
最新955不加班名单
点击关注公众号,SQL干货及时获取
一、955不加班名单
一个拥有 33.8k star 数的项目,点进去一看,居然没有任何代码,这个 955.WLB 项目究竟拥有什么魔力?
955.WLB 中 的 955 指的是工作制度,与我们熟知的 996 类似,955 即早九晚五,每周工作五天;而 WLB 呢?其实是英文 Work Life Balance 的缩写,也就是工作和生活的平衡。
这是一份由全国各地大小公司的程序员们合力贡献的名单,上面罗列了全国 955 工作制不加班公司的名单。
而作者也提示到,并不是所有在榜的公司都是绝对的 955,可能有些许偏差,但基本都不属 996。而作者本人身处上海,对本地的情况更了解,所以在榜的公司,居上海的占很大一部分。
Afterpay - 上海
Airbnb - 北京
Amazon - 北京/上海
AMD - 上海
Apple - 北京/上海
ArcSoft - 杭州
ARM - 上海
Autodesk - 北京/上海
Booking - 上海
Calix - 南京
Canva - 北京/武汉
Cisco - 北京/上海/杭州/苏州
Citrix - 南京
Coolapk (酷安) - 北京/深圳
Coupang - 北京/上海
CSTC (花旗金融) - 上海
Dell - 上海
Douban (豆瓣) - 北京
Duolingo - 北京
eBay - 上海
eHealth - 厦门
Electronic Arts - 上海
EMC - 上海
EPAM Systems - 上海/深圳/苏州/成都
Ericsson - 上海
Flexport - 上海/深圳
FreeWheel - 北京
GE - 上海
Google - 北京/上海
Grab - 北京
Honeywell - 上海
HP - 上海
HSBC - 上海/广州/西安
Hulu - 北京
IBM (GBS除外) - 北京/上海
iHerb - 上海
Intel - 北京/上海/深圳
LeetCode - 上海
LEGO Group - 上海
Linkedin - 北京
Micro Focus - 上海
Microsoft - 北京/上海/苏州
MicroStrategy - 杭州
Morgan Stanley (IT) - 上海
National Instruments - 上海
Nike - 上海
Nokia - 上海/南京/杭州
Nomura - 上海
NVIDIA - 北京/上海
Optiver - 上海
Oracle - 上海
PayPal - 上海
Philips - 上海/苏州
Pivotal - 北京/上海
Qualcomm - 北京/上海
Rakuten - 上海/大连
Red Hat - 北京/上海/深圳/西安/remote
RingCentral - 厦门/杭州/香港
Rippling - 北京/上海
SanDisk - 上海
SAP - 上海
SmartNews - 北京/上海
Snap - 北京/深圳
State Street - 杭州
SUSE - 北京/上海/深圳
The Trade Desk - 上海/深圳
ThoughtWorks - 西安/北京/深圳/成都/武汉/上海/香港
Trend Micro - 南京
Tubi - 北京
TuSimple - 北京/上海
Two Sigma - 上海
Ubisoft - 上海
Unity - 上海
Vipshop (唯品会) - 上海
VMware - 北京/上海
WeWork - 上海
Wish - 上海
Works Applications - 上海
XMind - 深圳
Zhihu (知乎) - 北京
Zoom - 合肥/杭州/苏州
这只是名单的一部分,不难找到许多熟悉的公司名字。
项目主页readme上很醒目的一句话:
旨在让更多的人逃离 996,加入 955 的行列。
或许,这份项目如此高的 star 数,就是程序员们试图逃离 996 工作制,对美好的 955 生活的期盼吧。
项目地址:
https://github.com/formulahendry/955.WLB
二、SQL中如何删除重复数据问题
需求分析
数据库中存在重复记录,删除保留其中一条(是否重复判断基准为多个字段)
