
全新Backbone | 华中科大提出ConvFormer,解决CNN与Self-Attention混合设计崩溃的痛点~
共 19268字,需浏览 39分钟
· 2023-10-30
点击下方卡片,关注「集智书童」公众号

Transformer模型在医学图像分割领域得到了广泛研究,用于构建长距离依赖关系。然而,相对有限的高质量标注医学图像数据使得Transformer难以提取多样的全局特征,导致了注意力崩溃,其中注意力图变得相似甚至相同。
相比之下,卷积神经网络(CNNs)在小规模训练数据上具有更好的收敛性能,但受到有限的感受野限制。现有的工作致力于探索CNN和Transformer的组合,但忽略了注意力崩溃问题,从而未充分发掘了Transformer的潜力。
在本文中,作者提出构建CNN风格的Transformer(ConvFormer),以促进更好的注意力收敛性,从而提高分割性能。具体而言,ConvFormer包括池化、CNN风格的自注意力(CSA)和卷积前馈网络(CFFN),分别对应于标准视觉Transformer中的Token、自注意力和前馈网络。与位置嵌入和Token不同,ConvFormer采用2D卷积和最大池化,用于保存位置信息和减小特征大小。这样,CSA将2D特征映射作为输入,并通过构建自注意力矩阵作为自适应大小的卷积核来建立远程依赖性。在CSA之后,使用2D卷积进行特征细化。
多个数据集上的实验结果表明,ConvFormer作为一种即插即用的模块,可以持续改善基于Transformer的框架的性能。
代码:https://github.com/xianlin7/ConvFormer
1、简介
受益于模建全局依赖性的突出能力,Transformers已经成为自然语言处理的标准。与鼓励局部性、权重共享和平移等变性的卷积神经网络(CNNs)相比,Transformers通过自注意力层构建全局依赖性,为特征提取带来更多可能性,并打破CNNs在性能上的局限。
受此启发,Transformers被引入到医学图像分割中并引起了广泛关注。在视觉Transformers中,每幅医学图像首先被分割成一系列Patch,然后投影到一维的Patch嵌入序列中。通过在Patch/Token之间建立成对交互,Transformers应该聚合全局信息以进行稳健的特征提取。然而,Transformers中学习良好的全局依赖性需要大量数据,这使得在相对有限的医学成像数据情况下,Transformers效果较差。
