostClassifier().fit(X=X.loc[ix_train_specialized,:], y=y.loc[ix_train_specialized], cat_features=cat_features, silent=True)
pred_specialized = pd.DataFrame(model_specialized.predict_proba(X.loc[ix_test_specialized, :]), index=ix_test_specialized, columns=model_specialized.classes_)
# compute roc score of both the general model and the specialized model and save them
roc_auc_score_general = get_roc_auc_score(y.loc[ix_test_specialized], pred_general.loc[ix_test_specialized, :])
roc_auc_score_specialized = get_roc_auc_score(y.loc[ix_test_specialized], pred_specialized)
= results.append(pd.Series(data=[dataset_name, segmentation_column, value, len(ix_test_specialized), y.loc[ix_test_specialized].value_counts().to_list(), roc_auc_score_general, roc_auc_score_specialized],index=results.columns),ignore_index=True
为了便于理解,我省略了一些实用函数的代码,get_dataset例如get_dependent_columns和get_roc_auc_score。但是,您可以在此GitHub存储库中找到完整代码。
结果
为了对通用模型与专用模型进行大规模比较,我使用了Pycaret(MIT许可下的 Python库)中提供的12个真实世界数据集。
对于每个数据集,我发现列与目标变量显示出一些显着关系(独立性卡方检验的p值<1%)。对于任何一列,我只保留不太罕见(它们必须在测试集中至少有100个案例)或过于频繁(它们必须占数据集的比例不超过50%)的值。这些值中的每一个都标识数据集的一个片段。
对于每个数据集,我在整个训练数据集上训练了一个通用模型(CatBoost,没有参数调整)。然后,对于每个片段,我在属于相应片段的训练数据集部分上训练了一个专门的模型(同样是CatBoost,没有参数调整)。最后,我比较了两种方法在属于该段的测试数据集部分上的性能(ROC曲线下的面积)。
让我们看一下最终输出:
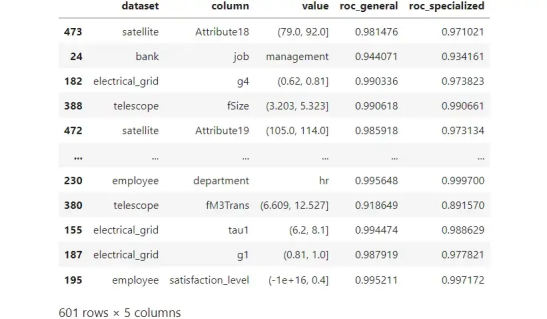 12 个真实数据集的模拟结果。每行都是一个段,由数据集、列和值的组合标识。图源作者。
12 个真实数据集的模拟结果。每行都是一个段,由数据集、列和值的组合标识。图源作者。
原则上,要选出获胜者,我们可以只看“roc_general”和“roc_specialized”之间的区别。然而,在某些情况下,这种差异可能是偶然的。因此,我也计算了差异何时具有统计显着性(有关如何判断两个ROC分数之间的差异是否显着的详细信息,请参阅本文)。
因此,我们可以在两个维度上对601比较进行分类:通用模型是否优于专用模型以及这种差异是否显着。这是结果:
 601 比较的总结。“general > specialized”表示通用模型的ROC曲线下面积高于专用模型,“specialized > general”则相反。“显着”/“不显着”表明这种差异是否显着。图源作者。
601 比较的总结。“general > specialized”表示通用模型的ROC曲线下面积高于专用模型,“specialized > general”则相反。“显着”/“不显着”表明这种差异是否显着。图源作者。
很容易看出,通用模型在89%的时间(454+83/601)优于专用模型。但是,如果我们坚持重要的案例,一般模型在95%的时间(87个中的83个)优于专用模型。
出于好奇,我们也将87个重要案例可视化为一个图表,x轴为专用模型的ROC分数,y轴为通用模型的ROC分数。
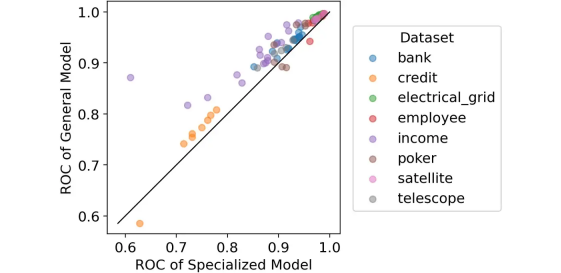 比较:专用模型的 ROC 与通用模型的 ROC。仅包括显示出显着差异的部分。图源作者。
比较:专用模型的 ROC 与通用模型的 ROC。仅包括显示出显着差异的部分。图源作者。
对角线上方的所有点都标识了通用模型比专用模型表现更好的情况。
但是,更好在哪里?
我们可以计算两个ROC分数之间的平均差。事实证明,在87个显着案例中,通用模型的 ROC 平均比专用模型高2.4%,这是很多!
结论
在本文中,我们比较了两种策略:使用在整个数据集上训练的通用模型与使用专门针对数据集不同部分的许多模型。
我们已经看到,没有令人信服的理由使用专用模型,因为强大的算法(例如基于树的模型)可以在本地处理不同的行为。此外,从维护工作、系统复杂性、训练时间、计算成本和存储成本的角度来看,使用专用模型涉及到几个实际的复杂问题。
我们还在12个真实数据集上测试了这两种策略,总共有601个可能的片段。在这个实验中,通用模型在89%的时间里优于专用模型。只看具有统计显着性的案例,这个数字上升到95%,ROC得分平均提高2.4%。
您可以在这个GitHub存储库中找到本文使用的所有Python代码。
原文标题: What Is Better: One General Model or Many Specialized Models? 原文链接:
https://towardsdatascience.com/what-is-better-one-general-model-or-many-specialized-models-9500d9f8751d
 点「在看」的人都变好看了哦!
点「在看」的人都变好看了哦!
评论
model-genGo 专用的模型生成器
model-gen 是一个Go专用的模型生成器。原理通过获取mysql表结构,进行model文件生成。迭代目前支持mysql,未来预计支持mariadb和pgsql(sqlserver还未考量)快速入
model-genGo 专用的模型生成器
0
BBT-2通用大语言模型
BBT-2是包含120亿参数的通用大语言模型,在BBT-2的基础上训练出了代码,金融,文生图等专业模型。基于BBT-2的系列模型包括:BBT-2-12B-Text:120亿参数的中文基础模型BBT-2
BBT-2通用大语言模型
0
StarSpace实体嵌入通用神经网络模型
StarSpace是用于高效学习实体嵌入(Entity embeddings)的通用神经模型,可解决各种各样的问题:学习单词、句子或文档级嵌入文本分类或其他标签任务信息检索:实体/文件或对象集合的排序
StarSpace实体嵌入通用神经网络模型
0