
YOLOv5就应该这样优化小目标 | HIC-YOLOv5低调设计,虽不新颖但很有用!
共 8094字,需浏览 17分钟
· 2023-10-09
点击下方卡片,关注「AI视界引擎」公众号

小目标检测一直是目标检测领域中的一个具有挑战性的问题。已经有一些研究提出了改进方法,如添加多个注意力模块或改变特征融合网络的整体结构,以解决这个问题。然而,这些模型的计算成本较高,使得部署实时目标检测系统变得不可行,同时还有改进的空间。
为此,提出了改进的YOLOv5模型:HIC-YOLOv5,以解决上述问题。首先,添加了一个针对小目标的额外预测Head,以提供更高分辨率的特征图,从而实现更好的预测。其次,在Backbone网络和Neck之间采用了一种称为"involution block"的模块,以增加特征图的通道信息。此外,在Backbone网络的末端应用了一种名为CBAM的注意力机制,不仅降低了与以前的方法相比的计算成本,还强调了通道和空间领域的重要信息。
结果显示,HIC-YOLOv5在VisDrone-2019-DET数据集上将mAP@[.5:.95]提高了6.42%,将mAP@0.5提高了9.38%。
1、简介
目标检测算法已广泛应用于无人机(UAV)的智能系统,如行人检测和车辆检测。它自动化了无人机拍摄照片的分析过程。然而,这类应用的最大问题在于检测小目标,因为从较高的高度拍摄的照片中大多数目标都变得更小。这个事实对目标检测的准确性产生了负面影响,包括目标遮挡、低目标密度和光线变化剧烈等问题。
You Only Look Once (YOLO)是一种单阶段目标检测算法,由于其低延迟和高准确性,已经主导了UAV系统。它将图像作为输入,并在一阶段输出目标的信息。这种轻量级模型可以在UAV系统中实现实时目标检测。然而,在具有大量小目标的UAV场景中,它仍然存在缺陷。为解决这个问题,之前有一些工作改进了小目标检测性能。一些工作[7][9]改进了YOLOv5的特征融合网络的整体结构。其他工作在Backbone网络中添加了几个注意力模块。然而,以前的方法中计算成本较高,性能仍有改进空间。
在本文中提出了一种改进的YOLOv5算法:HIC-YOLOv5(Head,Involution和CBAM-YOLOv5),用于小目标检测,具有更好的性能和较低的计算成本。首先,作者添加了一个额外的预测Head——专用于从具有更高分辨率的特征图中检测小目标的Small Object Detection Head(SODH)。当特征图的分辨率增加时,更容易提取微小和小目标的特征。其次,作者在Backbone网络和Neck之间添加了一个通道特征融合与involution(CFFI)块,以增强通道信息,从而提高整体性能。通过这种方式,性能得到了改善,更多的信息传递到深度网络中。最后,作者在Backbone网络的末端应用了一个轻量级的Convolutional Block Attention Module(CBAM),它不仅计算成本较低,还通过强调重要的通道和空间特征来提高总体性能。实验证明,HIC-YOLOv5在VisDrone数据集上将YOLOv5的性能提高了6.42%(mAP@[.5:.95])和9.38%(mAP@0.5)。