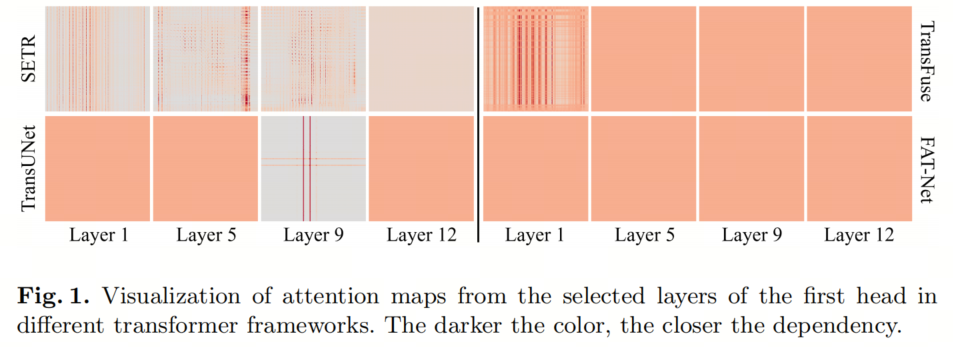
为了了解Transformers在医学图像分割中的工作原理,作者在ACDC数据集上训练了四种最先进的基于Transformer的模型,并在图1中可视化了不同层次学到的自注意力矩阵。对于所有方法,注意力矩阵在Patch之间趋向于变得均匀(即注意力崩溃),特别是在更深的层次中,注意力崩溃更加明显,尤其是在CNN-Transformer混合方法(即TransUNet、TransFuse和FAT-Net)中。
一方面,不足的训练数据会使Transformers学习到次优的长距离依赖性。另一方面,直接将CNN与Transformers相结合会使网络偏向于学习CNNs,因为与Transformers相比,尤其是在小规模训练数据上,CNNs更容易收敛。因此,如何解决注意力崩溃并改善Transformers的收敛性对性能提升至关重要。
在本研究中,作者提出了一个名为ConvFormer的即插即用模块,通过构建可扩展卷积式CNN风格的Transformer来解决注意力崩溃问题。在ConvFormer中,2D图像可以直接构建足够的长距离依赖性,而无需拆分成1D序列。
具体而言,对应于标准视觉Transformers中的Token、自注意力和前馈网络,ConvFormer分别由池化、CNN风格的自注意力(CSA)和卷积前馈网络(CFFN)组成。对于输入图像/特征图,首先通过交替应用卷积和最大池化来减小其分辨率。然后,CSA通过自适应生成可扩展卷积来为每个像素构建适当的依赖性,可以更小以包括局部性,也可以更大以进行长距离全局交互。最后,CFFN通过连续卷积来细化每个像素的特征。
在五种最先进的基于Transformer的方法跨三个数据集的大量实验中,验证了ConvFormer的有效性,优于现有的注意力崩溃解决方案。
2 方法
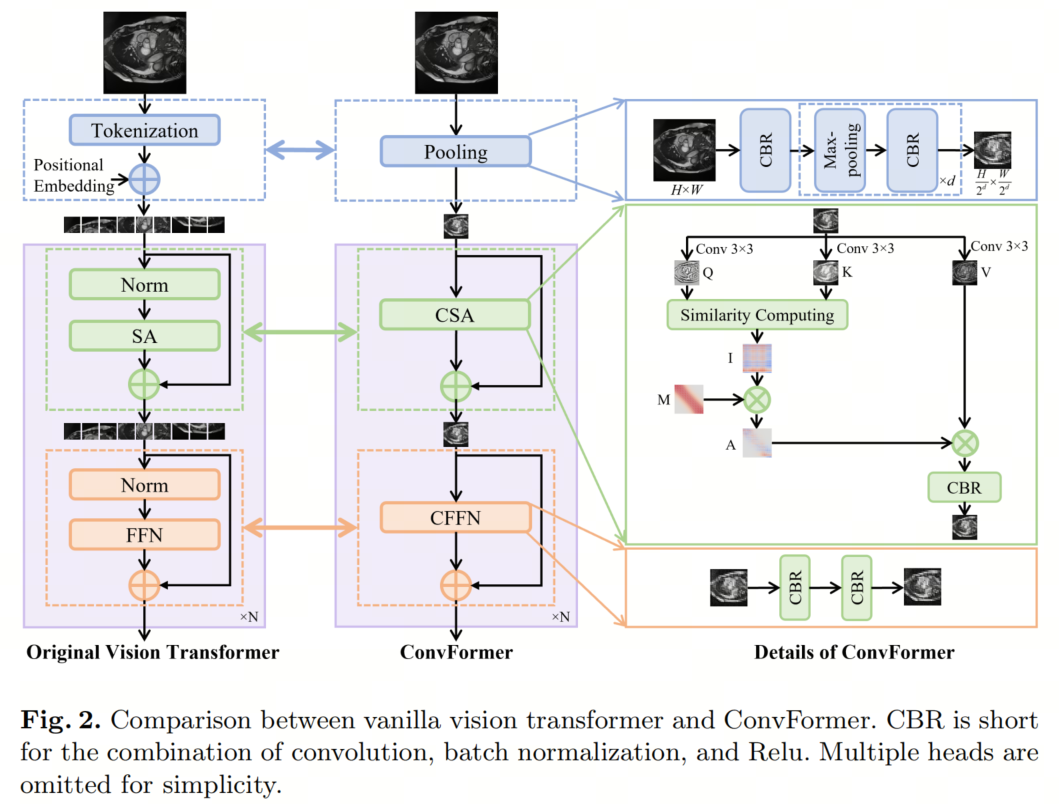
视觉Transformer(ViT)和ConvFormer之间的比较如图2所示。最大的区别在于,作者的ConvFormer在2D输入上进行,而ViT应用于1D序列。
具体而言,池化模块用于替代ViT中的Token化,它在不需要额外位置嵌入的情况下很好地保留了局部性和位置信息。CNN风格的自注意力(CSA)模块,即ConvFormer的核心,用于替代ViT中的自注意力(SA)模块,通过构建具有自适应和可扩展内核的自注意力矩阵,以建立长程依赖性。