解决方案
碰到这样的问题我们先分解步骤来看 创建测试数据
找到重复的数据
删除重复的数据并且保留一行
创建测试数据
我们创建一个人员信息表并在里面插入一些重复的数据。
CREATE TABLE [dbo].[Person](
[ID] [INT] IDENTITY(1,1) NOT NULL,
[Name] [VARCHAR](20) NULL,
[Age] [INT] NULL,
[Address] [VARCHAR](20) NULL,
[Sex] [CHAR](2) NULL
);
SET IDENTITY_INSERT [dbo].[Person] ON;
INSERT INTO [dbo].[Person] (ID,Name,Age,Address,Sex)
VALUES
( 1, '张三', 18, '北京路18号', '男' ),
( 2, '李四', 19, '北京路29号', '男' ),
( 3, '王五', 19, '南京路11号', '女' ),
( 4, '张三', 18, '北京路18号', '男' ),
( 5, '李四', 19, '北京路29号', '男' ),
( 6, '张三', 18, '北京路18号', '男' ),
( 7, '王五', 19, '南京路11号', '女' ),
( 8, '马六', 18, '南京路19号', '女' );
SET IDENTITY_INSERT [dbo].[Person] OFF;
(提示:可以左右滑动代码)
建立好测试数据如下:
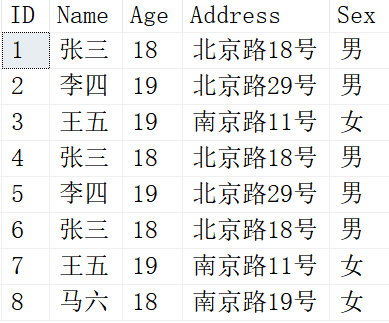 Person
Person
我们发现除了自增长ID不同以为,有几条其他字段都重复的数据出现,符合我们的需求。
找出重复的数据
SELECT MAX(ID) ID ,
Name,Age,Address,Sex
FROM dbo.Person
GROUP BY Name,Age,Address,Sex
HAVING COUNT(1)>1
HAVING将分组后统计出来的数量大于1的数据行,就是我们要找的重复数据:

上面用Max函数或者Min函数均可,只是为了保证取出来的数据的唯一性。
删除重复的数据
其实我们数据库中最后要保留的结果就是第二步中查询出来的数据,我们把其他的数据删除即可。怎么删除呢?我们使用ID来排除。
DELETE FROM Person
WHERE EXISTS
(
SELECT * FROM (
SELECT
MAX(ID) ID,
Name,Age,Address,Sex
FROM dbo.Person
GROUP BY Name,Age,Address,Sex
HAVING COUNT(1)>1) T
WHERE Person.Name=T.Name
AND Person.Age=T.Age
AND Person.Address=T.Address
AND Person.Sex=T.Sex
AND Person.ID<T.ID--如果上面使用MIN函数,这里就要改成>
)
执行完后重新查询Person表结果如下:
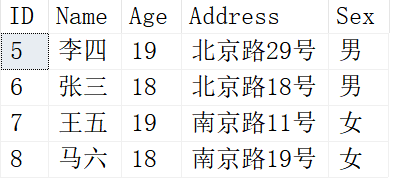
马六因为只有一条记录,所以没有参与去重,直接显示。
今天的案例分享结束,小伙伴们可以自己动手尝试一下,兴许工作中也会遇到类似问题。如果你在公众中遇到一些有趣的问题也可以发送给我。
最后给大家分享我写的SQL两件套:《SQL基础知识第二版》和《SQL高级知识第二版》的PDF电子版。里面有各个语法的解释、大量的实例讲解和批注等等,非常通俗易懂,方便大家跟着一起来实操。
有需要的可以下载学习,只需要在下面的公众号「 数据前线 」 (非本号), 后台回复关键字: SQL ,就行
数据前线
后台回复关键字: 1024 ,获取一份精心整理的技术干货 后台回复关键字:进群,带你进入高手如云的交流群。
推荐阅读
- MySQL这样写UPDATE语句,劝退!
- 离谱,北邮211本科不符合华为OD要求
- 网友:财富全被大厂程序员攫取了,程序员应当主动降薪。。。
- 一个小公司的技术开发心酸事,已倒闭。
- 什么奇葩招聘要求:我有四不招???
文章有帮助的话,点个赞或在看吧。
谢谢支持