
三种大模型架构
Transformers构成了革命性的大语言模型的骨干。
虽然像GPT4、llama2和Falcon这样的LLM在各种任务上似乎表现出色,但LLM在某个特定任务上的性能是底层架构的直接结果。
有三种不同的Transformer架构变体为不同的LLM提供动力。
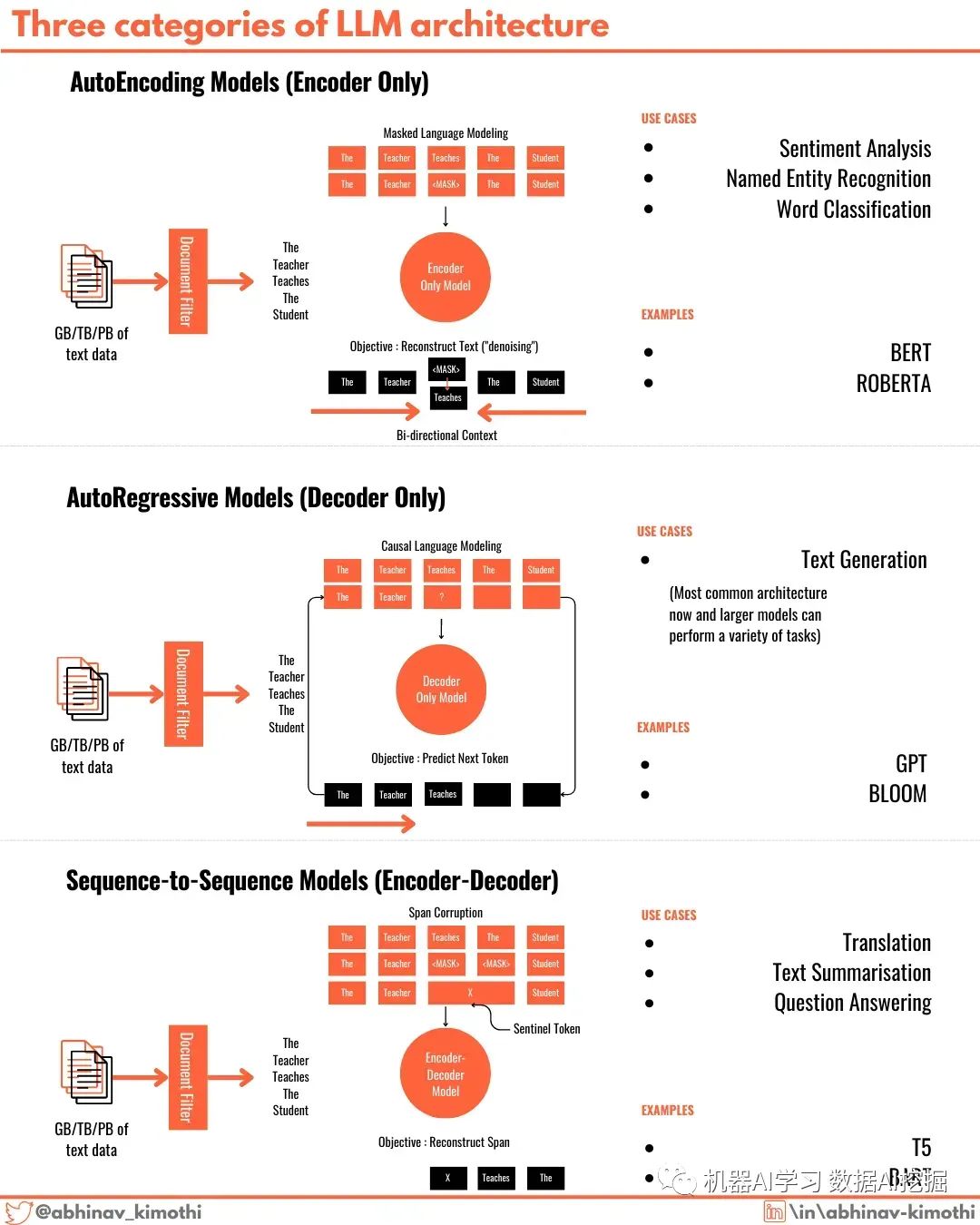
1️⃣ 自编码器(Autoencoders)- 在自编码器中,预训练后会丢弃Transformer的解码器部分,只使用编码器生成输出。广泛流行的BERT和RoBERTa模型就是基于这种架构构建的,并在情感分析和文本分类任务上表现良好。这些模型使用一种称为MLM或掩码语言建模的过程进行训练。
2️⃣ 自回归模型(Autoregressors)- 像GPT系列、bloom等现代LLM是自回归模型。在这种架构中,保留解码器部分,预训练后丢弃编码器部分。虽然文本生成是自回归模型最适用的场景,但它们在各种任务上表现出色。大多数现代LLM都是自回归模型。这些模型使用一种称为因果语言建模的过程进行训练。
3️⃣ 序列到序列模型(Sequence-to-Sequence)- Transformer模型的起源是序列到序列模型。这些模型同时具有编码器和解码器部分,并且可以通过多种方式进行训练。其中一种方法是跨度损坏和重建。这些模型最适合于语言翻译任务。T5和BART系列的模型就是序列到序列模型
推荐阅读:
评论