
对视觉大语言模型一致性分析:当GPT-4V不能与文本意见一致时,它迷失在翻译之中了!
共 10067字,需浏览 21分钟
· 2023-10-30
点击下方卡片,关注「集智书童」公众号

多模态技术的最新进展为在涉及文本、音频和图像处理的各种任务中表现出色的模型开辟了令人兴奋的可能性。像GPT-4V这样将计算机视觉和语言建模相结合的模型,在复杂的文本和图像任务中表现出色。许多以前的研究努力审查了这些视觉大语言模型(VLLMs)在诸如目标检测、图像描述等任务中的表现。然而,这些分析通常集中在评估每种模态在孤立环境下的性能,缺乏对它们之间跨模态交互的深入洞察。
具体而言,有关这些视觉-语言模型是否在执行视觉和语言任务时表现一致还是独立执行的问题一直没有得到回答。在这项研究中,作者从最近关于多语言性的调查中汲取灵感,进行了对模型的跨模态交互的综合分析。作者引入了一个系统化的框架,用于量化多模态环境中不同模态之间的能力差异,并提供了一组专为这些评估而设计的数据集。
作者的研究发现,像GPT-4V这样的模型在任务相对简单的情况下倾向于执行一致的模态。然而,随着任务变得更具挑战性,从视觉模态导出的结果的可靠性逐渐降低。在作者的研究基础上,作者介绍了“视觉描述提示”的方法,这种方法有效地提高了在具有挑战性的视觉相关任务中的性能。
1. 简介
最近的大型多模态模型展示了在需要整合多种模态和信息来源的任务中的卓越能力。其中,视觉大语言模型(VLLMs)的性能表现出色,这要归功于大量用于训练的图像和文本数据,以及计算机视觉和语言建模的快速进展。然而,由于这些模型采用不同的训练方法,如对比学习和具身形象语言建模,以及每种模态的训练数据质量不同(例如,包含图像质量不同但具有丰富文本内容的数据),这些网络通常在不同模态之间表现出性能差异。这导致了在视觉任务或其他任务中的性能提升,具体取决于特定模型和训练条件。
以往的研究已经广泛评估了多模态系统中各个模态的性能。例如,杨等人(2023年)对GPT-4V的视觉理解能力进行了彻底评估,而陈等人(2023年)分析了其决策能力。然而,仅评估模型在每个独立模态上的性能并不能完全捕捉其真正的多模态能力。一个模型可能在许多视觉任务中表现出色,但在语言理解方面明显滞后。这种差异通常可以归因于训练数据的不平衡或每种模态的训练范式的差异。此外,仅仅在单个任务上测试性能并不能提供有关模型的每种模态如何影响其他模态的见解。不幸的是,在前述研究中,跨模态关系经常被忽视。
