
LSKA注意力 | 重新思考和设计大卷积核注意力,性能优于ConvNeXt、SWin、RepLKNet以及VAN
共 20961字,需浏览 42分钟
· 2023-09-14
点击下方卡片,关注「集智书童」公众号

视觉注意力网络(VAN)具有大卷积核注意力(LKA)模块已经在一系列基于视觉的任务上表现出卓越的性能,超越了视觉Transformer。然而,这些LKA模块中的深度卷积层随着卷积核大小的增加而导致计算和内存占用呈二次增加。
为了缓解这些问题,并实现在VAN的注意力模块中使用极大的卷积核,作者提出了一系列Large Separable Kernel Attention模块,称为LSKA。LSKA将深度卷积层的二维卷积核分解为级联的水平和垂直一维卷积核。与标准的LKA设计相比,所提出的分解使得可以在注意力模块中直接使用具有大卷积核的深度卷积层,无需额外的块。作者证明了VAN中所提出的LSKA模块可以实现与标准LKA模块相当的性能,并且计算复杂性和内存占用更低。作者还发现,随着卷积核大小的增加,所提出的LSKA设计更倾向于将VAN偏向物体的形状而不是纹理。
此外,作者在5个研究中较少探讨的ImageNet数据集的受损版本上对VAN、ViTs和最近的ConvNeXt的LKA和LSKA进行了基准测试。广泛的实验结果显示,VAN中的LSKA模块随着卷积核大小的增加,计算复杂性和内存占用显著减少,同时在目标识别、目标检测、语义分割和稳健性测试方面优于ViTs、ConvNeXt,并与VAN中的LKA模块性能相似。
1、简介
在过去的十年里,卷积神经网络的架构和优化技术迅速发展。这一进化来自于激活函数的设计,CNN参数的正则化方法的提出,新的优化方法的构建,成本函数,以及新的网络架构。CNN领域的大多数突破都集中在人类认知过程,特别是人类视觉系统周围。
由于具有平移等变性和局部性质,CNN是各种基于视觉的任务的常见特征编码器的选择,包括图像分类,语义分割和目标检测。通过使用注意力机制,可以进一步提高CNN在这些基于视觉的任务中的性能。例如,已经证明,注意力机制通过产生与人眼和大脑一致的显著区域来提高CNN的性能。尽管CNN与注意力机制非常有效,但最近在视觉领域中自注意力网络的适应性激增,如Vision Transformer(ViT)及其变体在图像分类、目标检测和语义分割方面已经超越了CNN。
与CNN相比,ViT的卓越性能归因于使用Multi-Head-Self-Attention(MHSA)作为其关键组成部分的Transformer的更好的扩展行为。然而,ViT在视觉领域的有效性是以在面对高分辨率输入图像时计算和内存占用呈二次增加为代价的。然而,ViT(如Swin-Transformer)的有效性重新探讨了自从引入VGG网络以来一直被掩盖的CNN设计选择的大门。
与CNN相比,ViT在图像分类中取得成功的主要原因之一是其能够建模输入图像的长距离依赖性。通过注意力机制,CNN可以模拟图像中的长距离依赖性,通过使用更大的感受野。CNN中的大感受野是通过堆叠许多卷积操作或使用更大的卷积核尺寸来获得的。前一种方法可能会导致模型大小的增加,而后一种方法则被认为由于其内存和计算要求而费用过高。
然而,在最近的研究中,作者们表明,可以通过连接级联的深度卷积和空洞的深度卷积来建模CNN中的大卷积核,而不会导致计算和内存占用的二次增加。他们提出的Visual Attention Network(VAN)使用了一堆具有名为Large Kernel Attention(LKA)的简单注意力机制的卷积核,如图2c所示。LKA模块采用标准的深度卷积具有小的感受野卷积核,以捕获局部依赖性并补偿网格问题,然后是一个具有大感受野卷积核的空洞深度卷积以建模长距离依赖性。这种深度卷积和空洞深度卷积的组合相当于大规模CNN卷积核。空洞深度卷积的输出被送入1×1卷积以推断注意力图。然后,将输出的注意力图与输入特征相乘以进行自适应特征细化。
