
Go:并发 IO 优化
1. 背景
有的时候我们会遇到并发 IO 的情况,例如,并发爬虫下载网络上的图片。如果并发度过高或者下载的内容过大,会导致网络 IO 耗时急剧上升。这时候就需要优化一下每次网络IO 的耗时。
2. 网络下载图片用例
以下载网络数据为例,下面是典型的代码。
func TestHttpGet(t *testing.T) {
rsp, err := http.Get("http://xxx.com")
if err != nil {
t.Errorf("get err:%v", err)
return
}
defer rsp.Body.Close()
body, err := ioutil.ReadAll(rsp.Body)
t.Logf("body len:%v, read err:%v", len(body), err)
}
在代码中,首先通过 http.Get 获取网络上的资源,这段耗时不容易在业务层面优化。因此想要优化整体耗时,只有从读取响应 rsp.Body 入手。
3. ioutil.ReadAll
3.1. 源码分析
ioutil.ReadAll 中其实是调用了 bytes.Buffer.ReadFrom 函数,buf 的初始容量是 bytes.MinRead = 512。
// readAll reads from r until an error or EOF and returns the data it read
// from the internal buffer allocated with a specified capacity.
func readAll(r io.Reader, capacity int64) (b []byte, err error) {
var buf bytes.Buffer
if int64(int(capacity)) == capacity {
buf.Grow(int(capacity))
}
_, err = buf.ReadFrom(r)
return buf.Bytes(), err
}
// ReadAll reads from r until an error or EOF and returns the data it read.
// A successful call returns err == nil, not err == EOF. Because ReadAll is
// defined to read from src until EOF, it does not treat an EOF from Read
// as an error to be reported.
func ReadAll(r io.Reader) ([]byte, error) {
return readAll(r, bytes.MinRead)
}
在 buf.ReadFrom(r) 中,首先将 b.buf 扩容 MinRead = 512 字节,然后从 r 中一轮一轮读取数据,直到 b.buf 填完。
// MinRead is the minimum slice size passed to a Read call by
// Buffer.ReadFrom. As long as the Buffer has at least MinRead bytes beyond
// what is required to hold the contents of r, ReadFrom will not grow the
// underlying buffer.
const MinRead = 512
// ReadFrom reads data from r until EOF and appends it to the buffer, growing
// the buffer as needed. The return value n is the number of bytes read. Any
// error except io.EOF encountered during the read is also returned. If the
// buffer becomes too large, ReadFrom will panic with ErrTooLarge.
func (b *Buffer) ReadFrom(r io.Reader) (n int64, err error) {
b.lastRead = opInvalid
for {
i := b.grow(MinRead)
b.buf = b.buf[:i]
m, e := r.Read(b.buf[i:cap(b.buf)])
if m < 0 {
panic(errNegativeRead)
}
b.buf = b.buf[:i+m]
n += int64(m)
if e == io.EOF {
return n, nil // e is EOF, so return nil explicitly
}
if e != nil {
return n, e
}
}
}
在 b.grow(n) 函数用来将 bytes.Buffer 扩容,以便容纳下 n 个 byte,如果 b 已经无法扩容了,则会产生一个 panic,携带 ErrTooLarge error。
bytes.Buffer 的定义如下:
// A Buffer is a variable-sized buffer of bytes with Read and Write methods.
// The zero value for Buffer is an empty buffer ready to use.
type Buffer struct {
buf []byte // contents are the bytes buf[off : len(buf)]
off int // read at &buf[off], write at &buf[len(buf)]
lastRead readOp // last read operation, so that Unread* can work correctly.