在这项研究中,作者的方法超越了传统做法,即仅仅评估不同下游任务中的多模态系统,并随后呈现测试分数。相反,作者的主要重点是量化不同模态之间的能力差异,特别关注视觉和语言,其中一个VLLM。为了进行全面的分析,作者将视觉-语言任务分为两个不同的组别:变换相关任务和变换无关任务,具体取决于信息在从一种模态转换到另一种模态时是否保持完整性。
在每个类别中,作者创建了包含显示视觉和语言能力不同方面的任务对的数据集。作者使用一种成对一致性度量来衡量视觉和语言之间的差异。此外,作者使用定制的提示来调查模型对两种模态的内部推理,旨在揭示网络的跨模态表示和相互影响。对GPT4V进行的实验表明,它在视觉和语言之间的表现高度不一致,如果任务在一种模态中执行而不是另一种模态,性能会在很大程度上有所不同。
贡献如下:
-
作者引入了一种新颖的评估框架,用于评估大型多模态系统中不同模态之间的性能一致性,提供了超越传统指标的洞见,揭示了它们的交互作用和差异。 -
作者发布了6个多样化的、精心制作的视觉-语言一致性测试数据集,促进未来的研究。 -
作者在GPT-4V模型上的实验揭示了在这种系统内视觉和语言能力之间的显著差异,引发了视觉文本提示(VDP)方法的引入作为潜在的解决方法。
2. 视觉语言模型类型的多语言观点
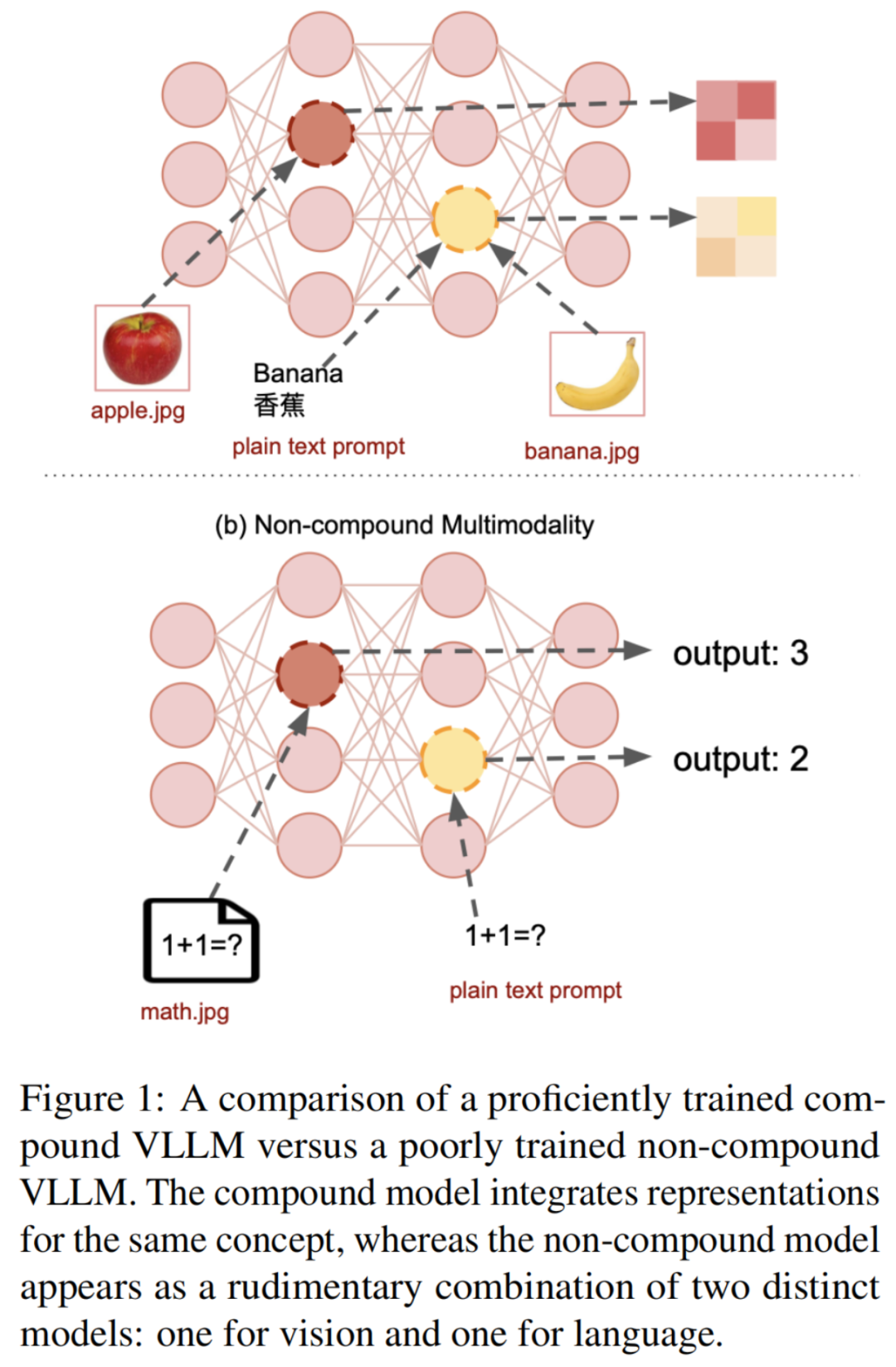
与人类大脑在作者的发展年龄中自然整合视觉和语言信息的方式不同,其中口头语言通常与相应的视觉线索相一致,训练模型以无缝地合并这两种类型的信息已被证明是一项巨大的挑战。如果一个多模态系统没有得到适当的训练,可以将其视为由几个独立网络的基本组合,每个网络处理不同的模态(见图1的b部分)。尽管对每种模态特定任务的性能可能是合理的,但由于跨模态信息交流有限,往往需要繁琐的“翻译”过程,因此远未能实现最佳系统。这种限制通过错误变得明显,其中一些错误在图2中有所说明。

