
嵌入式开发常见问题解决方法
一、问题复现
1.1 模拟复现条件
1.2 提高相关任务执行频率
1.3 增大测试样本量
二、问题定位
2.1 打印LOG
2.2 在线调试
2.3 版本回退
2.4 二分注释
二分注释即以类似二分查找法的方式注释掉部分代码,以此判断问题是否由注释掉的这部分代码引起。2.5 保存内核寄存器快照
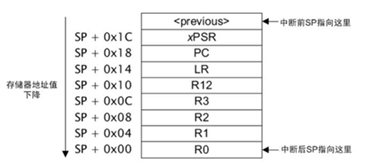
三、问题分析处理
3.1 程序继续运行
3.1.1 数值异常
3.1.1.1 软件问题
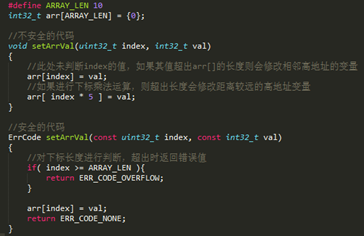
在设计阶段应该合理分配内存资源,为栈设置合适的大小;
将函数内较大的临时变量加”static”关键字转化为静态变量,或者使用malloc()动态分配,将其放到堆上;
改变函数调用方式,降低调用层数。


3.1.1.2 硬件问题

3.1.2 动作异常
3.1.2.1 软件问题
3.1.2.2 硬件问题
3.2 程序崩溃
3.2.1 停止运行
3.2.1.1 软件问题
在外设时钟门未使能的情况下操作该外设的寄存器;
跳转函数地址越界,通常发生在函数指针被篡改,排查方法同数值异常;
解引用指针时出现对齐问题:
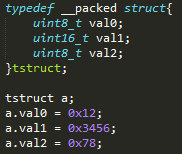
3.2.1.2 硬件问题
3.2 .2 复位
3.2.2.1 软件问题
3.2.2.2 硬件问题
四、回归测试
五、经验总结
来源地址: https://www.cnblogs.com/jozochen/p/8541714.html
声明:本文素材来源网络,版权归原作者所有。如涉及作品版权问题,请与我联系删除
评论