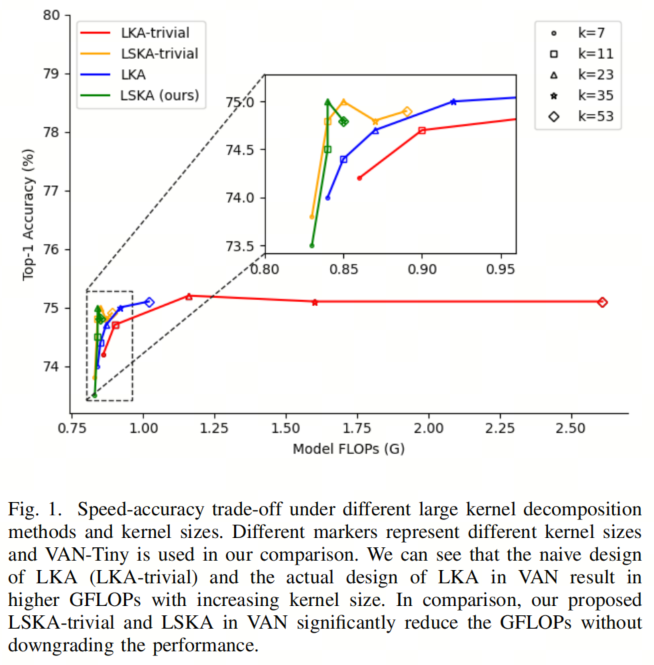
已经证明,具有LKA的VAN在图像分类、目标检测和语义分割方面胜过了最先进的ViT和CNN。然而,正如[35]所指出的,大规模深度卷积核的天真设计仍然导致计算和内存占用高,从而降低了模型随着卷积核大小的增加而带来的有效性。作者的初步结果如图1所示,作者发现VAN中LKA模块的深度卷积设计(不使用深度空洞卷积)在卷积核大小为35×35和53×53时计算效率低下。
在这篇论文中,作者首先研究了在VAN中使用深度卷积和简单注意力模块对大卷积核大小的影响。作者将具有大卷积核和注意力模块的深度卷积的设计称为LKA-trivial。其次,作者为VAN提出了深度卷积的可分离版本。深度卷积的可分离版本将给定的k×k卷积核均匀分解为1×k和k×1可分离卷积核,这些卷积核在输入特征上级联作用。
在保持其他因素不变的情况下,VAN中的LKA-trivial模块中提出的深度可分离卷积显著减少了随着卷积核大小增加而参数数量呈二次增长。作者将这种修改后的LKA-trivial设计称为LSKA-trivial。
此外,这种卷积核分解类型也与深度空洞卷积兼容,允许作者在VAN中提出完全可分离的LKA模块。作者将所提出的可分离版本的LKA模块称为LSKA。作者展示了在VAN中,即使在更大的卷积核大小下,所提出的LSKA版本的LKA可以获得相似的性能,而且计算效率较高。此外,所提出的LSKA模块在更大的卷积核大小下增强了输入图像的长程依赖性,而不会导致高计算和内存占用。
为了正式说明所提出的LSKA在VAN中的有效性,作者对一系列下游任务对LSKA和VAN中的LKA进行了广泛评估。作者还调查了所提出的LSKA和其他基线方法(如VAN中的LKA、ViTs和ConvNeXt)在各种失真数据集上的鲁棒性,这些数据集包括常见的失真、语义转移和未探索的自然对抗示例。
作者的工作贡献可以总结如下:
-
作者解决了在LKA-trivial和VAN中随着卷积核大小增加而导致的深度卷积核的计算效率问题。作者表明,将深度卷积中的k×k卷积核替换为级联的1×k和k×1卷积核可以有效减少LKA-trivial和VAN中随着卷积核大小增加而产生的参数数量的二次增长,而不会降低性能。
-
作者通过在各种基于视觉的任务(包括图像分类、目标检测和语义分割)上进行实验验证了LSKA在VAN中的有效性。作者展示了LSKA可以从大卷积核中受益,同时与原始LKA中的小卷积核相比,推断时间成本相同。
-
作者在5个多样化的ImageNet数据集上对LKA-based VAN、LSKA-based VAN、ConvNeXt和最先进的ViTs进行了鲁棒性测试,这些数据集包含应用于图像的各种类型的扰动。作者的结果表明,与以前的大卷积核CNN和ViTs相比,基于LSKA的VAN是一个更为鲁棒的学习器。
-
作者提供了定量证据,显示LSKA-based VAN中学习的大卷积核的特征编码更多的形状信息,较少的纹理,与ViTs和以前的大卷积核CNN相比。此外,特征表示中编码的形状信息的数量与不同图像失真的鲁棒性之间存在高度相关性。这些证据有助于解释为什么基于LSKA的VAN是一个鲁棒的学习器。
3. 方法论
在本节中,作者首先讨论了如何使用1D卷积核来设计LSKA模块,重构了LKA模块(使用或不使用空洞深度卷积)。然后,作者总结了LSKA模块的几个关键特性,随后对LSKA的复杂性进行了分析。
3.1. 公式
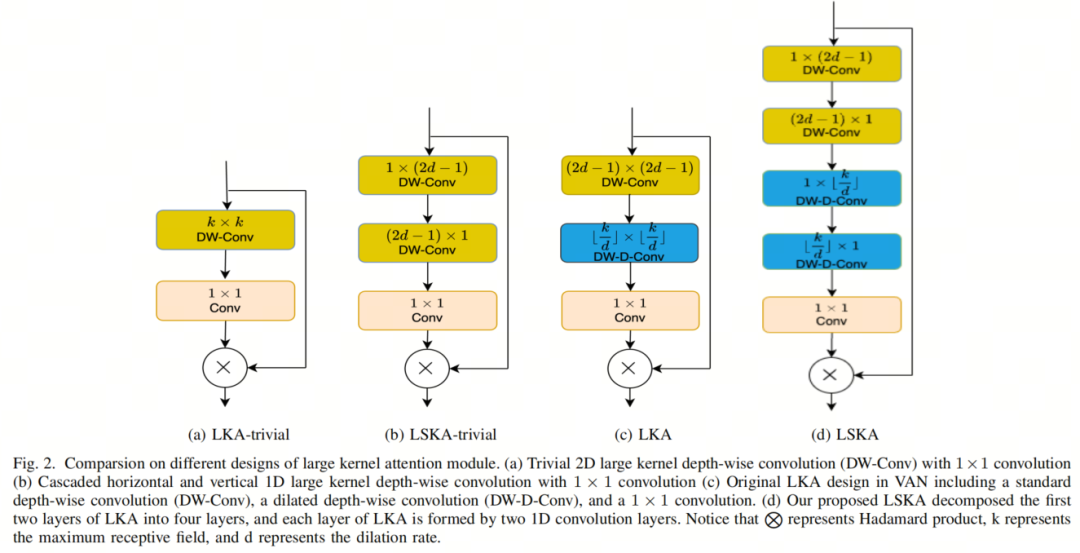
作者首先设计了基本的LKA块,不使用空洞深度卷积,如图2a所示。给定输入特征图 ,其中 是输入通道的数量, 和 分别表示特征图的高度和宽度,设计LKA的常规方法是在2D深度卷积中使用大的卷积核。可以使用Eq. 1-3来获得LKA的输出。