为了更好地理解VLLMs如何表示多模态信息,作者从最近有关LLMs的多语言能力的研究中获得了一些见解。作者将语言和视觉概念化为两种类似于需要习得的不同人类语言。在语言理论中,如果一个人拥有两种语言能够访问共享的内部表示,而这两种语言之间没有明显的区别,那么他被认为拥有复合双语能力。这种现象通常发生在同时习得两种语言的环境中的个体身上。相反,如果两种语言之间存在明显区别并且对个体来说表现出不同,那么作者将一个双语者称为非复合双语。对于大多数成年人的第二语言学习者来说,后一种情况通常是真实的,因为他们使用不同的内部系统来处理这两种语言,而语言切换经常涉及低效的翻译过程。
正如以前的研究所指出的,由于大型成对多语文本语料库的稀缺性,复合多语言大语言模型的存在异常罕见。这些模型在不同语言语料库上的训练往往相对独立,几乎没有语言之间的交叉。正如(Zhang等人,2023b)所展示的那样,这些模型通常通过将任务翻译成它们的主导语言来处理多语言任务。然而,对于VLLMs是否也如此尚不确定。这是因为多模态模型的训练通常涉及不同的技术并利用更多特定于感兴趣的模态的成对数据集(例如,带有字幕的图像)。作者的调查重点不是LVLMs在个别任务中的性能,而是评估它们在视觉和语言之间的复合级别。作者希望这种分析为未来关于这些模型的使用的研究提供有价值的建议。
3. 基于翻译可变性的任务分类
为了实现跨模态一致性分析,作者采用了受多语言研究启发的分类框架,并引入了一种新的范式来对任何给定的下游任务进行分类。作者根据在将核心任务求解所必需的信息转换到另一种模态时是否保留来将任务分类为“翻译可变”(TV)或“翻译不变”(TI)。
“不变性”概念涉及在经历输入转换时保持其行为或响应一致的操作。在作者的背景下,当从一种模态翻译输入信号到另一种模态时,“不变性”意味着这种翻译不会导致解决者的输出发生任何变化。
正式来说,考虑一个被表示为 的转换函数,将图像转换为文本描述,如果在应用此翻译后,多模态系统 预计会产生与以前相同的结果,那么视觉任务在 操作下被认为是“翻译不变”的:
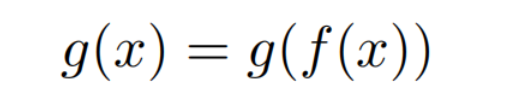
这一概念也适用于语言任务和其他模态的任务。
对于TI任务,任务实例通常在模态之间进行翻译时保留其信息。这种保留确保了通过完美的复合系统在任何模态中解决任务时没有实质性的差异。
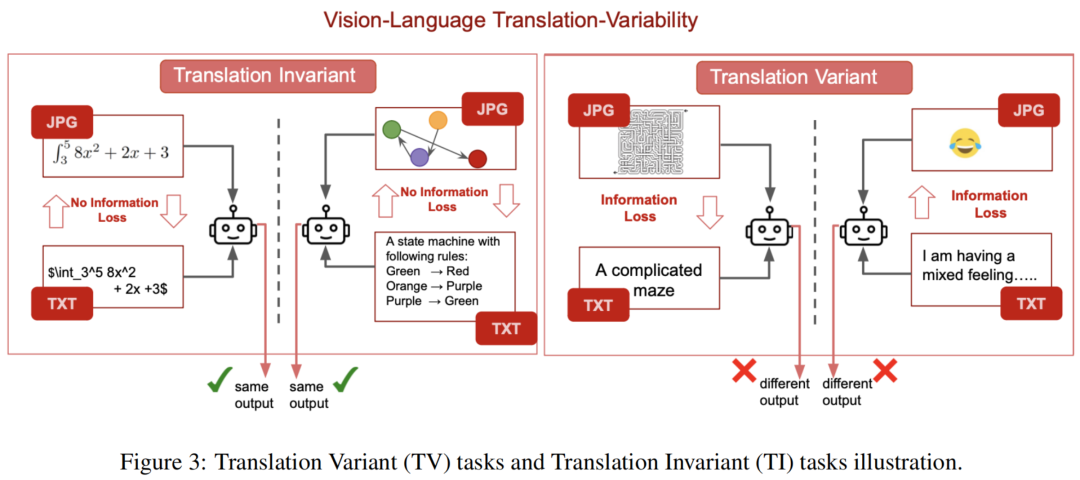
相反,对于TV任务,任务的核心信息通常在翻译过程中丢失,这会增加在一种模态中解决任务相对于另一种模态的难度。作者在图3中举例说明了TI和TV任务,更详细的细节将在关于数据集构建的第5.1节中提供。