}
b.grow(n) 函数的逻辑为:
如果
b.buf的长度 len + n 小于等于b.buf的容量:cap(b.buf)。则直接返回长度 len。如果
b.buf = nil并且n < 64时,则会新建一个长度为n,容量为 64 的[]byte 数组并返回。如果
b.buf的长度len + n小于等于b.buf一半容量:cap(b.buf)/2,就把b.buf[b.offset:]部分的数据移到b.buf开头,b.offset是 bytes.Buffer 开始读的位置,这样就是把b.buf中可用的数据向前移到开头。如果
b.buf的长度len + n大于b.buf一半容量:cap(b.buf)/2,则会调用makeSlice分配一个新的 []byte,长度为当前容量的二倍加n:cap(b.buf)*2+n,然后把原来的数据复制到新 buf 中:copy(buf, b.buf[b.off:])。
所以说,如果bytes.Buffer初始的 buf 容量不够大,而需要读取的数据太大的话,会频繁的进行内存分配,这是耗时增加的原因。
而在readall函数中,bytes.Buffer 的初始容量是 512 字节,之后会成倍增加直到满足数据大小。
3.2. 资源分配分析
为了避免网络 IO 测试对外产生的影响,使用磁盘 IO 来替代网络 IO,分析 ioutil.ReadAll 的内存分配。磁盘 IO 使用一个 72MB 的测试文件:test.data.rar。
写一个下面的单测代码:
func TestReadAll(t *testing.T) {
file, err := os.Open(testName)
if err != nil {
t.Errorf("open err:%v", err)
return
}
_, err = ioutil.ReadAll(file)
if err != nil {
t.Errorf("readall err:%v", err)
return
}
}
执行单元测试,并储存内存和cpu概要信息。
go test --run TestReadAll$ -v -memprofile readall.mem -memprofilerate 1 -cpuprofile readall.cpu
接下来使用 pprof 分析内存和cpu 的概要文件。
3.2.1. cpu 分析
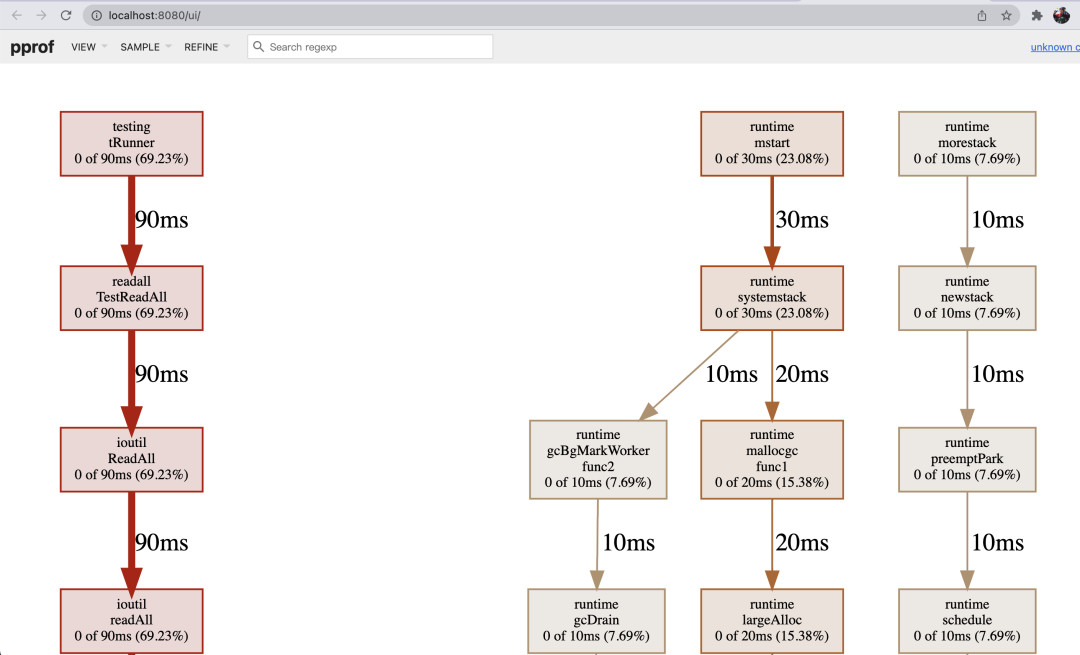
首先分析 cpu 概要文件。在 bash 中输入:
go tool pprof -http=:8080 readall.cpu