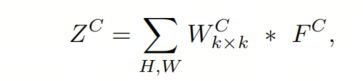
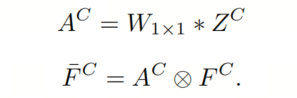
其中 和 分别表示卷积和Hadamard积。 是通过将大小为k×k的卷积核W与输入特征图F进行卷积获得的深度卷积的输出。应该注意,F中的每个通道C都与卷积核W中的相应通道进行卷积。在Eq. 1中的k还表示卷积核W的最大感受野。然后,通过卷积1×1卷积核来获得注意力图 。LKA的输出 是注意力图 和输入特征图 的Hadamard积。
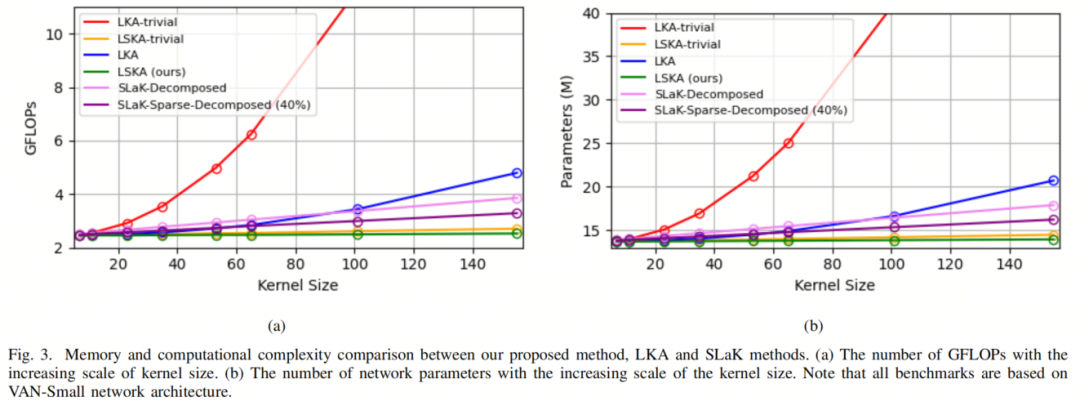
可以看出,LKA模块中的深度卷积将随着卷积核大小的增加而导致计算成本的二次增加。在本文中,作者将这种设计称为LKA-trivial,以区别于LKA的实际设计。可以迅速发现,在LKA-trivial中增加卷积核大小将在VAN中产生二次( )增加的计算复杂性(见图3)。
为了减轻LKA-trivial中较大卷积核的深度卷积的高计算成本问题,作者将大卷积核的深度卷积分解为小卷积核的深度卷积,然后是具有相当大卷积核的空洞深度卷积(图2c)。这种类型的大卷积核分解有助于减轻仅具有大卷积核大小的深度卷积所导致的计算成本二次增加的问题。可以如下获得LKA的输出。
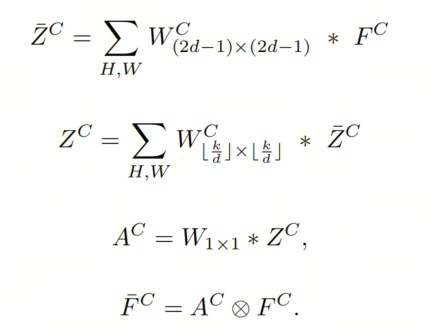
其中d是空洞率。在Eq. 4中, 表示使用卷积核大小为 的深度卷积的输出,该深度卷积捕获了局部空间信息,并补偿了后续空洞深度卷积(Eq. 5)的格栅效应。请注意, 表示向下取整操作。空洞深度卷积负责捕获深度卷积输出 的全局空间信息。尽管LKA设计大大改进了LKA-trivial,但当卷积核大小增加到23×23以上时,它仍会在VAN中导致高计算复杂性和内存占用(见图3)。
3.2. 具有注意力的大可分离卷积核
可以通过将深度卷积和深度空洞卷积的2D权重卷积核分成两个级联的1D可分离权重卷积核来获得LKA的等效和改进配置,如图2d所示。作者将LKA模块的这种修改配置称为LSKA。
按照VAN的方法,可以得到LSKA的输出如下。
类似地,可以以类似的方式获得LKA-trivial的可分离版本,作者将其命名为LSKA-trivial,如图2b所示。从图3可以看出,与LKA-trivial和LKA相比,LSKA-trivial和LSKA都显着降低了VAN的计算复杂性。在接下来的小节中,作者将报告LSKA的属性,以将其与通用卷积、自注意力和LKA模块区分开来。
3.3. LSKA的属性
通过重新审视以前的注意力机制,可以发现LSKA模块相比通用卷积、自注意力和LKA模块具有4个重要属性,如表I所示。
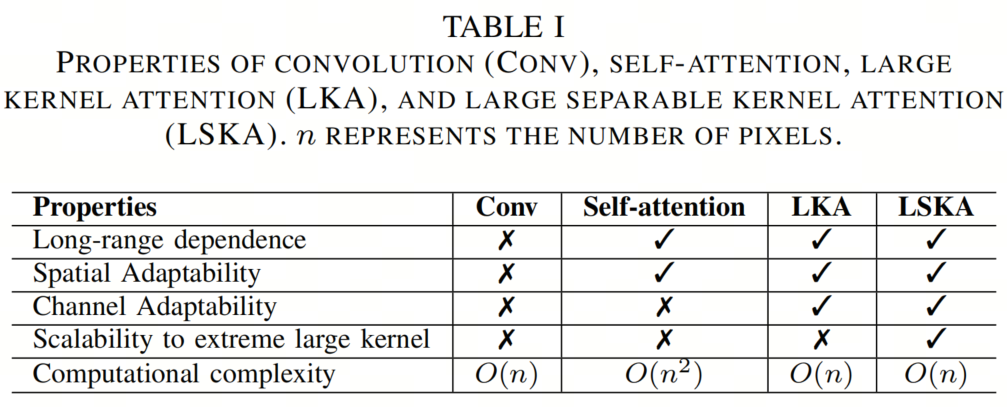
1. 长程依赖性
如第II-B节所述,自注意力机制是使Transformer模型能够捕捉长程依赖性的关键组件。然而,最近的研究表明,大卷积核是捕获全局信息的另一种方法。
为了实现这一目标,作者遵循了LKA在VAN中的设计,该设计将大卷积核分解为两个小卷积核,而不是使用ConvNeXt中的常规大卷积核设计,因为它具有较高的计算开销和优化难度。
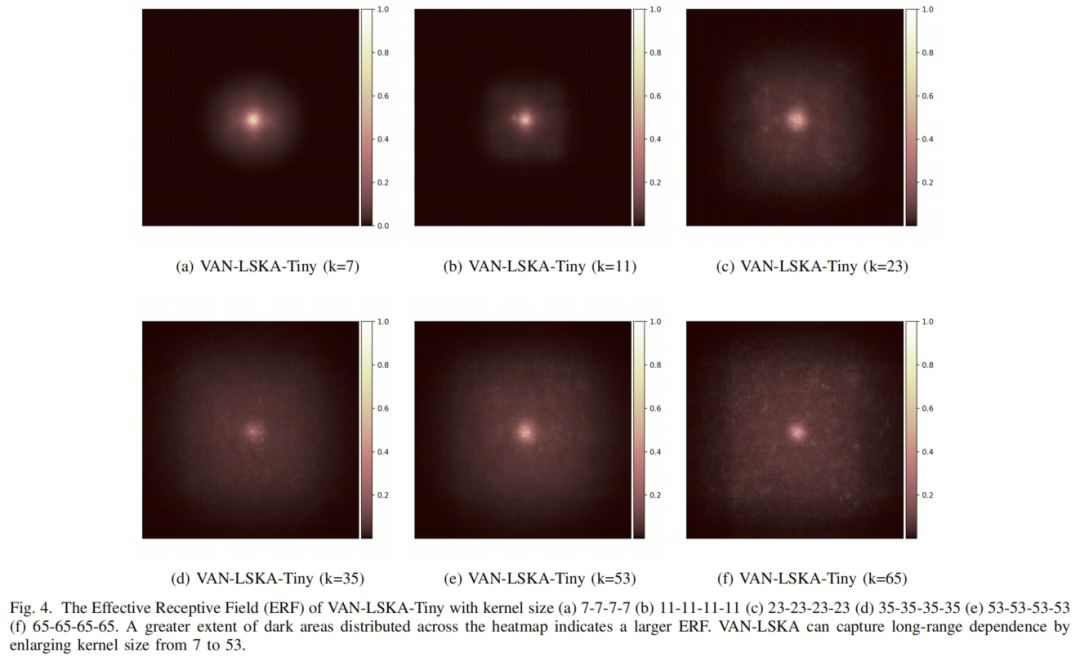
为了验证作者提出的LSKA的长程依赖性,作者利用了RepLK中描述的Effective Receptive Field(ERF)生成方法,生成了VAN-LSKA-Tiny的ERF图,核大小从7到65,如图4所示。分布在Heatmap上的较大面积暗区域表示更大的ERF。从图4a到4f,作者观察到暗区域从核大小7扩展到65,表明LSKA方法可以有效捕捉图像的长程依赖性。
2. 空间和通道适应性
