
搞懂Transformer系列(二十五):关于视觉 Transformer 应该知道的3件事
共 4416字,需浏览 9分钟
· 2022-07-05

极市导读
虽然目前视觉 Transformer 已经在多种视觉任务上取得了相当大的进步,但对其架构设计和训练过程优化的探索仍然十分有限。本文提供了3个关于训练视觉 Transformer 的建议。 >>加入极市CV技术交流群,走在计算机视觉的最前沿
本文目录
45 关于视觉 Transformer 你应该知道的3件事
(来自 Meta AI,DeiT 一作团队)
45.1 论文解读
Transformer 是 Google 的团队在 2017 年提出的一种 NLP 经典模型,现在比较火热的 Bert 也是基于 Transformer。Transformer 模型使用了 Self-Attention 机制,不采用 RNN 的顺序结构,使得模型可以并行化训练,而且能够拥有全局信息。
虽然视觉 Transformer 已经在多种视觉任务上取得了相当大的进步,但对其架构设计和训练过程优化的探索仍然十分有限。本文提供了3个关于训练视觉 Transformer 的建议。
45 关于视觉 Transformer 你应该知道的3件事

论文名称:Three things everyone should know about Vision Transformers
论文地址:
https://arxiv.org/pdf/2203.09795.pdf
45.1 论文解读:
虽然视觉 Transformer 已经在多种视觉任务上取得了相当大的进步,但对其架构设计和训练过程优化的探索仍然十分有限。本文提供了3个关于训练视觉 Transformer 的建议。
建议1:通过并行的视觉 Transformer 实现更低的延时
更浅的网络架构容易实现更低的延时和更加容易的优化。用 MHSA 表示多头自注意力块,用 FFN 表示残差前馈网络。如下图1所示,作者重新以成对的形式组织模型的架构,这产生了更宽更浅的架构,每个并行的块拥有相同的参数量和计算量。这种设计允许更多的并行处理,可以实现更低的延时和更加容易的优化。
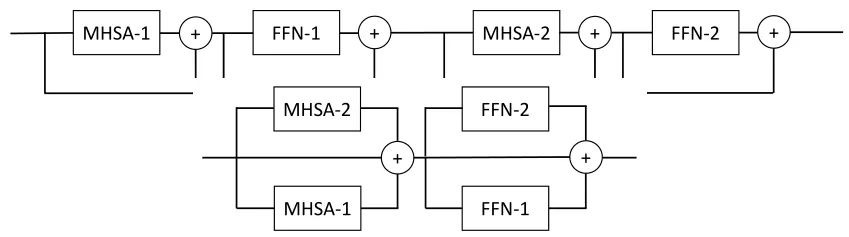
建议2:只微调 Attention 即可实现良好的迁移性能
迁移学习的标准方法一般是先对模型做预训练,再迁移到目标任务上面。这种情况适用于目标任务的数据集大小受限时,也适用于目标任务和预训练任务的分辨率不一样时。一般来说,训练的分辨率要比推理时使用的分辨率低。这不仅节省了资源,还减少了由于 Data Augmentation 所导致的训练和测试图像之间的比例差异。作者在本文中表明,在大多数 ViT 的迁移学习情况下,仅 MHSA 层并冻结 FFN 层的参数就足够了,这可以节省计算量并减少训练期间的内存峰值 (memory peak),且不会影响精度。
建议3:改进 ViT 的 Patch 预处理层以更好地适配基于 MIM 的自监督学习