则会在打开一个页面,里面就是各个函数的耗时,例如,TestReadAll 就花了 90ms。
3.2.2. 内存分析
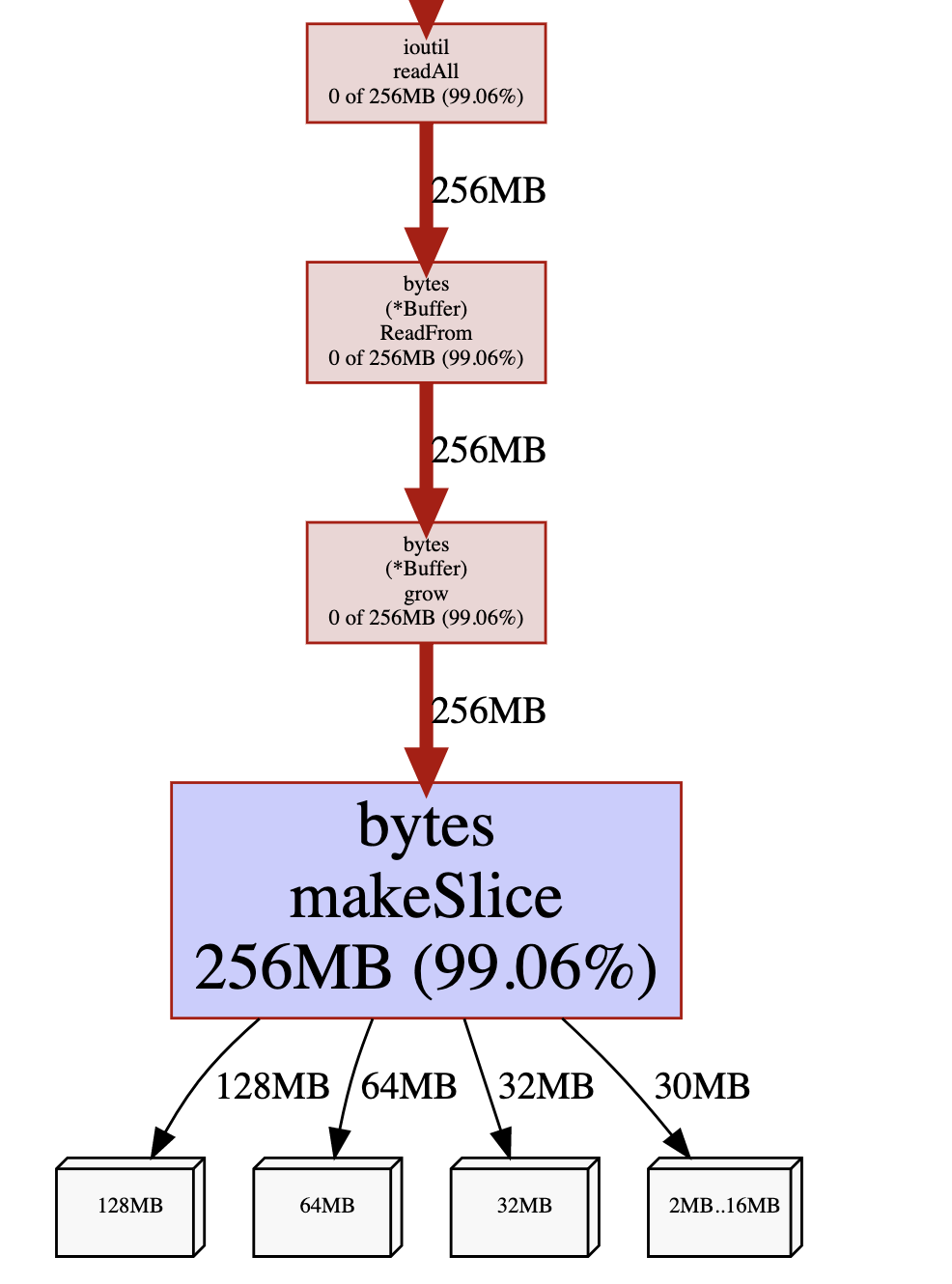
接下来是内存概要文件分析。在 bash 中输入:
go tool pprof -http=:8080 readall.mem
可以看到在 ioutil.ReadAll 进行了多次内存分配。这是因为在 ioutil.ReadAll 内部会多次调用 bytes.Buffer 的 Grow(n) 函数进行扩容,最后一次扩容产生了一个 128 MB 的切片。
128MB 正好是测试文件大小向上取整的512字节的整数倍。
4. io.Copy
前面说到,使用 ioutil.ReadAll 读取大文件时会出现频繁的内存分配,增加大量不必要的耗时。
那我们会想,可以直接避免内存频繁分配吗?反正内存也不会省,那我们在之前直接一次分配够了,之后就不会有额外的内存分配耗时了。
io.Copy 就可以实现这个功能。
4.1. 预分配文件大小内存
func TestIOCopy(t *testing.T) {
file, err := os.Open(testName)
if err != nil {
t.Errorf("open err:%v", err)
return
}
data := make([]byte, 0, 74077894)
buf := bytes.NewBuffer(data)
_, err = io.Copy(buf, file)
if err != nil {
t.Errorf("readall err:%v", err)
return
}
}
在上面代码中,预分配文件大小的内存,然后调用 io.Copy复制数据。
在 io.Copy 函数中会直接调用 buf.ReadFrom 读取 file 中的数据。
// ReadFrom reads data from r until EOF and appends it to the buffer, growing
// the buffer as needed. The return value n is the number of bytes read. Any
// error except io.EOF encountered during the read is also returned. If the
// buffer becomes too large, ReadFrom will panic with ErrTooLarge.