空间注意力和通道注意力是根据上下文依赖性自适应地重新校准特征的权重,如第II-B节所述。作者的工作继承了包含这两种属性的LKA的设计,而与自注意力相比,它具有更低的参数和计算复杂性。
LKA和LSKA之间的区别在于,作者采用级联的水平和垂直卷积核,以进一步减少内存和计算复杂性,如图2d所示。
3. 对极端大卷积核的可扩展性
如图3所示,VAN中的LKA-trivial在卷积核大小增加时会导致计算成本的二次增加。LKA设计大大降低了计算占用,但是模型参数的数量在卷积核大小超过23×23后增加。
当引入最近的SLaK-Decomposed和SLaK-SparseDecomposed方法时,它们在卷积核大小超过100时比LKA具有更低的参数计数和计算占用。请注意,图3中的结果报告了VAN-Small网络。令人惊讶的是,LSKA-trivial和LSKA版本的LKA-trivial和LKA不仅降低了计算成本,而且与LKA和SLaK相比,还保持了VAN模型参数的数量相对恒定。请注意,卷积核大小还指的是最大感受野(MRF)。
关于准确性表现,如表VIII所示,LSKA-Base在卷积核大小从23增加到53时表现出持续增长。相反,LKA-Base在卷积核大小超过23后开始饱和。这些结果表明,LSKA在参数大小、GFLOPs和准确性方面具有对极端大卷积核的可扩展性。
3.4. LSKA的复杂性分析
在这个小节中,作者计算了所提出的LSKA-trivial、LSKA、LKA-trivial和LKA注意力模块的浮点运算(FLOPs)和参数,如图3所示。
请注意,为简化计算,以下分析忽略了偏置项。作者还假设LSKA和LKA的特征图的输入大小和输出大小相同(即H×W×C)。为简洁起见,作者仅提供了计算LSKA和LKA的FLOPs和参数的方程式。然而,相同的方程可以用来计算LKA-trivial和LSKA-trivial的参数和FLOPs。原始LKA的参数和FLOPs可以如下计算:
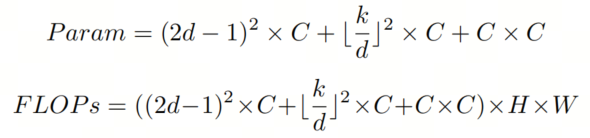
其中k是卷积核大小,d是空洞率。LSKA注意力模块的总FLOPs和参数数量可以如下计算:
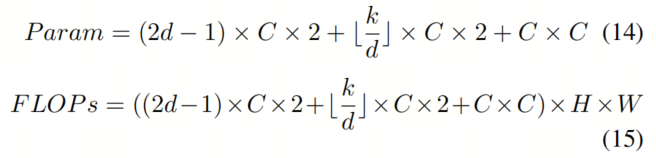
通过将Eq. 14和12的第一项相等,作者可以注意到所提出的LSKA可以在原始LKA设计的深度卷积层中节省 个参数。类似地,通过比较Eq. 14和12的第二项,作者可以看到所提出的LSKA可以在原始LKA设计的空洞深度卷积层中节省 数量的参数。
以FLOPs数量来看,节省与参数相同。可以看出,LSKA在计算上比LSKA-trivial更有效。因此,除非另有说明,作者在与LKA和最先进的方法进行比较时报告LSKA的性能。
3.5. 模型架构
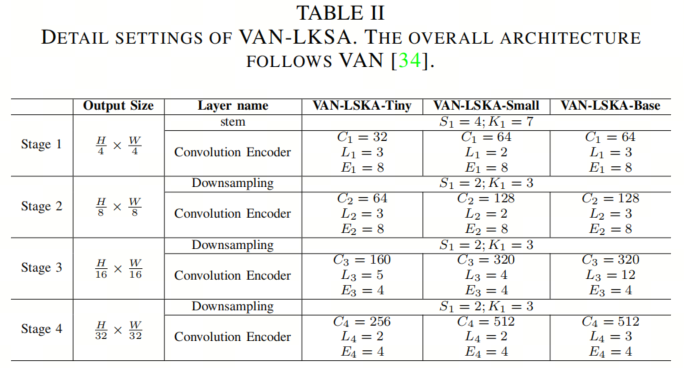
在这项工作中,作者遵循了VAN的架构设计VAN,如表II所示。模型的超参数如下所示:
-
:输入stem和第 阶段下采样中卷积层的Stride;
-
:输入stem和第 阶段下采样中卷积层的卷积核大小;
-
:第 阶段的输出通道数;
-
:第 阶段卷积前馈层的扩展比例;
-
:第 阶段的块数;
按照VAN中的设计,作者的模型包括一个输入干部层和4个后续阶段。输入Stem的第一层包含一个7×7的Stride为4的卷积层,然后是一个批量归一化层。这一层将输入分辨率降低了4倍,并将通道增加到32或64,具体取决于模型的容量。
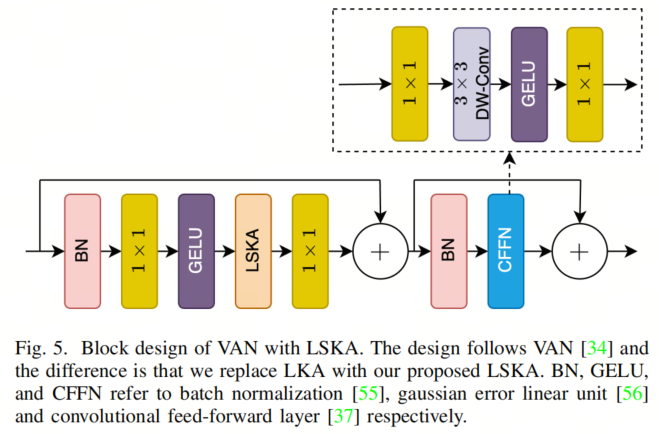
除了第1阶段外,每个阶段都以3×3卷积、Stride2的下采样层开始。然后,它后面是一个卷积块,包括批量归一化、LSKA模块和卷积前馈网络(CFFN),如图5所示。