卷积前馈网络(CFFN)用于为与ViT中的前馈网络(FFN)相对应的每个像素细化特征。没有采用上采样过程将ConvFormer的输出调整回输入大小,因为池化模块可以通过调整最大池化次数来匹配输出大小。
需要注意的是,ConvFormer是基于卷积实现的,这消除了在训练过程中CNN和Transformer之间的紧张关系,正如第1节中所分析的。ConvFormer的每个模块在以下描述。
2.1 池化 vs. Token化
池化模块被开发出来实现Token化的功能(即,使输入适合于通道维度的Transformer,并在需要时调整和减小输入大小),而不会在Token化中丢失网格线上的细节。对于输入 ,首先应用一个卷积核大小为3×3,然后进行批量归一化和Relu,以捕获局部特征。然后,与ViT中的每个Patch大小 相对应,池化模块中应用总共 次下采样操作,以产生相同的分辨率。
这里,每个下采样操作包括一个2×2的最大池化和一个3×3卷积、批量归一化和Relu的组合。最后,通过池化模块, 变为,其中 对应于ViT中的嵌入维度。
2.2 CNN风格 vs. 序列化自注意力
ConvFormer中长程依赖性的构建依赖于CNN风格的自注意力,它通过构建自定义卷积核为每个像素创建自适应的感受野。具体来说,对于 中的每个像素 ,卷积核 是基于两个中间变量构建的:
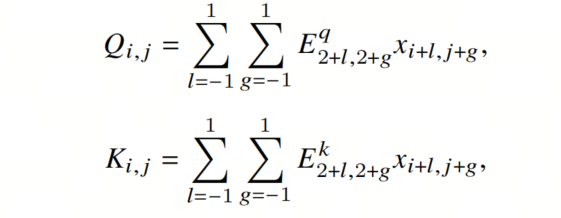
其中 和 是可学习的投影矩阵, 对应于ViT中的𝑄、𝐾和𝑉的嵌入维度,它将3×3邻域中相邻像素的特征合并到 中。然后,通过计算余弦相似度,计算出每个像素 的初始自定义卷积核 :
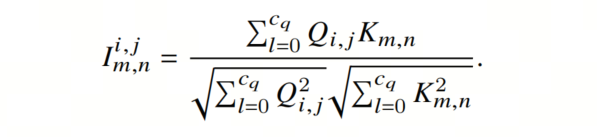
这里, ,并且很少发生 。 对应于ViT中的注意力分数计算(受限于为正,而 可以为正或负)。然后,作者通过引入可学习的高斯距离图𝑀,动态确定 的自定义卷积核的大小:
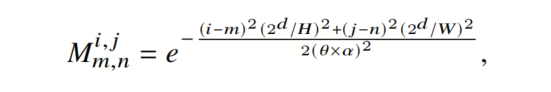
其中 是一个可学习的网络参数,用于控制𝐴的感受野, 是一个控制感受野趋势的超参数。 与感受野成正比。例如,在典型设置下, , , 时,当𝜃 = 0.003时,感受野仅覆盖5个相邻像素,当 时,感受野是全局的。 越大, 越容易具有全局感受野。基于 和 ,计算出 。这样,每个像素 都有一个自定义的大小可扩展卷积核 。通过将𝐴与𝑉相乘,CSA可以构建自适应的长程依赖性,其中𝑉可以根据公式(1)类似地制定。最后,通过使用1×1卷积、批量归一化和Relu的组合来集成从长程依赖性中学到的特征。