func (b *Buffer) ReadFrom(r io.Reader) (n int64, err error) {
b.lastRead = opInvalid
for {
i := b.grow(MinRead)
b.buf = b.buf[:i]
m, e := r.Read(b.buf[i:cap(b.buf)])
if m < 0 {
panic(errNegativeRead)
}
b.buf = b.buf[:i+m]
n += int64(m)
if e == io.EOF {
return n, nil // e is EOF, so return nil explicitly
}
if e != nil {
return n, e
}
}
}
执行单测生成 cpu 和内存概要文件:
go test --run TestIOCopy -v -memprofile iocopy.mem -memprofilerate 1 -cpuprofile iocopy.cpu
分析 cpu 时间如下,可以看到只花了 40ms,比之前的 ioutil.ReadAll 低 50ms。但是还是调用了 buffer.grow 函数,说明在这个单测中还是存在额外的内存分配。
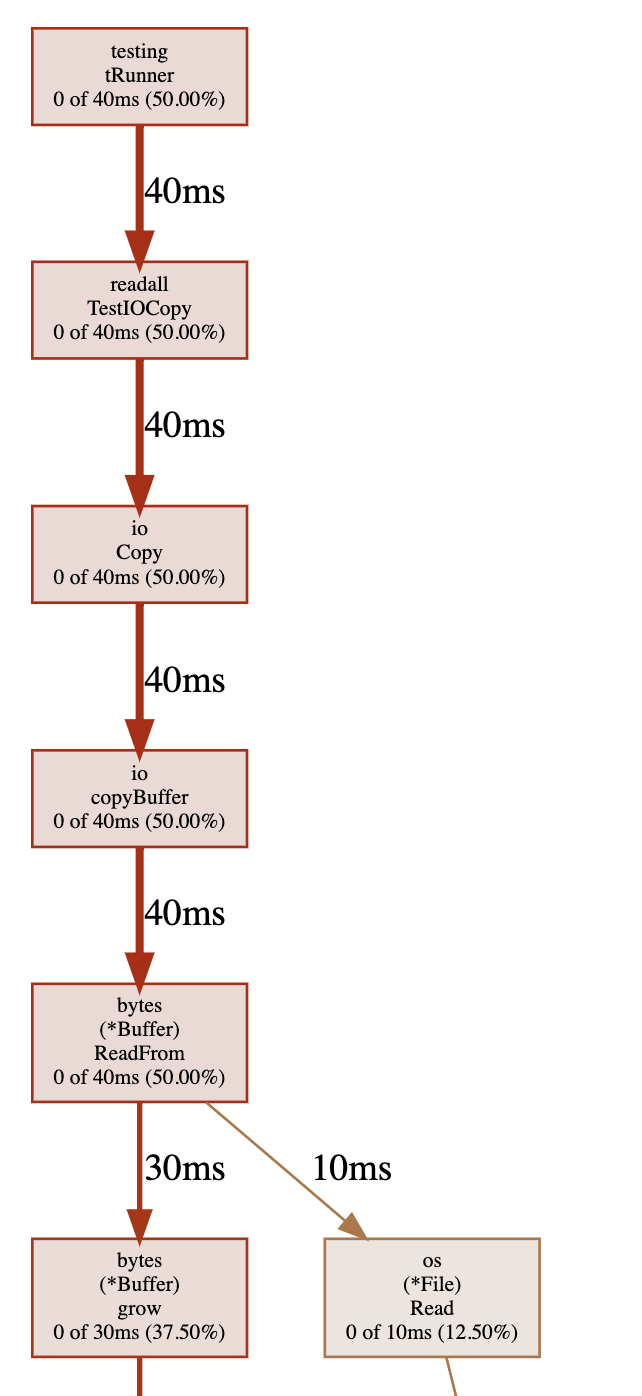
分析内存概要文件如下,可以发现的确有额外的内存分配,并且分配的内存是文件大小的两倍。这说明耗时还有进一步下降的空间。
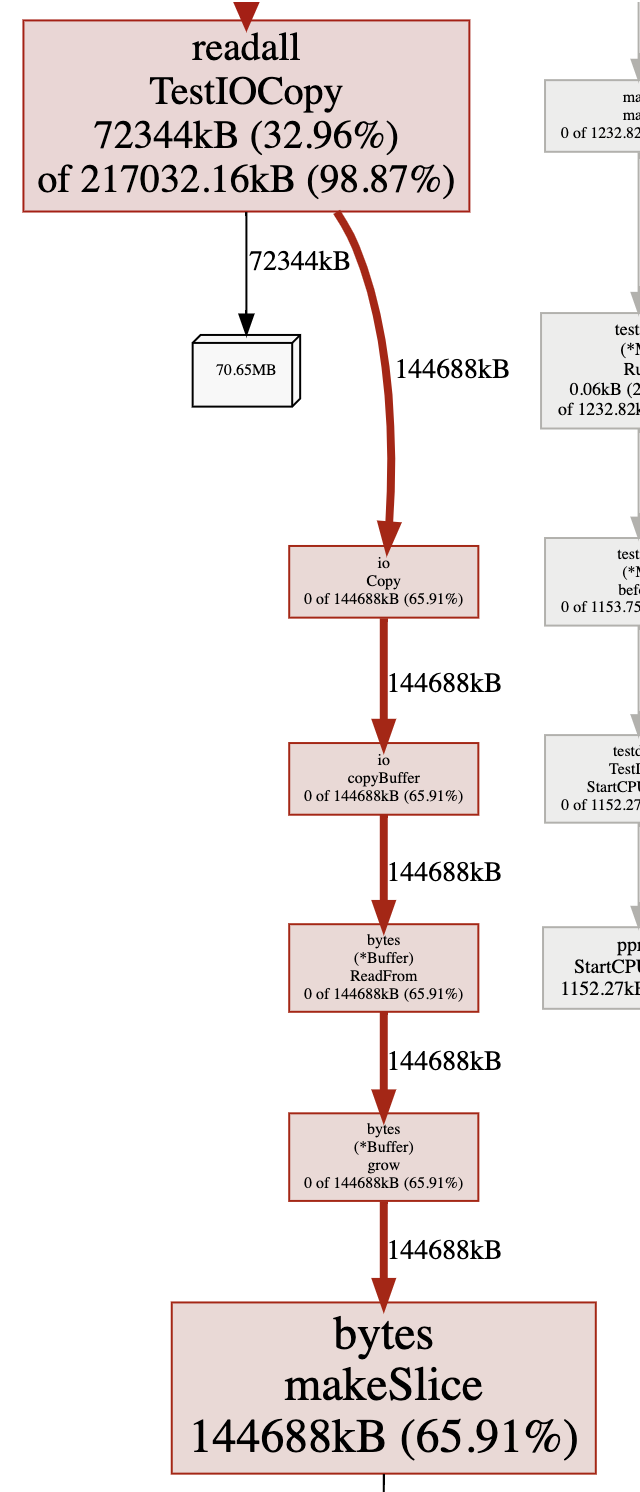
4.2. 预分配双倍文件大小内存
在代码中预先分配双倍文件大小的内存:
func TestIOCopy(t *testing.T) {