4. 方法
在这一部分中,作者将重点放在视觉大型语言模型上,并详细介绍了作者用于量化给定系统内视觉和语言模态之间一致性的方法。
4.1 评估跨模态一致性的框架
正如先前提到的,独立评估每种模态的性能提供的洞见有限。为了解决这个问题,作者提出了一种考虑任务成对基础的评估方法。然而,对于TV任务,由于这些任务在以不同模态呈现相同任务实例时预期产生不同的结果,因此在量化测量模型本身引起的结果差异方面可能会有一定挑战。
相反,作者的重点是TI任务,其中结果的差异不受信息模态的影响。在TI任务中,作者期望如果一个训练良好的复合模型应用于同一实例,结果将是相同的。因此,通过测量相同实例的成对结果,作者可以评估模型模态之间的差异。
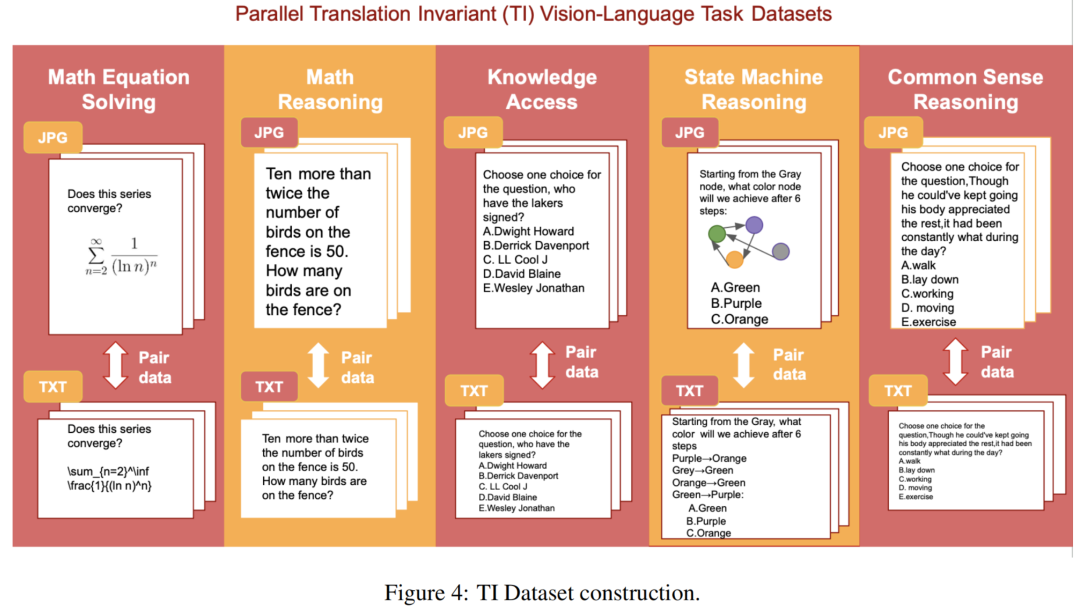
对于TI(翻译不变)任务,作者的过程涉及获取一对任务实例,如第5.1节中详细说明的,并如图4所示,其中一个实例使用图像,另一个使用文本进行任务描述。
重要的是,这两个实例包含了解决任务所需的相同数量的信息,如图3中对TI任务的说明。然后,作者分别使用图像和文本在两个不同的会话中提示多模态系统,以避免信息交叉。随后,作者通过确定图像结果和文本结果都是正确或不正确的实例的比例来计算成对准确度。这个度量提供了模态之间一致性分数的强有力指示。
5. 实验
5.1 根据提出的框架构建视觉-语言评估数据集的方法
由于目前没有可用的平行视觉语言任务数据集,作者承担了构建作者自己数据集的任务。作者创建了5个“翻译不变”(TI)任务数据集和1个“翻译可变”(TV)任务数据集。作者已经公开提供了这个数据集,供未来的研究使用。
5.1.1 TI任务数据集
数学方程求解
在数学方程求解的背景下,图像特别适用于表示数学方程,提供了复杂符号和符号的清晰可视化。为了便于这项任务,作者策划了一个包含各种数学符号和表达式的数学问题图像的数据集。
值得注意的是,这个任务天生是翻译不变的,因为作者可以使用LATEX文本格式保留解决问题所需的所有必要信息。因此,作者将所有基于图像的数学问题与其相应的文本表示进行配对,以创建作者的最终方程求解数据集。这种构建的示例可以在图4中看到,数据样本如下:


数学推理