与常见做法一样,作者的模型在深度卷积之前和之后都包含了一个1×1卷积层,用于通道交互。为了提供更多的非线性,作者在LSKA之前和CFFN内部都添加了GELU激活层。VAN中的LKA和作者的工作之间的主要区别在于,作者用作者的LSKA层替换了每个卷积块的LKA层。
为了提供更多的讨论实例,作者设计了3种不同容量的VAN,分别是VAN-LSKA-Tiny、VAN-LSKA-Small和VAN-LSKA-Base。这些模型包含相同数量的卷积块、通道数和CFFN的扩展比率,与使用LKA的VAN模型进行公平比较,如第IV节中所示。
4、实验
4.1、Image Classification
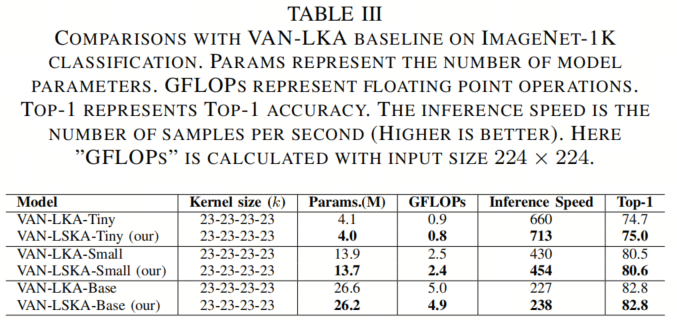
在表III中,作者展示了作者的LSKA在保持与VAN中LKA相似性能的同时,具有更少的参数数量和计算FLOPs。例如,VAN-LSKA-Tiny相比VAN-LKA-Tiny节省了2.4%的参数和11.1%的计算FLOPs,性能略好于VAN-LKA-Tiny。VAN-LSKA-Small与VAN-LKA-Small相比,参数数量和计算FLOPs分别降低了1.4%和4%,性能相媲美。
另一方面,VAN-LSKA-Base在保持与VAN-LKA-Base相同的准确性的同时,参数数量和计算FLOPs分别降低了1.5%和2%。在第V-A节中,作者进一步证明LSKA在速度和准确性的权衡方面优于LKA。
4.2、Object Detection on COCO
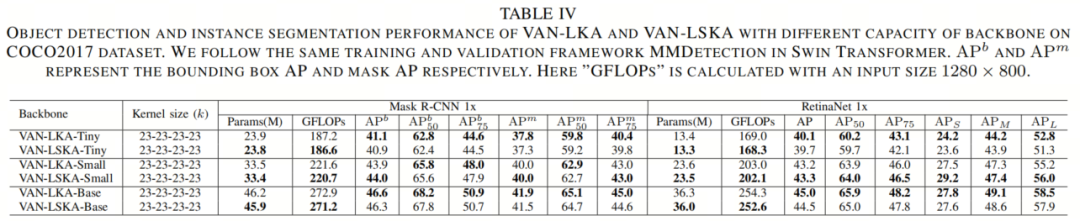
如表IV所示,将所提出的LSKA设计作为Mask R-CNN和RetinaNet的Backbone网络,可以减少模型参数数量和模型FLOPS,同时提供与LKA相似的性能。
例如,当作者将Mask R-CNN用作目标检测器时,VAN-LSKA-Base在与VAN-LKA-Base相比性能相当的情况下,节省了30万参数和2 GFLOPs的计算(46.3与46.6相比仅降低了0.3%)。当作者将目标检测器更改为RetinaNet时,VAN-LSKA-Base在与VAN-LKA-Base相比性能相当的情况下,节省了30万参数和1 GFLOPs的计算(45.0与44.5相比)。
在其他模型容量中也得到了类似的结果。例如,当作者使用Mask R-CNN时,VAN-LSKA-Small有3340万参数和221 GFLOPs的计算时间,比VAN-LKA-Small多了0.1万参数和1 GFLOPs。
4.3、Semantic Segmentation
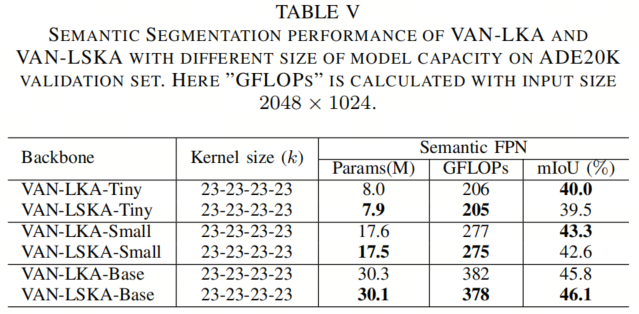
如表V所示,当使用Semantic FPN进行语义分割时,作者发现结果与图像分类和目标检测一致。例如,VAN-LSKA-Base在获得与VAN-LKA-Base相比稍好的性能的同时,节省了20万参数,并将GFLOPS降低了1.05%。
类似地,作者发现VAN-LSKA-Tiny和VAN-LSKA-Small在获得与VAN-LKA-Tiny和VAN-LKA-Small相媲美的性能的同时,节省了10万参数,分别将GFLOPS降低了0.49%和0.36%。
4.4、Robustness Evaluation
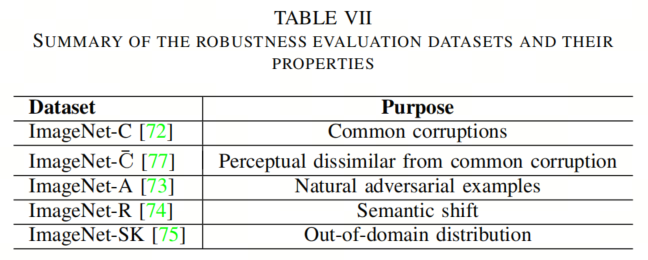
如表VI所示,作者观察到VAN-LSKA在不同参数设置下获得了相当的性能,与VAN-LKA相比只有0.1% -0.6%的差异。与此同时,VAN-LSKA分别在Tiny、Small和Base模型中节省了2.5%、1.4%和1.5%的参数。
同时,VAN-LSKA在Tiny、Small和Base模型中使用的计算时间分别减少了11.1%、4%和2%。这些结果与图像分类、目标检测和语义分割的先前结果一致。
4.5、消融研究
A. 不同大卷积核分解方法的评估