2.3 卷积 vs. 原始前馈网络
卷积前馈网络(CFFN)用于细化由CSA生成的特征,仅由两个1×1卷积、批量归一化和Relu的组合组成。通过用CFFN替换ViT中的线性投影和层归一化,ConvFormer完全基于CNN,避免了在训练过程中CNN和Transformer之间的冲突,就像CNN-Transformer混合方法一样。
3、实验
ConvFormer可以作为一种即插即用的模块,替代Transformer模型中的普通Transformer块。
为了评估ConvFormer的有效性,选择了5种最先进的基于Transformer的方法作为Backbone,包括SETR、TransUNet、TransFuse、FAT-Net和Patcher。SETR和Patcher使用纯Transformer编码器,而TransUNet、TransFuse和FAT-Net采用CNN-Transformer混合编码器。
此外,还装备了3种解决注意力折叠问题的最先进方法,包括Re-attention、LayerScale和Refiner,并与上述基于Transformer的基线进行比较。
定量结果
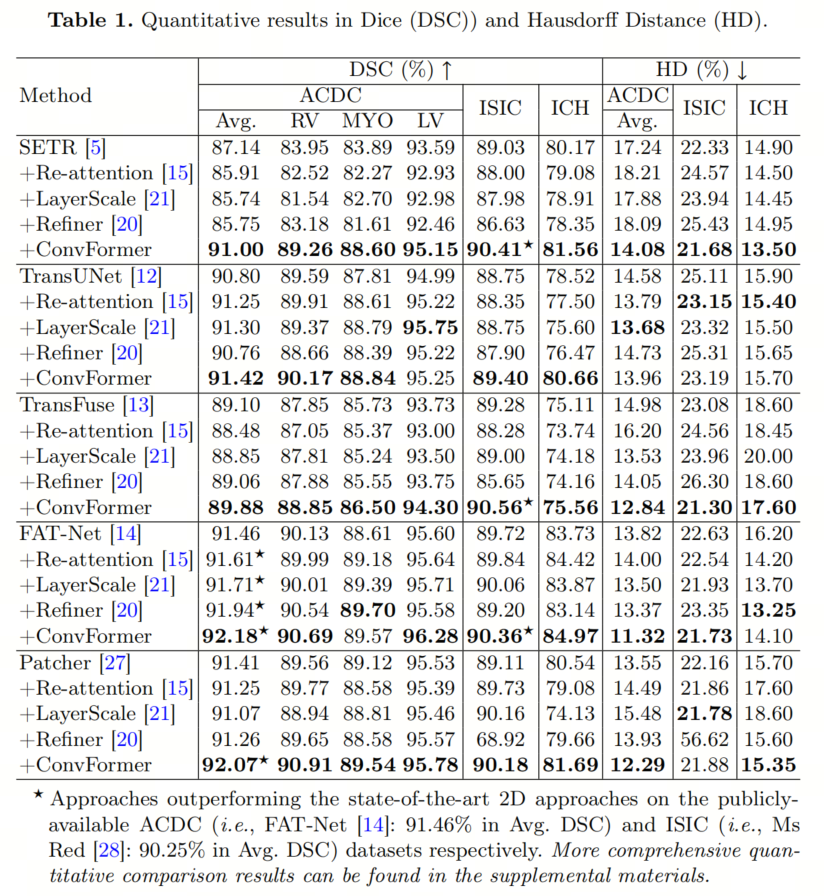
在表1中总结了嵌入不同基线的ConvFormer在三个数据集上的定量结果。ConvFormer在所有5个Backbone上都实现了一致的性能提升。
与CNN-Transformer混合方法(即TransUNet、TransFuse和FAT-Net)相比,ConvFormer对纯Transformer方法(即SETR和Patcher)更有益。
具体来说,使用ConvFormer,SETR在ACDC、ISIC和ICH数据集上的Dice分数平均增加了分别为3.86%、1.38%和1.39%,而Patcher的相应性能改善分别为0.66%、1.07%和1.15%。
相比之下,在CNN-Transformer混合方法中,如上所分析,CNN在训练过程中更具主导地位。尽管如此,通过ConvFormer来重新平衡CNN和Transformer,可以建立更好的长程依赖性,实现一致的性能提升。
与SOTA方法的比较