file, err := os.Open(testName)
if err != nil {
t.Errorf("open err:%v", err)
return
}
data := make([]byte, 0, 74077894*2)
buf := bytes.NewBuffer(data)
_, err = io.Copy(buf, file)
if err != nil {
t.Errorf("readall err:%v", err)
return
}
}
执行单测,分析 cpu 和内存概要文件。
分析 cpu 耗时,可以看到只花了 10ms,比最开始使用 ioutil.ReadAll 减少80ms。
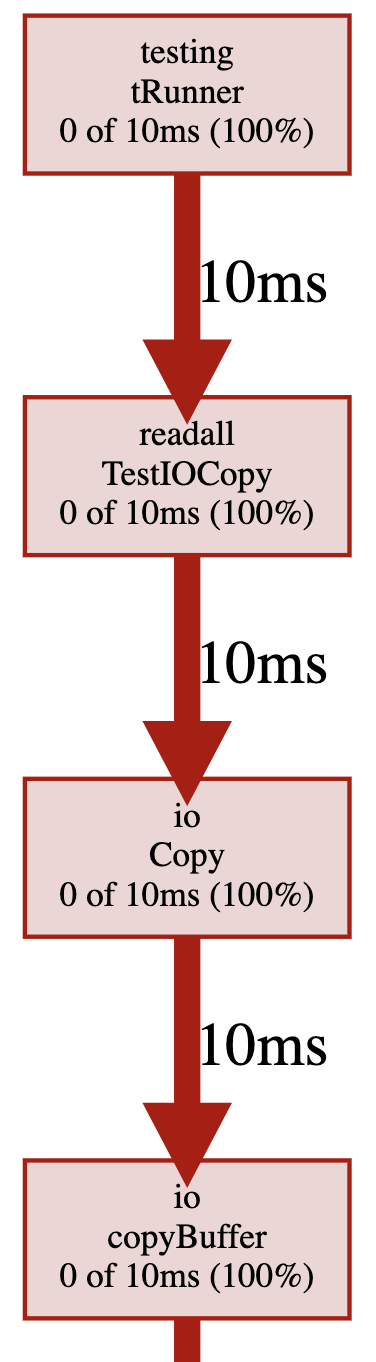
内存概要分析如下,可以看到除了最开始的内存分配,代码内部没有额外的内存分配了,这也是耗时进一步下降的原因。
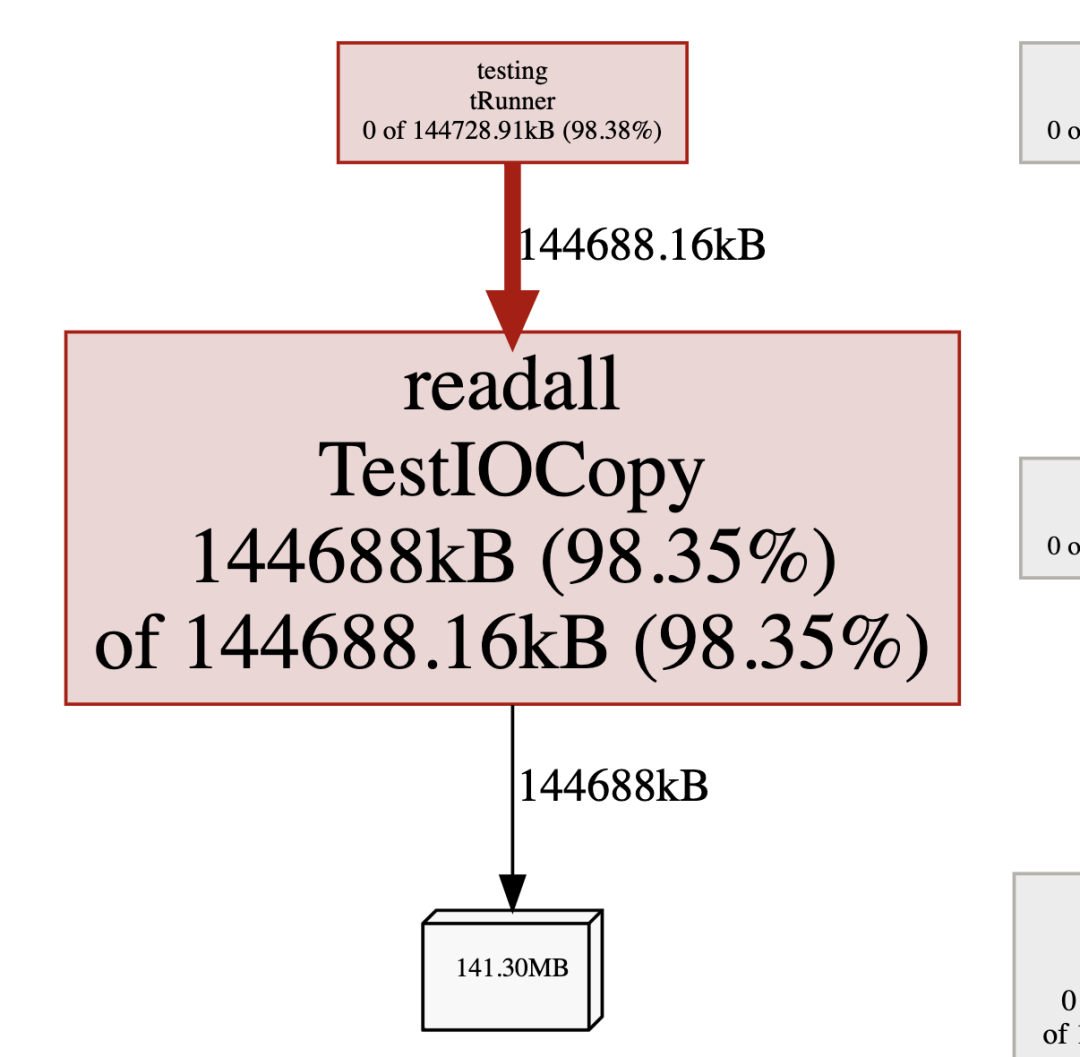
5. 并发压测
前面的测试只是运行一次,比较cpu 耗时和内存分配次数。但是在实际业务中,可能存在并发 IO 的情形,这种情况下,io.copy 比 ioutil.ReadAll 能提高多少性能呢?
下面的单测中,分别运行 100 次并发示例进行比较,在 readAllData 和 iocpoyData 函数中并发度控制在 10,计算量为 100。执行单元测试,统计总的 cpu 耗时和内存分布。
注意,下面的 iocpoyData 函数中,预分配的内存大小是双倍的文件大小。
func TestReadAllIOCopy(t *testing.T) {
for i := 0; i < 100; i++ {