对于数学和逻辑推理任务,作者利用了GSM8K数据集,该数据集包含了8,500个此类问题(7,500个用于训练,1,000个用于测试)。为了实现多模态分析,作者将这些问题中的每一个都转换成了格式良好的图像文件。然后,将生成的图像和原始文本文件配对,以创建一个平行数据集,可以在图像和文本两种模态下探讨这个任务。这种构建的示例可以在图4中看到,数据样本如下:


知识访问
为了评估视觉和文本模态之间获取事实知识能力的差异,作者使用了WebQuestions数据集来创建一个知识访问平行数据集。这个数据集包含了6,642个以文本格式提出的问题。
这类问题的一个示例是:“Justin Biber在哪个国家长大?”为了实现多模态分析,作者再次将每个问题转换成图像文件格式,然后将其与原始文本进行配对,从而创建一个数据集,允许在图像和文本模态下探索知识访问。这种构建的示例可以在图4中看到,数据样本如下:


常识推理
为了调查不同模态在使用时可能存在的常识推理差异,作者创建了一个基于CommonsenseQA数据集的平行数据集。这个数据集包含12,247个多项选择题,每个都已经转换成了图像格式,并且在问题下显示了所有答案选择。作者将这些图像与原始文本问题进行配对,以便在文本和图像两种模态下研究常识推理。这种构建的示例可以在图4中看到,数据样本如下:


状态机推理
状态机可以有效地可视化为图形或通过具有过渡规则的文本表示,这是评估VLLMs推理能力的理想试验台。作者的方法包括生成不同节点总数(状态)的状态机的图像。状态机中的每个节点都分配了不同的颜色,并且具有一个出口边,确保唯一的路径和解决方案。
作者提出的问题的形式是:“从灰色开始,经过n步,作者将最终到达哪个颜色?”在这里,n是作者选择的一个变量。此外,作者生成了这些状态机的文本版本,列出了每个箭头的所有过渡规则。为了防止通过查看文本中的最后状态来作弊,作者会打乱规则的顺序。
作者创建了具有不同状态数量和问题具有不同步数的状态机以引入不同的难度级别。与这些状态机问题相对应的文本-图像对构成了作者的状态机推理的最终数据集。这种构建的示例可以在图4中看到,数据样本如下:
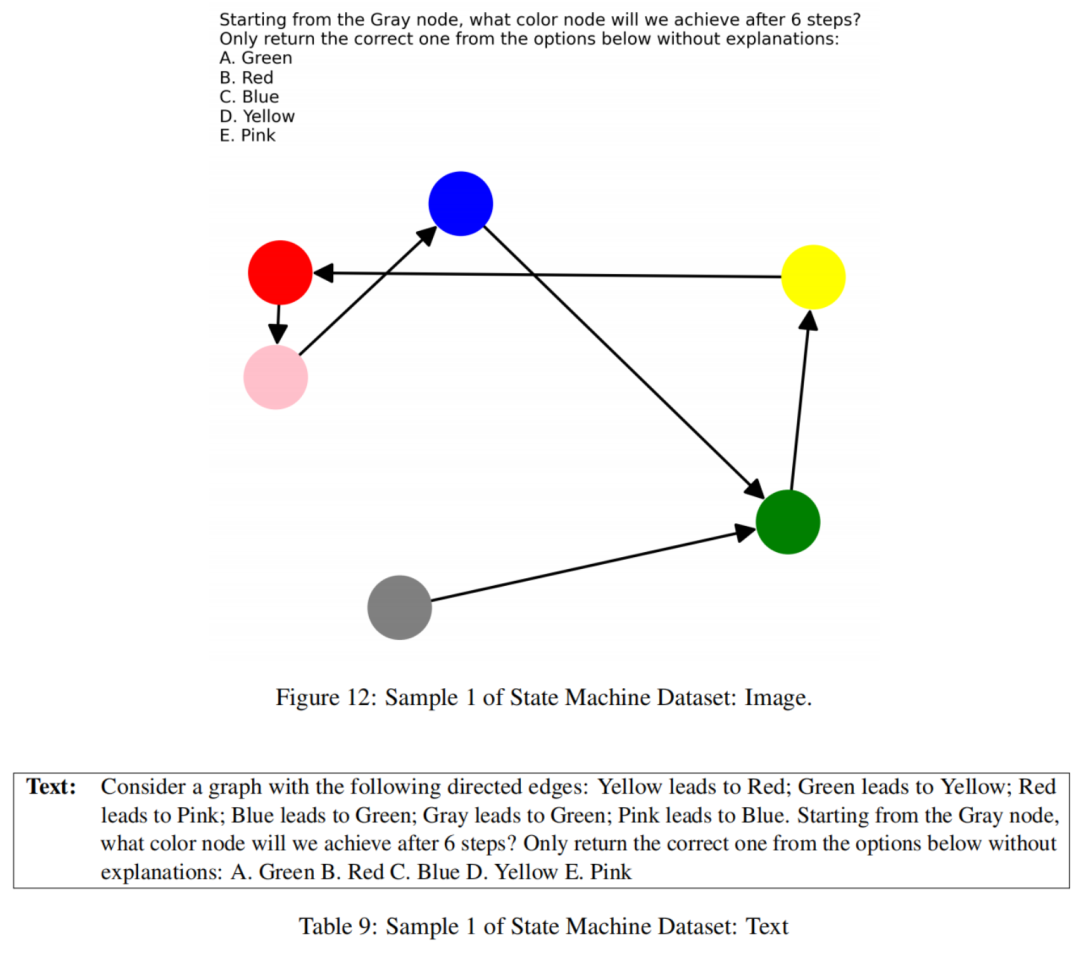
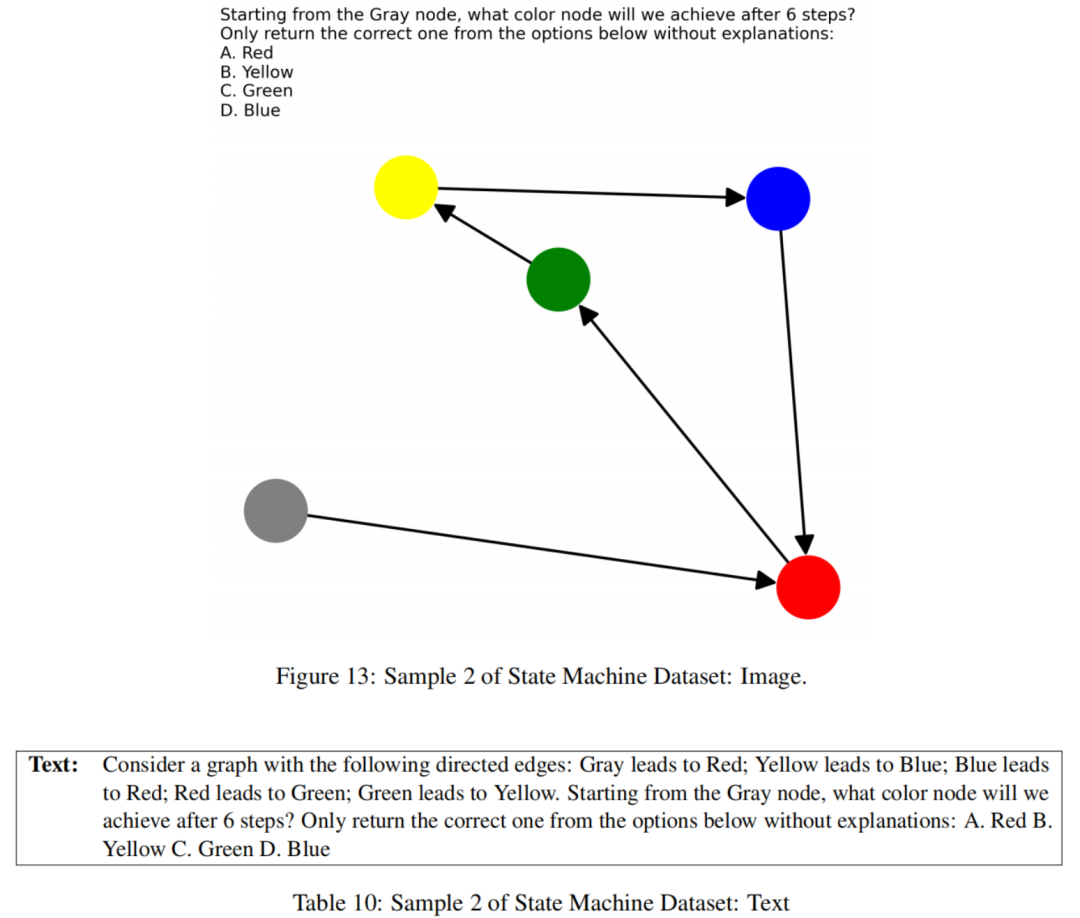
5.1.2 TV任务数据集
VQA常识推理
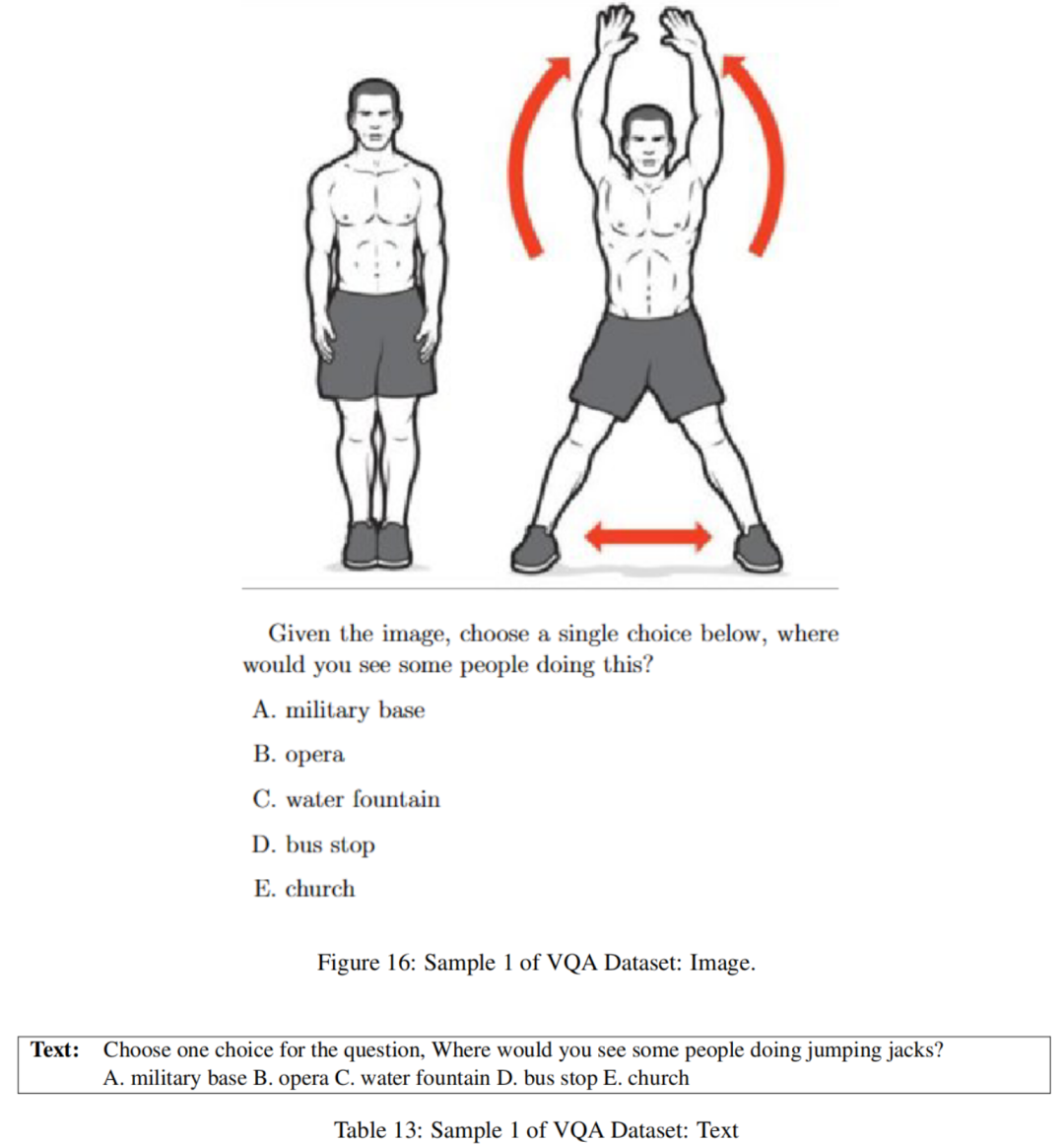