在表1中总结了与解决注意力折叠问题的最新方法相比的定量结果。总的来说,鉴于相对有限的训练数据,针对自然图像处理设计的现有方法不适用于医学图像分割,在不同Backbone和数据集上表现不稳定。
相比之下,ConvFormer始终优于这些方法,并为各种Backbone提供了稳定的性能改进,展示了ConvFormer作为即插即用模块的出色通用性。
自注意力矩阵的可视化
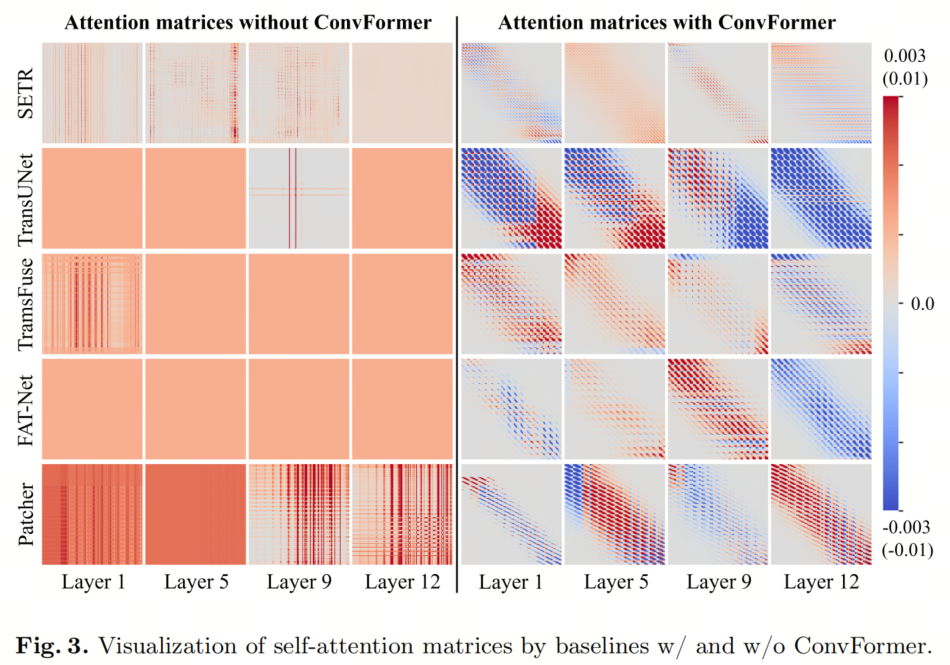
为了定性评估ConvFormer在解决注意力折叠和建立有效的长程依赖性方面的有效性,作者可视化了自注意力矩阵,有无ConvFormer,如图3所示。通过引入ConvFormer,有效减轻了注意力折叠。与基线的自注意力矩阵相比,ConvFormer学到的矩阵更加多样化。
具体来说,每个像素的交互范围是可扩展的,对于保持局部性或获得全局感受野来说,它可以很小或很大。此外,依赖性不再受到像ViT那样必须为正的约束,更符合卷积核的情况。
消融研究

如第2.2节所述,𝛼用于控制ConvFormer中感受野趋势。𝛼越大,ConvFormer包含更大的感受野的可能性就越大。
为了验证这一点,作者进行了关于𝛼的消融研究,如表2所总结。总的来说,使用较大的𝛼不一定会导致更多的性能提升,这与作者的观察一致,即并不是每个像素都需要全局信息来进行分割。
4、参考
[1]. ConvFormer: Plug-and-Play CNN-Style Transformers for Improving Medical Image Segmentation.
5、推荐阅读
对视觉大语言模型一致性分析:当GPT-4V不能与文本意见一致时,它迷失在翻译之中了!
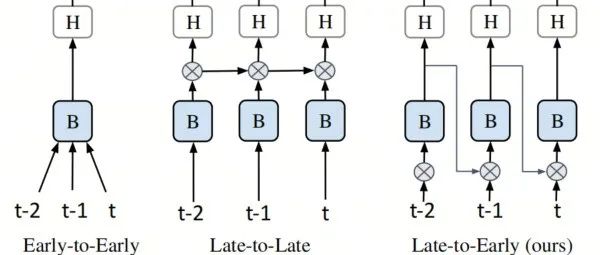
Waymo提出全新Fusion方法LEF | 让3D目标检测的难度再次降低!
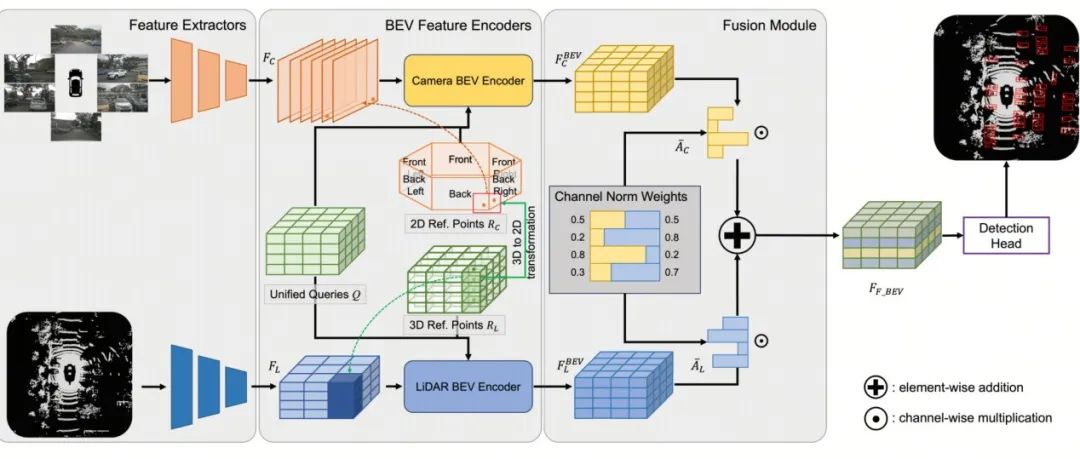
BEVFusion?看UniBEV携CNW融合策略如何一统多模态融合的江湖

扫码加入👉「集智书童」交流群
(备注:方向+学校/公司+昵称)




前沿AI视觉感知全栈知识👉「分类、检测、分割、关键点、车道线检测、3D视觉(分割、检测)、多模态、目标跟踪、NerF」
欢迎扫描上方二维码,加入「集智书童-知识星球」,日常分享论文、学习笔记、问题解决方案、部署方案以及全栈式答疑,期待交流!