Transformer 的第1层一般感受野比较小。通过 Convolutional Stem 处理输入图片有利于训练的稳定。然而,用卷积预处理图像与基于 MIM 的自监督学习方法 (如 BeiT[1],MAE[2] 等) 不兼容。为了和 MIM 的自监督学习方法相适应,作者在本文中提出了一种 patch pre-processing 的做法。
实验过程
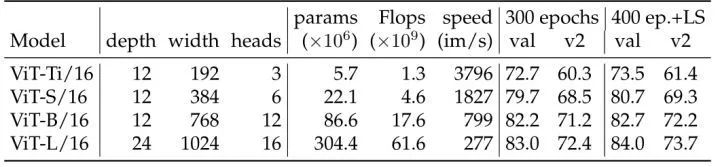
首先作者跑了一些 Baseline 的实验结果,如下图2所示。分辨率均为 224×224,LS 代表 Layer Scale。学习率设置为:ViT-Ti 和 ViT-S 为 4e-3,ViT-B 和 ViT-L 为 3e-3。
实验探索1:通过并行的视觉 Transformer 实现更低的延时
在 ViT 模型里面,复杂性度量受到宽度和深度的影响。忽略一开始的图像分块操作和最终的分类头,因其对复杂性的影响可以忽略不计,则有:
ViT 模型的参数量和网络的深度成正比关系,和宽度成二次方关系。
ViT 模型的计算量和网络的深度成正比关系,和宽度成二次方关系。
ViT 推理时的显存峰值不随深度的改变而改变,但是和宽度成二次方关系。
更宽的架构的延时在理论上更好,因为更加并行化,但实际的加速取决于实现和硬件。
作者首先做的实验是把下式1所示的串行结构变为2式的并行结构:
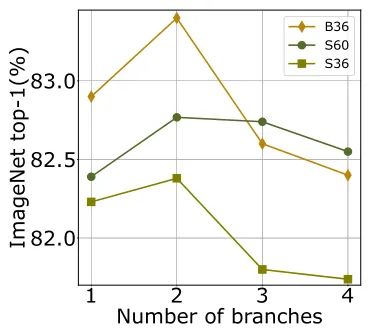
下图1是分支数对于 ViT 性能的影响。对于不论是 Small 模型还是 Base 模型,使用2个并行分支可以获得最佳性能。ViT-S60 的 S20×3 和 S30×2 之间的性能相当。
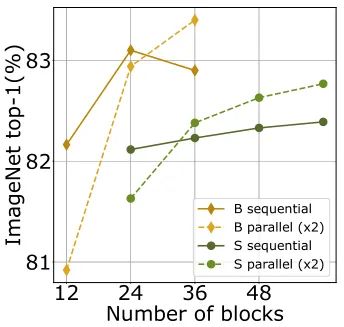
下图2是不同尺寸大小的模型采用顺序结构和并行结构的性能对比。对于不论是 Small 模型还是 Base 模型,使用2个并行分支可以获得最佳性能。ViT-S60 的 S20×3 和 S30×2 之间的性能相当。实验的观察与先前的发现一致:ViT 模型采用并行版本对于更难优化的更深和更高容量的模型有帮助,本文提出的的并行化方案使得深层 ViT 的训练更加容易。
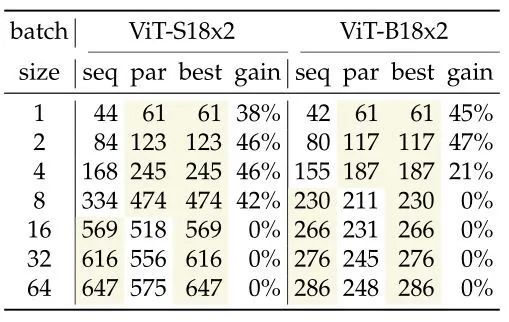
下图3是不同尺寸大小的模型采用顺序结构和并行结构的处理速度对比。在 V100 GPUs 上,作者观察到单样本处理的速度明显加快,但是当 Batch Size 变得比较大时,处理的速度没有提升。
实验探索2:只微调 Attention 即可实现良好的迁移性能
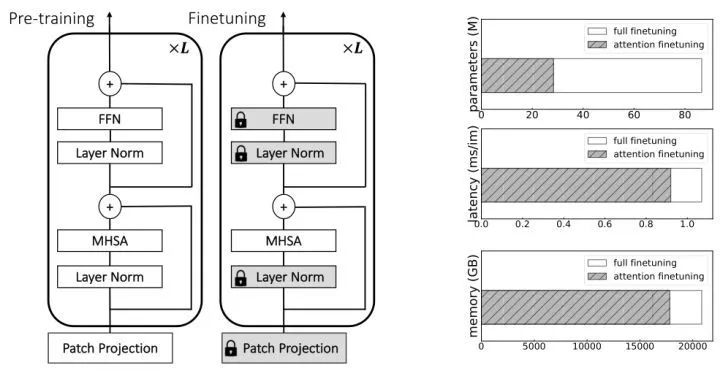
本节中作者重点关注 ViT 模型的微调,以使模型适应更高的图像分辨率,或者解决不同的下游分类任务。具体来说,考虑一种方法,其中仅微调 MHSA 层的权重,如下图4所示。作者从预测的准确性,峰值内存的使用和参数量方面分析了这么做带来的影响。
如下图4所示是作者在 384×384 分辨率下微调了在 224×224 分辨率下预训练ViT-S、ViT-B 和 ViT-L 模型的结果。可以看到无论是在 ImageNet-val 还是 ImageNet-V2 上,单独微调 MHSA 层权重的结果和微调全部权重的结果相差很小。但是只微调 FFN 层时,结果相差较大。