鉴于许多视觉问题回答(Visual Question Answering,VQA)数据集包含无法轻松转化为有意义的基于文本的任务的任务,比如数图像中的物体或解决迷宫,作者使用CommonsenseQA数据集创建了一个平行的视觉-语言VQA数据集。
在这个过程中,对于CommonsenseQA中的每个问题,作者用相应的图像替换了问题的文本描述,同时保持所有其他元素不变。CommonsenseQA中的原始文本问题随后被用作数据集的文本版本,形成了VQA背景下常识推理的图像问题和文本问题的配对。确实,文本信息并非总是能够完全转化为图像,反之亦然。这属于“翻译可变”(TV)任务类别。数据样本如下:

5.2 结果
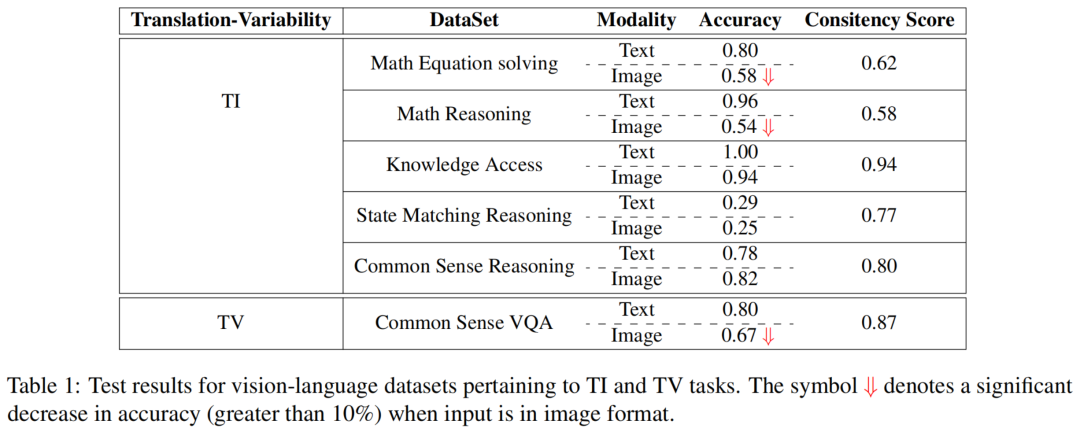
作者对6个不同数据集的主要评估结果列在表1中。值得注意的是,对于“翻译不变”(TI)任务,其中输入包含了解决任务所需的相等信息,当任务具有挑战性并需要更多的推理过程时,作者可以观察到图像和文本输入格式之间存在显著差异。
知识访问和常识推理
这些任务相对简单,不需要复杂的逻辑推理。它们似乎较简单,图像和文本都能够达到大约80-90%的准确率。视觉和语言模态之间存在高度一致性。在这些情况下,一致性分数显著较高,文本输入在准确性方面稍微优于图像。
数学方程求解、数学推理和状态机推理
然而,随着任务变得更加具有挑战性,涉及更高级别的逻辑推理,比如解决数学方程和进行推理过程,作者观察到在图像格式和文本格式下执行这些任务时,准确率差异超过40%。这些任务的一致性分数也显著下降(低至58%)。值得注意的是,尽管图像中提供了解决任务所需的基本信息,但当呈现文本问题时,模型的性能明显更好。这凸显了跨模态任务解决的显著不一致性,并强调了模型在一种模态(语言)上的能力优于另一种模态(视觉)。
VQA常识推理
令人惊讶的是,在翻译可变的任务中,当用文本问题提示时,模型的性能明显优于图像问题,尽管图像通常包含更多的信息以回答问题。这进一步凸显了在这些模型的某些复杂任务中,不同模态(视觉与语言)之间存在很大的差异。
总之,在像GPT-4V这样的多模态系统中,当以文本格式处理任务时,语言模态表现出明显的优势,尽管图像格式中存在相同或更多的信息。这强烈暗示了一种非复合模态网络,其中每种模态展现出不同程度的任务解决和推理能力。