readmax, readtotal := readAllData(t, testName)
copymax, copytotal := iocopyData(t, testName)
t.Logf("Max copy/read:%v, total copy/read:%v",
float64(copymax)/float64(readmax), float64(copytotal)/float64(readtotal))
}
}
func readAllData(t *testing.T, fileName string) (int64, int64) {
mu := &sync.Mutex{}
var max int64
var total int64
ctrl := make(chan struct{}, 10)
wg := &sync.WaitGroup{}
for i := 0; i < 100; i++ {
ctrl <- struct{}{}
wg.Add(1)
go func() {
defer func() {
<-ctrl
wg.Done()
}()
start := time.Now()
file, err := os.Open(fileName)
if err != nil {
t.Errorf("open err:%v", err)
return
}
_, err = ioutil.ReadAll(file)
if err != nil {
t.Errorf("readall err:%v", err)
return
}
cost := time.Since(start).Milliseconds()
atomic.AddInt64(&total, cost)
mu.Lock()
if cost > max {
max = cost
}
mu.Unlock()
}()
}
wg.Wait()
return max, total
}
func iocopyData(t *testing.T, fileName string) (int64, int64) {
mu := &sync.Mutex{}
var max int64
var total int64
wg := &sync.WaitGroup{}
ctrl := make(chan struct{}, 10)
for i := 0; i < 100; i++ {
ctrl <- struct{}{}
wg.Add(1)
go func() {
defer func() {
<-ctrl
wg.Done()
}()
start := time.Now()
file, err := os.Open(fileName)
if err != nil {
t.Errorf("open err:%v", err)
return
}
fileInfo, er := os.Stat(fileName)
if er != nil {
t.Errorf("state err:%v", err)
return
}
data := make([]byte, 0, fileInfo.Size()*2)
buf := bytes.NewBuffer(data)
_, err = io.Copy(buf, file)
if err != nil {
t.Errorf("copy err:%v", err)
return
}
cost := time.Since(start).Milliseconds()
