
从零开始编写LoRA代码,这里有一份教程
共 2856字,需浏览 6分钟
· 2024-04-12
Lora
转自:机器之心
作者表示:在各种有效的 LLM 微调方法中,LoRA 仍然是他的首选。
LoRA(Low-Rank Adaptation)作为一种用于微调 LLM(大语言模型)的流行技术,最初由来自微软的研究人员在论文《 LORA: LOW-RANK ADAPTATION OF LARGE LANGUAGE MODELS 》中提出。 不同于其他技术,LoRA 不是调整神经网络的所有参数,而是专注于更新一小部分低秩矩阵,从而大大减少了训练模型所需的计算量。
由于 LoRA 的微调质量与全模型微调相当,很多人将这种方法称之为微调神器。自发布以来,相信很多人都对这项技术感到好奇,想要从头开始编写代码从而更好的理解该研究。以前苦于没有合适的文档说明,现在,教程来了。
这篇教程的作者是知名机器学习与 AI 研究者 Sebastian Raschka,他表示在各种有效的 LLM 微调方法中,LoRA 仍然是自己的首选。为此,Sebastian 专门写了一篇博客《Code LoRA From Scratch》,从头开始构建 LoRA,在他看来,这是一种很好的学习方法。
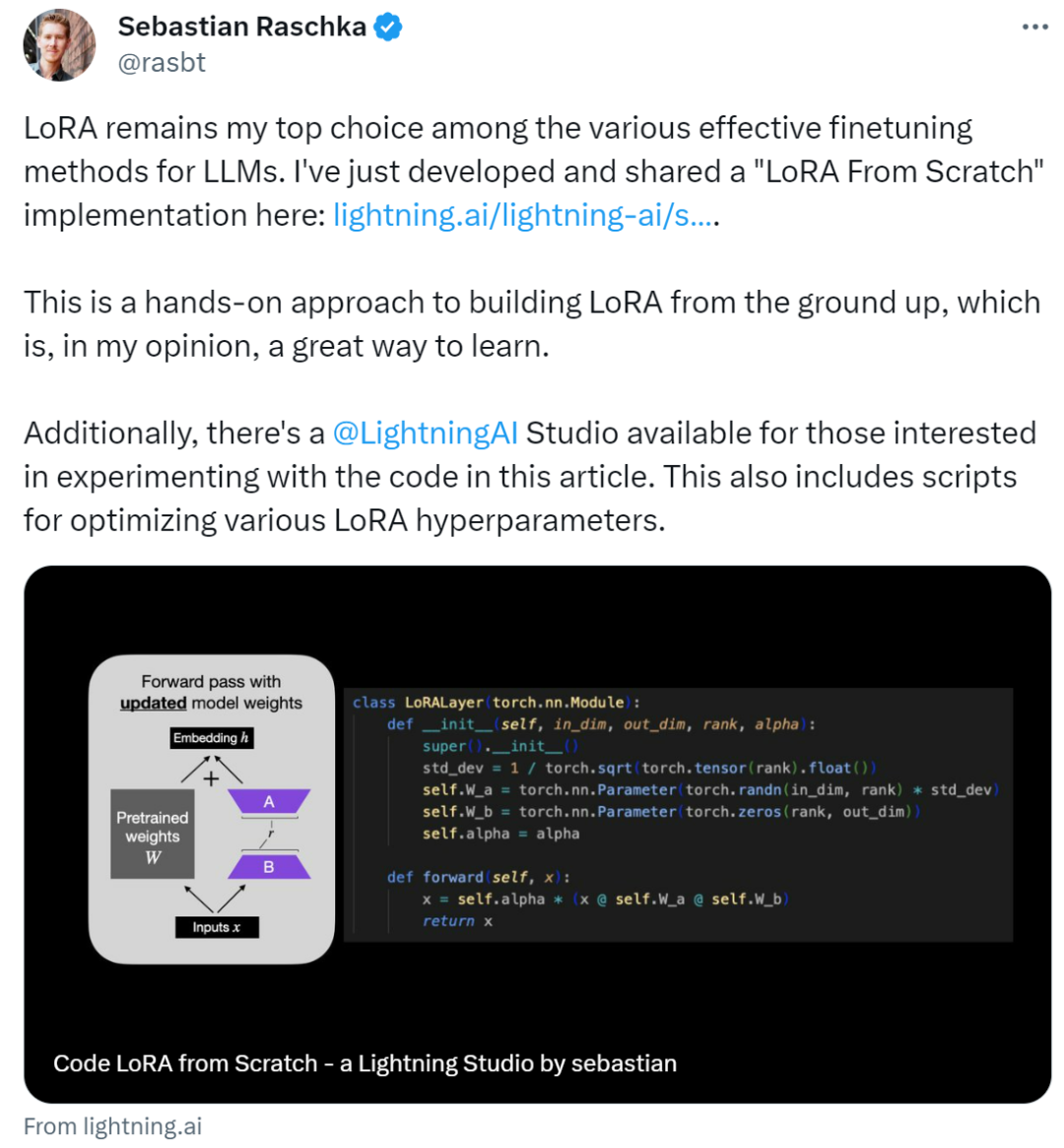
简单来说,本文通过从头编写代码的方式来介绍低秩自适应(LoRA),实验中 Sebastian 对 DistilBERT 模型进行了微调,并用于分类任务。
LoRA 与传统微调方法的对比结果显示,使用 LoRA 方法在测试准确率上达到了 92.39%,这与仅微调模型最后几层相比(86.22% 的测试准确率)显示了更好的性能。
Sebastian 是如何实现的,我们接着往下看。
从头开始编写 LoRA
用代码的方式表述一个 LoRA 层是这样的:
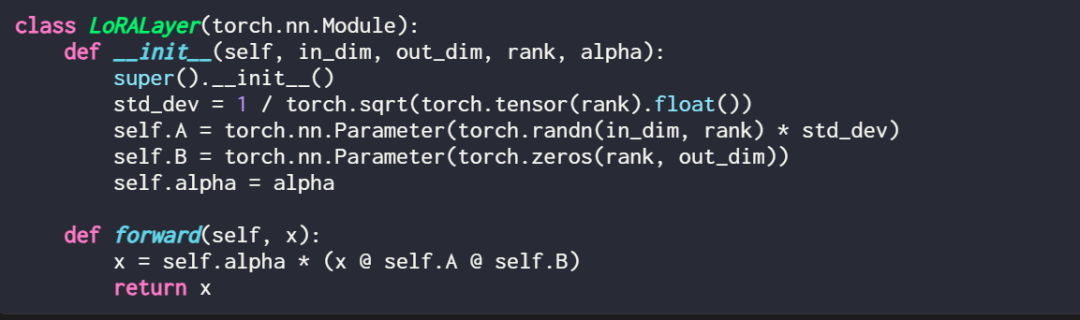
其中,in_dim 是想要使用 LoRA 修改的层的输入维度,与此对应的 out_dim 是层的输出维度。代码中还添加了一个超参数即缩放因子 alpha,alpha 值越高意味着对模型行为的调整越大,值越低则相反。此外,本文使用随机分布中的较小值来初始化矩阵 A,并用零初始化矩阵 B。
值得一提的是,LoRA 发挥作用的地方通常是神经网络的线性(前馈)层。举例来说,对于一个简单的 PyTorch 模型或具有两个线性层的模块(例如,这可能是 Transformer 块的前馈模块),其前馈(forward)方法可以表述为:

在使用 LoRA 时,通常会将 LoRA 更新添加到这些线性层的输出中,又得到代码如下:

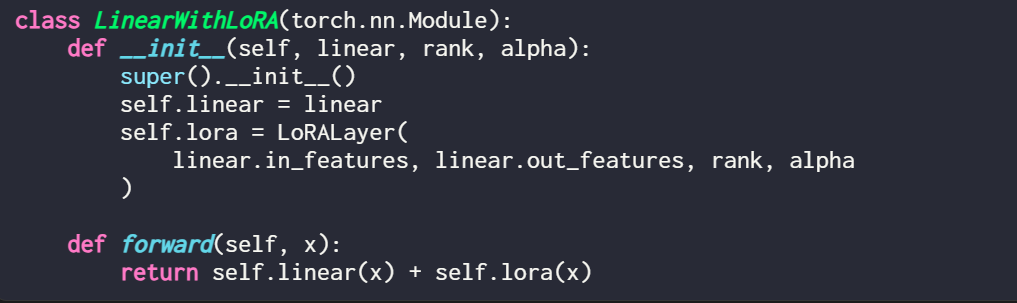
如果你想通过修改现有 PyTorch 模型来实现 LoRA ,一种简单方法是将每个线性层替换为 LinearWithLoRA 层:
以上这些概念总结如下图所示:
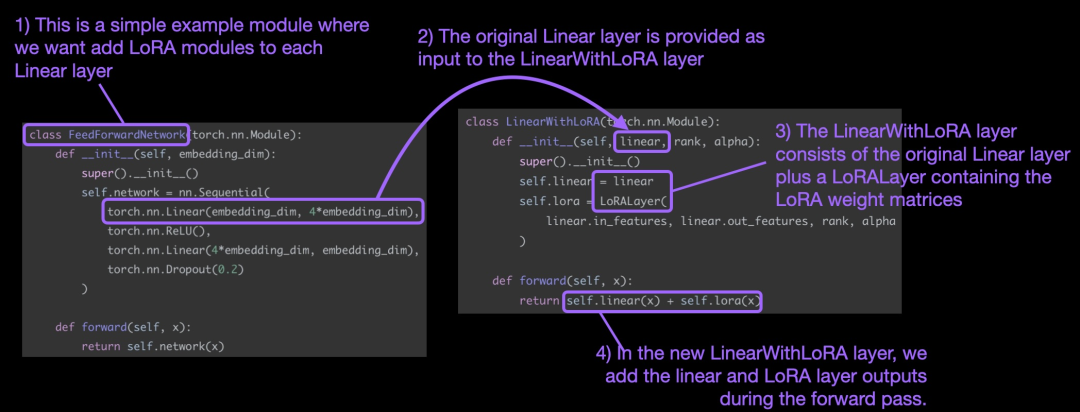
为了应用 LoRA,本文将神经网络中现有的线性层替换为结合了原始线性层和 LoRALayer 的 LinearWithLoRA 层。
如何上手使用 LoRA 进行微调
LoRA 可用于 GPT 或图像生成等模型。为了简单说明,本文采用一个用于文本分类的小型 BERT(DistilBERT) 模型来说明。

由于本文只训练新的 LoRA 权重,因而需要将所有可训练参数的 requires_grad 设置为 False 来冻结所有模型参数:

接下来,使用 print (model) 检查一下模型的结构:

由输出可知,该模型由 6 个 transformer 层组成,其中包含线性层:

此外,该模型有两个线性输出层:

通过定义以下赋值函数和循环,可以选择性地为这些线性层启用 LoRA:
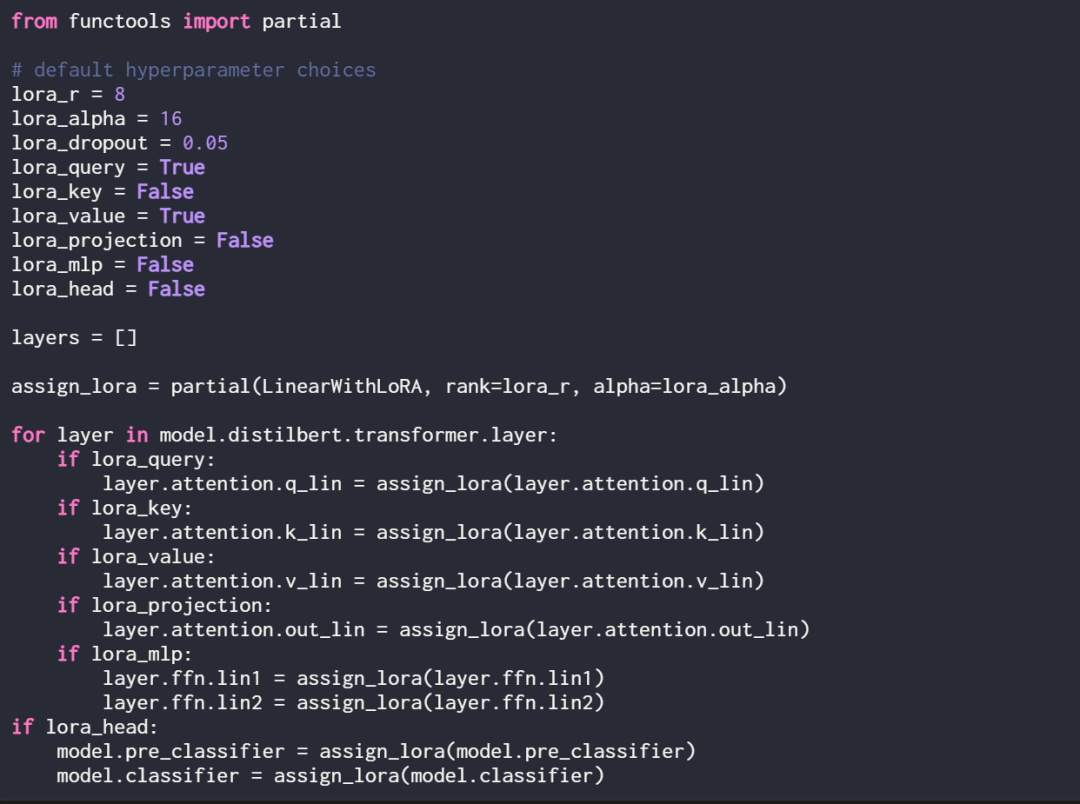
使用 print (model) 再次检查模型,以检查其更新的结构:
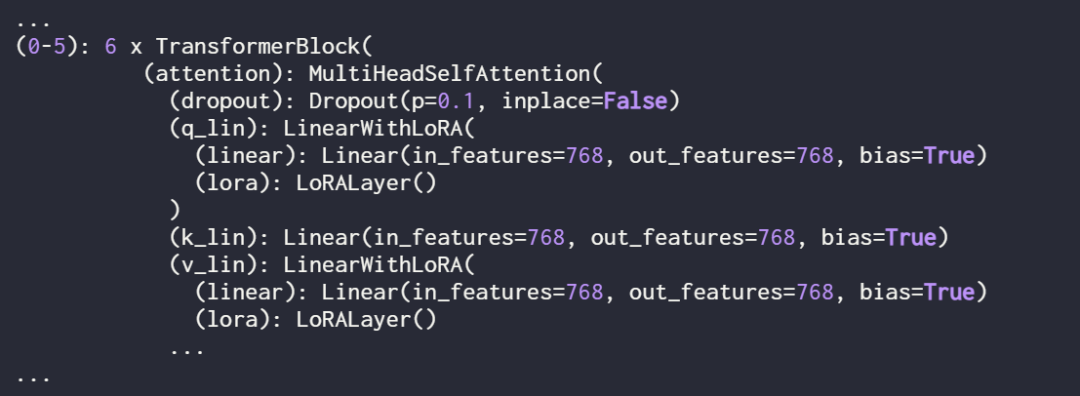
正如上面看到的,线性层已成功地被 LinearWithLoRA 层取代。
如果使用上面显示的默认超参数来训练模型,则会在 IMDb 电影评论分类数据集上产生以下性能:
-
训练准确率:92.15%
-
验证准确率:89.98%
-
测试准确率:89.44%
在下一节中,本文将这些 LoRA 微调结果与传统微调结果进行了比较。
与传统微调方法的比较
在上一节中,LoRA 在默认设置下获得了 89.44% 的测试准确率,这与传统的微调方法相比如何?
为了进行比较,本文又进行了一项实验,以训练 DistilBERT 模型为例,但在训练期间仅更新最后 2 层。研究者通过冻结所有模型权重,然后解冻两个线性输出层来实现这一点:
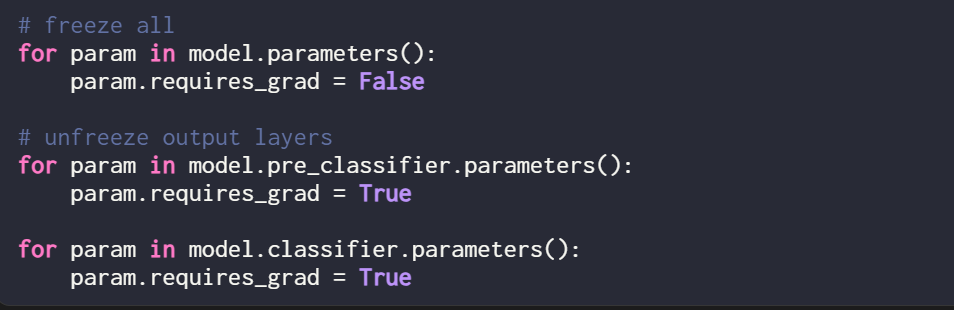
只训练最后两层得到的分类性能如下:
-
训练准确率:86.68%
-
验证准确率:87.26%
-
测试准确率:86.22%
结果显示,LoRA 的表现优于传统微调最后两层的方法,但它使用的参数却少了 4 倍。微调所有层需要更新的参数比 LoRA 设置多 450 倍,但测试准确率只提高了 2%。
优化 LoRA 配置
前面讲到的结果都是 LoRA 在默认设置下进行的,超参数如下:

假如用户想要尝试不同的超参数配置,可以使用如下命令:

不过,最佳超参数配置如下:

在这种配置下,得到结果:
-
验证准确率:92.96%
-
测试准确率:92.39%
值得注意的是,即使 LoRA 设置中只有一小部分可训练参数(500k VS 66M),但准确率还是略高于通过完全微调获得的准确率。
原文链接:https://lightning.ai/lightning-ai/studios/code-lora-from-scratch?continueFlag=f5fc72b1f6eeeaf74b648b2aa8aaf8b6