作者的假设是GPT-4V没有学习到高度一致的视觉和语言的联合表示,导致它根据输入格式分别解决任务。考虑到GPT-4V更倾向于成为一种语言模型而不是视觉模型,它的强烈偏好倾向于语言建模,这种能力在与视觉相关的任务中并不平等分享。
5.3 有关从图像中提取文本的割离研究
对于作者使用的一些“翻译不变”(TI)任务,可能会有一个担忧,即模型可能无法成功地从图像中提取或识别信息,即使图像包含与文本相同的内容(包括公式、问题和选项)也可能会导致性能差异。
为了解决这个问题,作者进行了一项割离研究,其中作者仅从作者的数据集中的图像中提取文本格式的问题。具体来说,作者评估了模型提取数学方程求解问题的能力,由于其复杂符号,这些问题尤其具有挑战性。
结果表明,在解数学方程图像时,取得了惊人的87%的提取准确性,清楚地表明了GPT-4V在从任务数据集的图像部分提取问题信息方面的熟练能力。这种性能强调了它在识别和提取图像背景中的信息方面的出色能力。
因此,可以明显看出,在这些任务中观察到的性能差异主要归因于模型在视觉模态和文本之间的内部网络推理差异,而不是由于其他外部因素,比如图像中的信息不完整或无法识别图像中的信息。
6.启发式视觉描绘提示(VDP)
正如第5.2节所示,对于相同的问题,诸如GPT-4V之类的LVLM在以文本格式提出问题时表现得更好,即使信息可以完全从图像实例中提取和保留。因此,作者利用这些发现提出了通过图像背景改进推理能力的方法,即Vision-depicting-prompting(VDP)。
6.1 提示细节
对于以图像格式呈现的任务实例,VDP不同于仅基于图像输入直接征求答案的方法,如图5所示。相反,作者采用了两步过程。首先,作者提示模型提取和表达任务图像的描述,使用文本语言。这种方法旨在最大程度地将图像信号转化为文本信号,认识到与文本信息相关联的内在更强的推理能力,正如之前所证明的。随后,作者提示模型提供答案,考虑到任务的文本描述和原始图像输入,如图5所示。
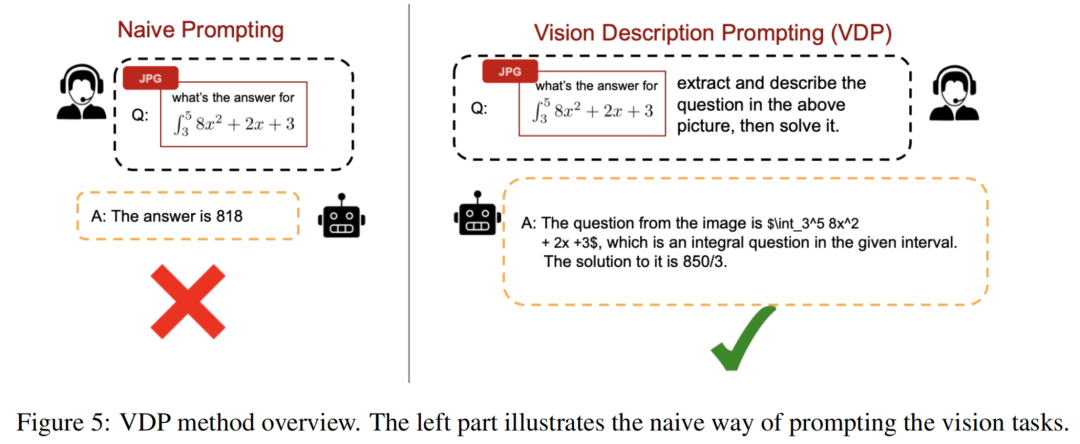
与以前的研究不同,以增加额外文本来增强多模型的推理能力不注重信息增补。这对于TI任务尤为重要,因为图像已经包含完成任务所需的所有必要信息。