首先,作者进行了一个实验,探讨不同大卷积核分解方法的效果。在这里,作者将LKA、LSKA-trivial和LSKA与LKA-trivial进行了比较,其卷积核大小逐渐增加。
为此,作者按照第IV-A节中描述的设置,在ImageNet-1K分类任务上训练了Tiny模型。作者将卷积核大小(k)不均匀地从7增加到65。作者设置了空洞率d,当k = 7, 11, 23, 35, 53, 65时分别为2, 2, 3, 3, 3, 3。LKA-trivial、LSKA-trivial、LKA和LSKA的卷积核大小的具体设置可以在图2中找到。
需要注意的是,LKA和LSKA的卷积核大小是最大感受野,因为这两个模块都将一个大卷积核分解为两个相对较小的卷积核。作者在图6中报告了所有方法的结果,包括top-1准确度、模型参数、模型FLOPs和推断速度。作者还在附录表XVII中提供了图6的数值结果。
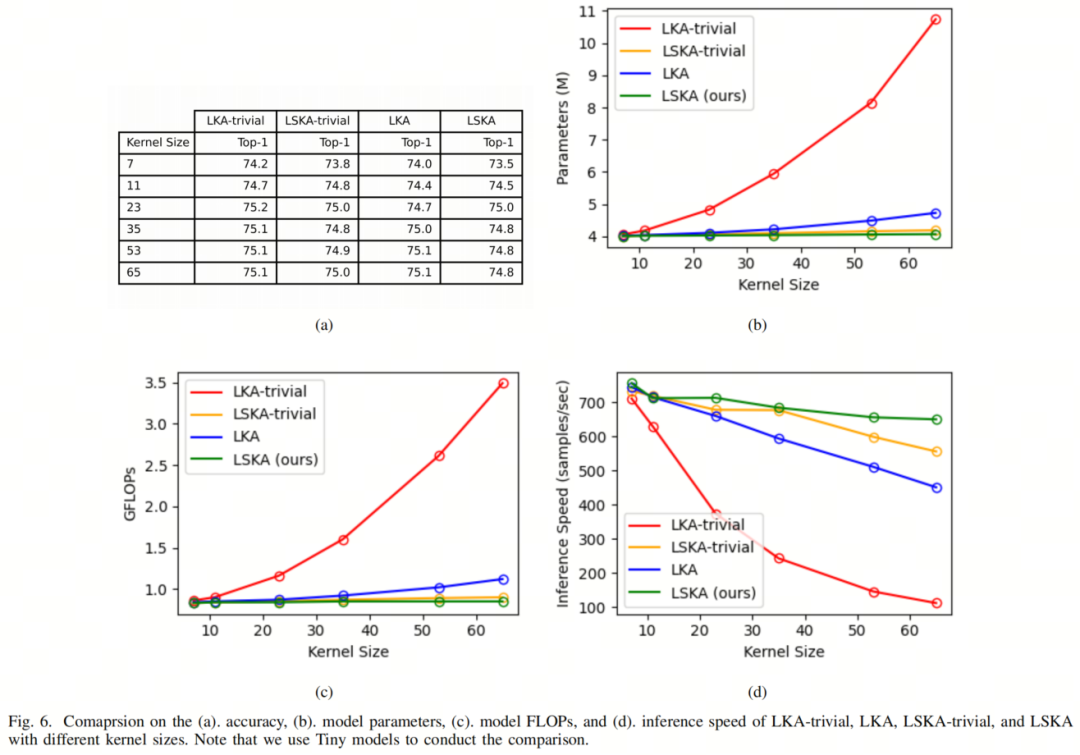
从图6中可以看出,作者提出的方法LSKA-trivial和LSKA在显著降低模型参数和模型FLOPs的同时,实现了与LKA-trivial和LKA相媲美的性能。从图6d中可以看出,作者提出的LSKA-trivial和LSKA在卷积核大小从7×7增加到65×65时,降低了推断速度的降级幅度显著低于LKA-trivial和LKA。
此外,通过比较图6a和图6d,作者可以看出LSKA-trivial和LSKA可以在速度和准确性之间提供更好的权衡。与LKA-trivial和LKA相比,LSKA-trivial和LSKA在保持较低的计算时间的同时,能够实现更大的感受野。
此外,作者观察到LSKA的性能在卷积核大小进一步从23增加到65时略有下降并开始饱和,如图6a所示。作者还可视化了LKA和LSKA的有效感受野,以说明在卷积核大小超过23后性能开始饱和。

相关图可以在附录的图8中找到。这一发现与RepLKNet和SLaK中报告的结果相矛盾,后者观察到在卷积核大小从25增加到31和从31增加到51时性能有所提高。作者推测这种饱和是由于网络宽度和深度不足所致。为了验证这一假设,作者对具有LKA和LSKA的Base模型进行了类似的实验。
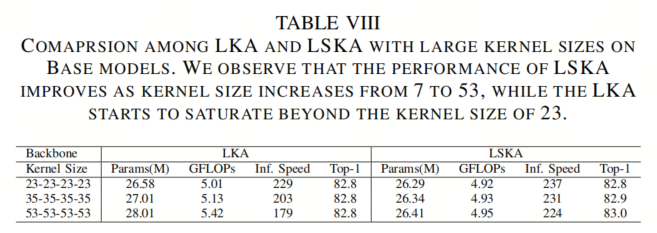
如表VIII所示,作者观察到LKA在卷积核大小超过23后达到饱和点。相反,LSKA在卷积核大小从23增加到53时表现出更好的性能。这一发现与RepLKNet和SLaK一致,证明较大的感受野可以增强长距离依赖性。
B. 在各种下游任务上改变LSKA和LKA的卷积核大小
在第IV-B、IV-C和IV-D节的实验之后,作者探讨了增加卷积核大小对下游任务的影响。在进行目标检测和语义分割的训练以及进行鲁棒性测试之前,作者初始化了在ImageNet-1K上进行了预训练的相应卷积核大小的Backbone模型,如第V-A节所述。其他训练设置和评估方法遵循了相应的任务,如第IV-B、IV-C、IV-D节所述。
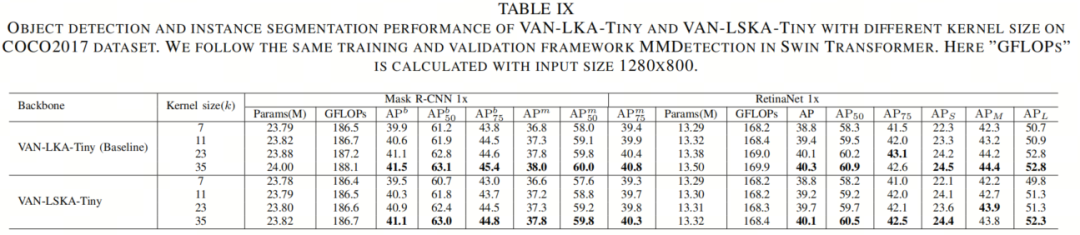
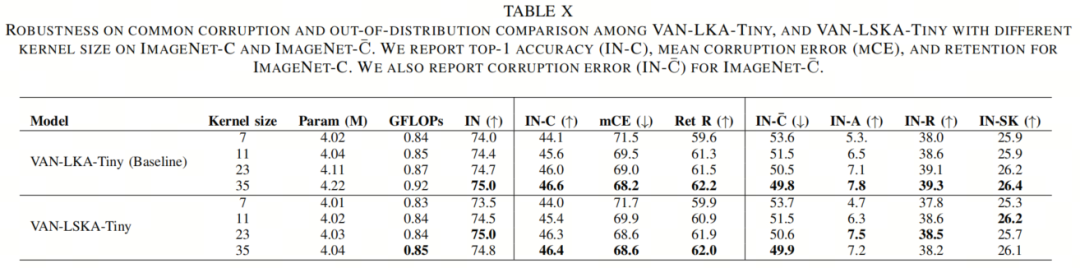
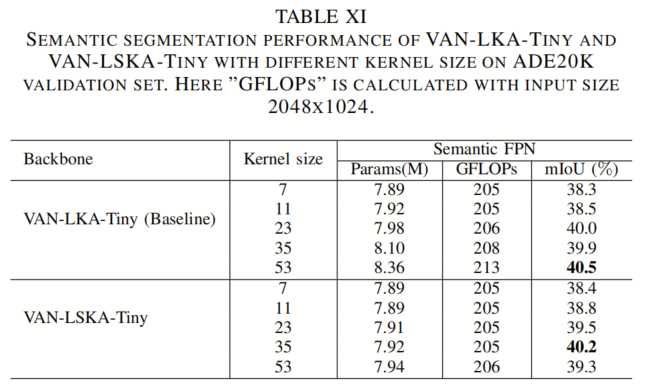
从表IX、表XI和表X中所示的目标检测、语义分割和鲁棒性评估的结果中,作者观察到,当将卷积核大小从7×7增加到35×35时,VAN-LKA-Tiny和VAN-LSKA-Tiny的准确性提高了。
C. 随着卷积核大小的增加,纹理和形状偏差
有趣的是,从表X中作者注意到,具有更大卷积核大小的VAN-LKA-Tiny和VAN-LSKA-Tiny模型在引入受损数据时提供了更好的性能,这表明具有更大卷积核的VAN模型更加健壮。作者推测,这种现象发生是因为随着卷积核大小的增加,VAN模型对目标的形状比纹理更加偏向。