与微调所有参数相比,在高分辨率下微调 MHSA 参数的优势是:可以在参数,延迟和峰值内存使用方面获得大量的节约,如下图5所示。微调 MHSA 在 GPU 上可以节约 10% 的内存,这在高分辨率微调需要更多内存的情况中特别有用。此外训练速度也提高了 10%,因为计算的梯度更少了。最后,MHSA 的权重大约相当于权重的三分之一。因此,如果想要使用针对不同输入分辨率进行微调的多个模型,我们可以为每个额外的模型节省 66% 的存储空间。
实验探索3:改进 ViT 的 Patch 预处理层以更好地适配基于 MIM 的自监督学习
传统的 ViT 模型通过卷积头进行输入图片的预处理 (分块) 操作,通常称之为 Convolutional Stem。虽然这些预处理设计能够提高准确性或稳定性,但是仍然存在一些问题。比如,Patch 预处理层如何去更好地适配基于 MIM 的自监督学习,比如 BEiT 的范式。
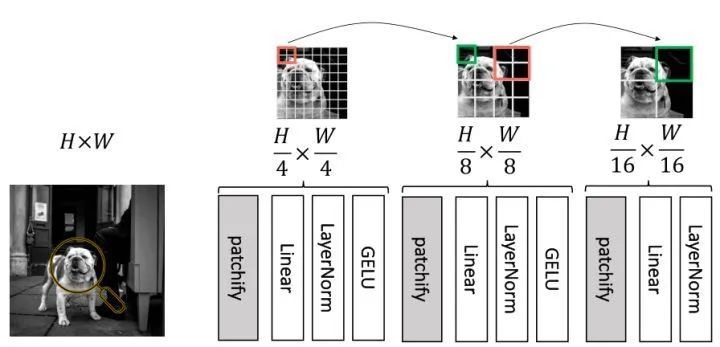
在这部分中,作者设计了一种 hierarchical MLP (hMLP) stem,即分层 MLP 预处理范式,如下图6所示。第一次把图片分成 4×4 大小的 Patch,再经过两次合并 2×2 的区域,最终把 224×224 大小的图片变换成 14×14 的特征。可以看到每个 16×16 大小的图像 Patch 是独立处理的
hMLP 的具体实现如下图7所示。Linear 操作具体都是使用卷积来实现,三个卷积的参数分别是: 。

hMLP 的一个好处是:这样的方式处理图片的话,图片的各个 Patch 之间是互不关联的。换言之,不同的 Patch 之间就存在信息交互,也就和原来的 ViT 不是完全等价。而且,hMLP 的设计没有显著增加计算需求。比如,ViT-B 需要的 FLOPs 仅仅为 17.73 GFLOPs。与使用通常的线性投影相比,只增加了不到 1% 的计算量。
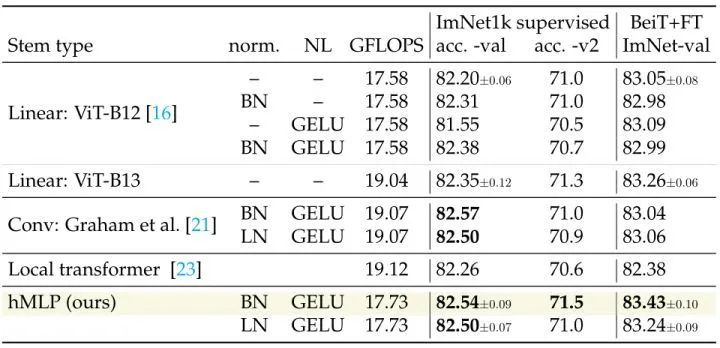
作者在下图8中比较了几种 Stem 在有监督学习任务和 BEiT 的自监督式学习任务上的性能。hMLP 也都实现了更好的精度-计算量均衡。
总结
本文介绍了 ViT 的3个不同主题。首先是一种简单而有效的并行化方法,能够节约推理延时。其二是在做迁移学习任务时,仅仅微调 MHSA 的参数就能获得不错的性能,同时节约训练的内存占用。最后是一种图片分块的方式:hMLP,它可以很好地适配于基于 MIM 的自监督学习方法,使得不同的 Patch 之间信息不相互关联。
参考
^BEiT: BERT pre-training of image transformers ^Masked autoencoders are scalable vision learners
公众号后台回复“数据集”获取90+深度学习数据集下载~

# 极市平台签约作者#

科技猛兽
知乎:科技猛兽
清华大学自动化系19级硕士
研究领域:AI边缘计算 (Efficient AI with Tiny Resource):专注模型压缩,搜索,量化,加速,加法网络,以及它们与其他任务的结合,更好地服务于端侧设备。
作品精选