因此,将这些图像转换为文本不提供任何额外的见解。相反,VDP建立在这样一个观察之上,即即使视觉背景中缺少一些信息,文本信号可以显著刺激模型的推理能力。VDP通过明确从图像中提取文本信息来实现这一点,从而更有效地利用模型的语言处理能力。
6.2 VDP的实验结果
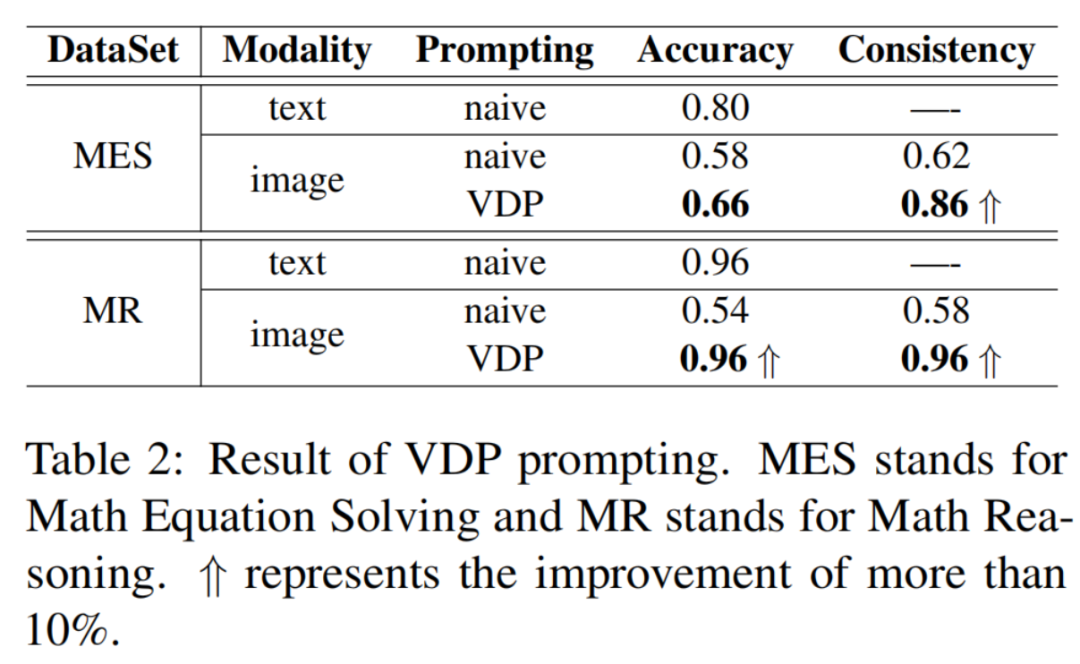
作者在数学方程求解数据集和数学推理数据集上使用了VDP。这些数据集在以前的简单提示方法下表现不佳,如之前所示。结果详见表2。值得注意的是,作者观察到在解决基于图像输入的问题时,准确性显著提高(超过30%)。
此外,与仅使用文本提示相比,一致性分数大幅提高。这些结果不仅强调了作者方法的有效性,还加强了作者的假设,即模型在不同模态之间展现出不同的推理能力。恰当地利用这种差异可以帮助改善任务解决的性能。
7.结论
在这项研究中,作者对多模态系统中不同模态的一致性进行了系统分析。作者的结果表明,像GPT-4V这样的模型在视觉和文本信号之间保持着相对独立的内部推理表示,正如作者专门设计的数据集所证明的。值得注意的是,与视觉背景内的推理相比,GPT-4V在语言建模方面表现出优越的性能。这些发现为这类多模态系统的潜在应用提供了有价值的见解,并强调了需要更多集成系统设计的必要性。此外,作者介绍了一个提示解决这种差异的方法。
8. 参考
[1]. Lost in Translation: When GPT-4V(ision) Can’t See Eye to Eye with Text A Vision-Language-Consistency Analysis of VLLMs and Beyond.
9、推荐阅读
Waymo提出全新Fusion方法LEF | 让3D目标检测的难度再次降低!
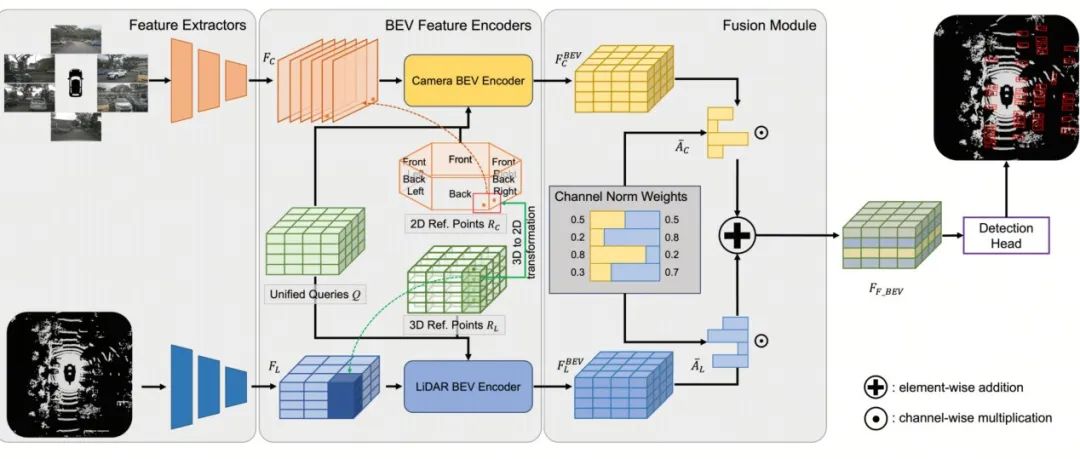
BEVFusion?看UniBEV携CNW融合策略如何一统多模态融合的江湖
即插即用FoLR | 让Self-Attention在目标检测的世界中游刃有余,价值满满!

扫码加入👉「集智书童」交流群
(备注:方向+学校/公司+昵称)




前沿AI视觉感知全栈知识👉「分类、检测、分割、关键点、车道线检测、3D视觉(分割、检测)、多模态、目标跟踪、NerF」
欢迎扫描上方二维码,加入「集智书童-知识星球」,日常分享论文、学习笔记、问题解决方案、部署方案以及全栈式答疑,期待交流!