atomic.AddInt64(&total, cost)
mu.Lock()
if cost > max {
max = cost
}
mu.Unlock()
}()
}
wg.Wait()
return max, total
}
5.1. cpu 分析
下图是 cpu 时间的分析,可以看到 readAllData 花了 704.03s,iocopyData 只花了 161s,后者是前者比例的 22.8%。
两个函数都会调用 runtime.makeSlice 进行内存分配,不同的是 readAllData 花费了 248.8s 在调用这个函数上面,而 readAllData 只花了 131.6s,后者是前者的 52.8%,这个结果也是和代码实现相吻合的。
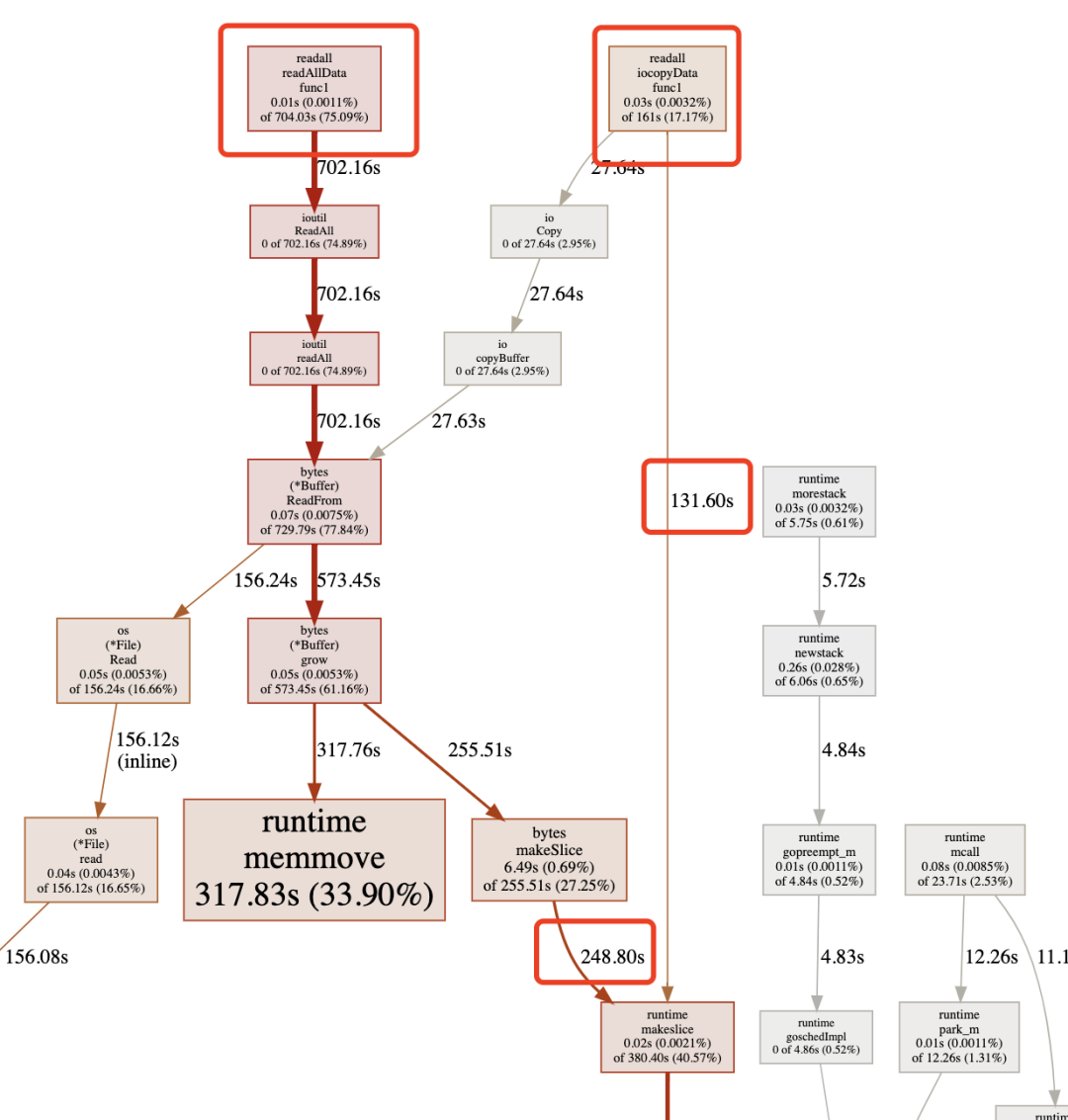
5.2. 内存分析
接下来看一下两者的内存分析。
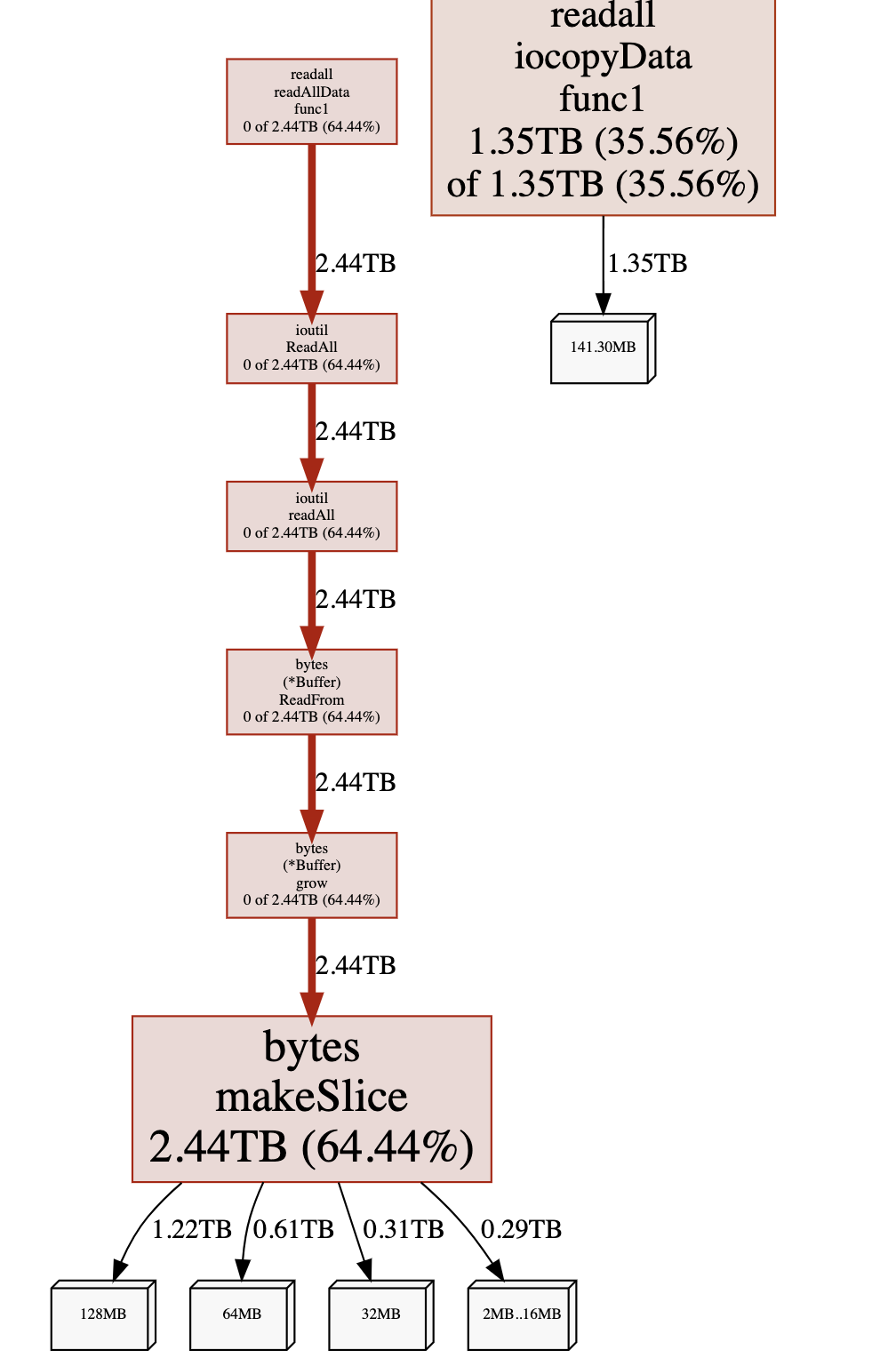
readAllData 在内部多次分配内存,所以内存消耗也要比 iocopyData 大很多。readAllData 执行的时候花了 2.44TB 的内存,几乎全部用在了 bytes.makeSlice 上面;而 iocopyData 则只在最开始手动进行了内存分配,共花了 1.35TB 内存了;后者是前者内存消耗的 55.3%。这个比例与前面内存分配消耗的时间比例也是吻合的。
总结
综上所述,在涉及频繁 IO 的情况下,尽可能使用 io.Copy 并且分配指定内存可以降低代码运行时间,并且提高内存效率。当指定的内存大小是需要读取的数据大小的两倍时,效率达到最高。
推荐阅读