基于形状的表示对下游任务更有益,因为GT标签(如边界框和分割地图)与目标形状保持一致。
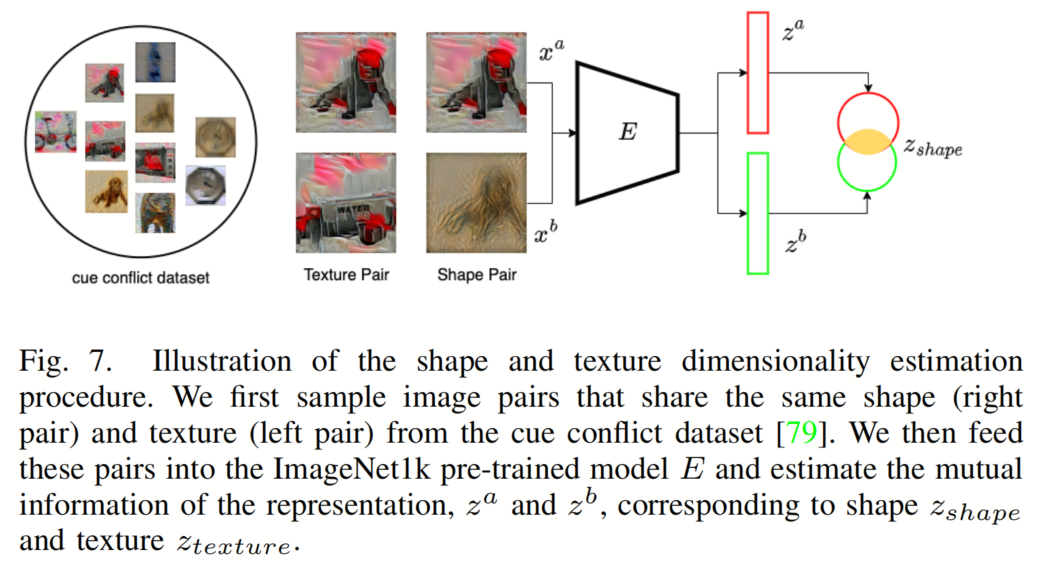
为了验证增加卷积核大小是否使VAN模型更加偏向形状而不是纹理,作者遵循[Shape or texture]中的方法来评估VAN-LKA-Tiny和VAN-LSKA-Tiny模型的潜在表示中包含的形状和纹理信息的量。主要思想是,如果两幅图像之间存在相似的语义属性(如形状、纹理、颜色等),则这两幅图像之间的互信息仅在模型捕捉到这些语义属性时才会在潜在表示中保留。在这个实验中,作者使用了纹理-形状线索冲突数据集,该数据集由风格转移生成,由1280个纹理-形状线索冲突图像组成,形成了一对图像,它们具有相似的语义属性形状或纹理,用于估算两者信息的维度。
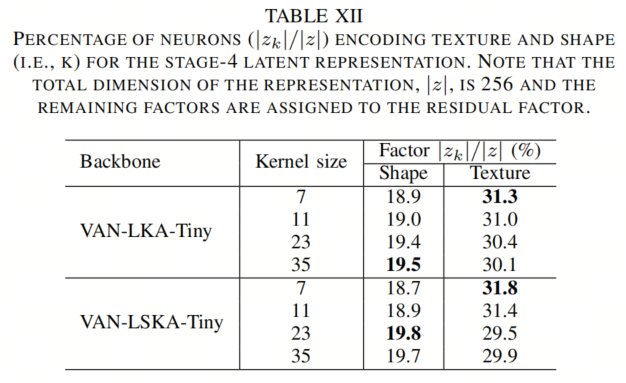
如表XII所示,随着卷积核大小的增加,VAN-LKA-Tiny和VAN-LSKA-Tiny编码了更多的形状信息,同时编码了较少的纹理信息。这个结果表明卷积核大小与编码的形状信息的数量之间存在关联。
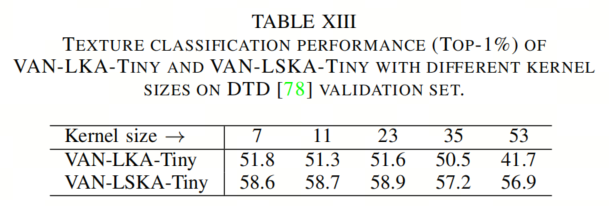
为了研究LSKA和LKA对图像纹理分析的影响,作者使用可描述纹理数据集(DTD)进行了纹理分类实验,该数据集包含5640幅图像,共47个类别。作者通过在VAN-LKA-Tiny和VAN-LSKA-TinyBackbone上使用KNN分类器执行纹理分类任务,其中K = 1,并报告了验证集上的top-1准确性。
如表XIII所示,随着卷积核大小从7增加到53,LSKA和LKA的性能都下降了。值得注意的是,当卷积核大小从35增加到53时,LSKA的性能下降相对较小,而LKA的性能下降较大。
4.6、SOTA对比
在本节中,作者将VAN-LSKA与最先进的基于CNN的模型(即ConvNeXt、RepLKNet、SLaK和VAN-LKA VAN)以及基于Transformer的模型(即DeiT、PVT、PVTv2和Swin Transformers)进行了在ImageNet分类、ImageNet-C鲁棒性测试、COCO目标检测和ADE20K语义分割方面的比较。
为了与其他ViTs和CNNs进行公平比较,作者将RepLKNet-31B模型从79M参数降级为具有29.7M参数的RepLKNet-31T模型。这个降级包括将模型的通道大小分别减小到64、128、320和512,用于模型的4个阶段。
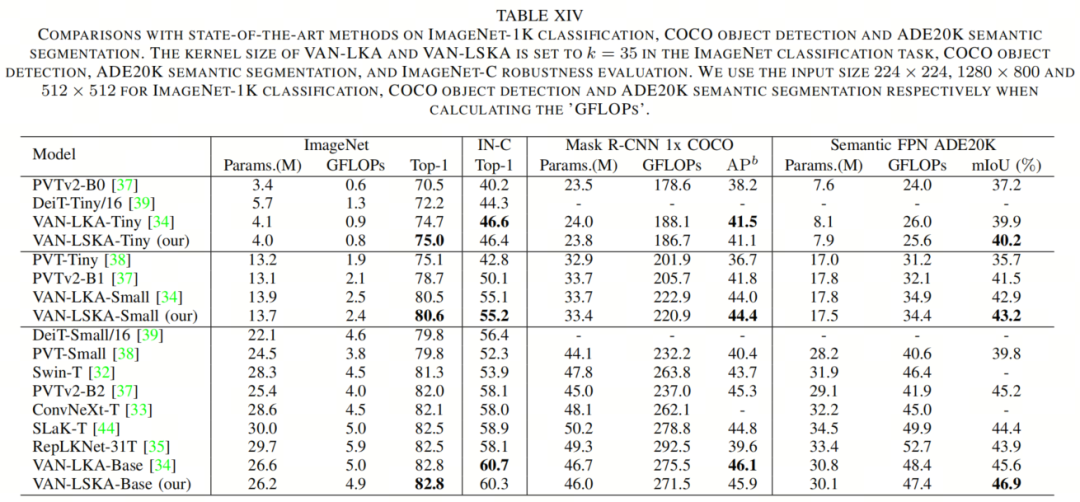
如表XIV所示,作者提出的VAN-LSKA网络的Tiny、Small和Base版本在ImageNet分类、目标检测、语义分割和鲁棒性评估类别中优于ViTs。例如,所提出的方法在分类上超过Swin Transformer(Swin-T)1.5%的准确性,同时节省7.4%的参数。这个性能差距在鲁棒性评估和目标检测方面进一步扩大,分别为6.4%和2.2%。作者提出的方法还在ImageNet分类和ImageNet-C鲁棒性评估方面分别超过了基于大卷积核的ConvNext 0.7%和2.3%,同时节省8.4%的参数。与最新的RepLKNet和SLaK方法相比,作者的方法在ImageNet分类准确性上超过了这两种方法的0.3%。
此外,在ImageNet-C数据集上,作者的方法分别比RepLKNet和SLaK改进了2.2%和1.4%。值得注意的是,与这两种方法相比,作者的方法可以节省11.7%和12.6%的参数大小。作者推测,提出的VAN-LSKA方法与最先进的ViTs和CNN架构之间的性能差异是由于VAN中的LSKA模块使大的感受野(例如,35×35)变得可能。
这种使用大卷积核尺寸提高了形状偏差,同时降低了纹理偏差,如第V-C节中所述,这已经被证明可以提高性能。作者在表XV中报告了VAN-LSKA、VAN-LKA、ViTs和基于CNN的架构的纹理和形状维度。
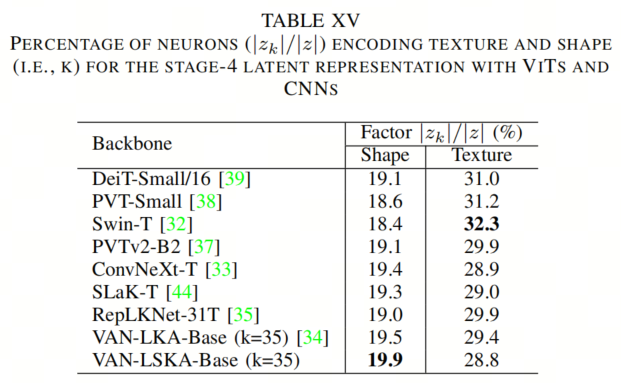
从表XV中可以看出,VAN-LSKA(卷积核大小为35×35)的形状维度更高,纹理维度更低,比VAN-LKA、ConvNeXt、RepLKNet、SLaK和ViTs更支持大卷积核尺寸提高性能的证据。
与VAN-LKA相比,所提出的方法在分类、鲁棒性评估、目标检测和语义分割任务上取得了可比较的性能。然而,与VAN-LKA相比,VAN-LSKA获得了更低的参数大小和GFLOPs。
4.7、形状和纹理维度估计方法
作者遵循[Shape or texture]中的方法来估计潜在表示中编码的形状和纹理信息。给定一对图像 ,它们共享相似的语义因素(即形状或纹理),作者的目标是估计由预训练模型E编码的潜在向量 中语义因素的维数。仅当模型E能够捕获图像对的互信息(MI)时,图像对的互信息(即形状或纹理)才会保留在表示z中。
因此,基于这样一个简单的假设,即潜在表示中神经元 和 的联合分布是双变量正态分布,作者可以估计它们的互信息(MI),其中相关系数 如下所示:
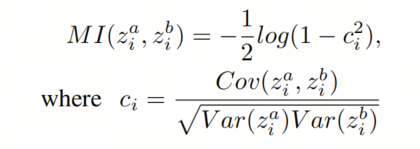
为了估计代表形状和纹理的神经元数,将它们各自的相关系数 和 相加,得到最终分数 和 。由于相关系数被限制在[-1, 1]之间,分数 和 在[-N, N]之间,其中N是潜在表示的维数。为了确保语义因素的所有维度之和等于潜在表示的维数N,作者在最终分数向量 上应用softmax函数,其中k表示语义因素(即形状和纹理)。
请注意,未包括在这两个语义因素中的其余维度被分配为剩余语义因素。最后,语义因素的维数 可以按如下计算:
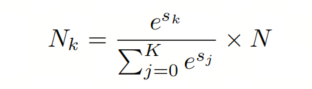
其中K = 3表示形状、纹理和剩余因素。图7显示了形状和纹理维度估计过程的详细信息。
4.8、对VITS和CNNS的稳健性评估
作者进一步提供了ViTs和CNNs之间的鲁棒性比较,如表XVI所示。作者按照第IV-D节中提到的评估步骤,直接在ImageNet-C、ImageNet-A、ImageNet-R和ImageNet-SK上测试了预训练的ImageNet-1k模型。
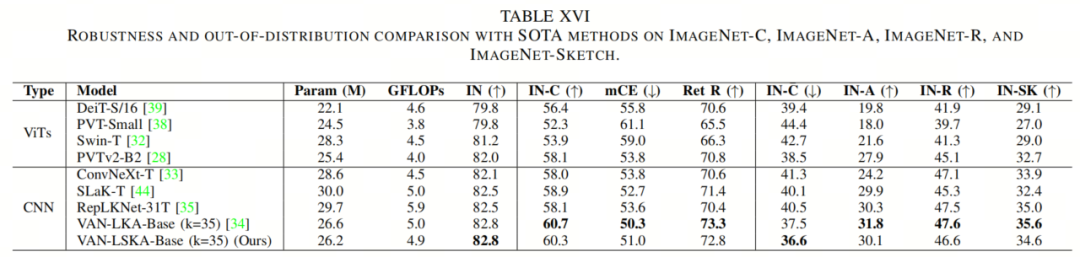
与ViTs相比,VAN-LSKA在所有数据集上均优于所有最先进的基于Transformer的模型。这个结果与作者在前面的VI节中的发现一致。与CNNs相比,VAN-LSKA在大多数数据集上的性能优于ConvNeXt、RepLKNet和SLaK,同时节省8.4%、11.7%和12.6%的参数。与VAN-LKA模型相比,作者的模型在参数大小和GFLOPs更低的情况下实现了可比较的性能。

5、参考
[1]. Large Separable Kernel Attention: Rethinking the Large Kernel Attention Design in CNN.
6、推荐阅读
大模型系列 | 两张3090显卡就可以玩起来医疗SAM-LST大模型
南科大提出ORCTrack | 解决DeepSORT等跟踪方法的遮挡问题,即插即用真的很香
CSUNet | 完美缝合Transformer和CNN,性能达到UNet家族的巅峰!

扫码加入👉「集智书童」交流群
(备注:方向+学校/公司+昵称)




前沿AI视觉感知全栈知识👉「分类、检测、分割、关键点、车道线检测、3D视觉(分割、检测)、多模态、目标跟踪、NerF」
欢迎扫描上方二维码,加入「集智书童-知识星球」,日常分享论文、学习笔记、问题解决方案、部署方案以及全栈式答疑,期待交流!