主要贡献可以总结如下:
-
特别为小目标设计了额外的预测Head。它在分辨率更高的特征图中检测目标,其中包含更多关于微小和小目标的信息。
-
在Backbone网络和Neck之间添加了一个involution块,作为特征图的通道信息增强桥梁。
-
在Backbone网络的末端应用了CBAM,从而提取了更多的关键通道和空间信息,而忽略了多余的信息。
2、本文方法
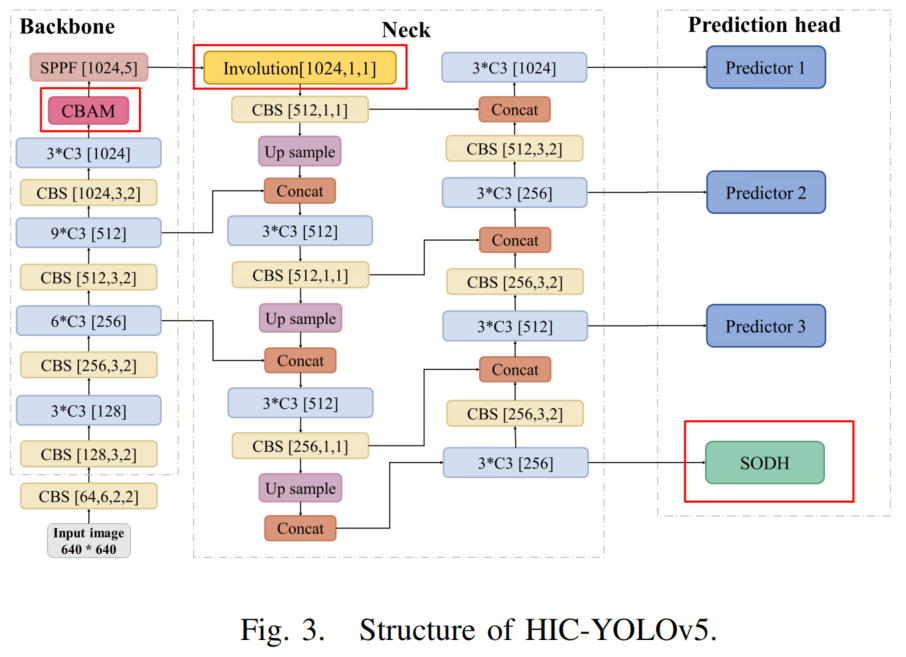
HIC-YOLOv5的结构如图3所示。原始的YOLOv5包括3个部分:Backbone网络用于特征提取,Neck用于特征融合,以及3个预测Head。基于默认模型,作者提出了3个修改:
-
作者添加了一个额外的预测Head,专门用于检测具有高分辨率特征图的小型和微小目标;
-
在Neck的开始采用了Involution块,以提高PANet的性能;
-
作者将卷积块注意模块(CBAM)整合到Backbone网络中。
A. 卷积块注意力模块(CBAM)
以前的研究在生成特征金字塔时将CBAM添加到Neck块中。然而,由于与CBAM连接的一些特征图具有较大的尺寸,参数和计算成本增加。此外,由于参数数量庞大,模型训练也变得困难。
因此,作者将CBAM引入Backbone网络中,目的是在提取Backbone中的特征时突出重要特征,而不是在Neck生成特征金字塔。此外,作为CBAM的输入的特征图大小仅为20×20,比640×640的完整图像小32倍,因此计算成本不会很大。
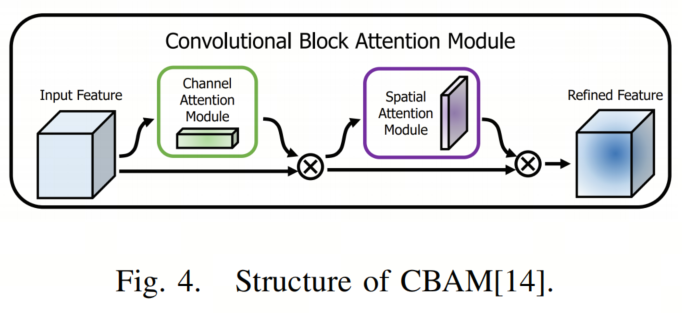
CBAM是一种基于注意里机制的有效模型,可以方便地集成到CNN架构中。它由两个模块组成:通道注意力模块和空间注意力模块,如图4所示。这两个模块分别生成通道和空间注意力图,然后与输入特征图相乘,以促进自适应特征的细化。因此,它强调了通道和空间轴上的有意义的特征,同时抑制了多余的特征。
通道注意力模块对不同通道上的特征图进行全局最大池化和平均池化,然后执行逐元素求和和sigmoid激活。空间注意力模块对不同特征图上相同位置的像素的值进行全局最大池化和平均池化,然后将这两个特征图连接在一起,接着进行Conv2d操作和sigmoid激活。
B. 带有Involution的通道特征融合(CFFI)
YOLOv5的Neck采用了PANet,它在FPN的基础上引入了自下而上的路径增强结构。YOLOv5中FPN和自下而上路径增强的相应结构如图2所示。
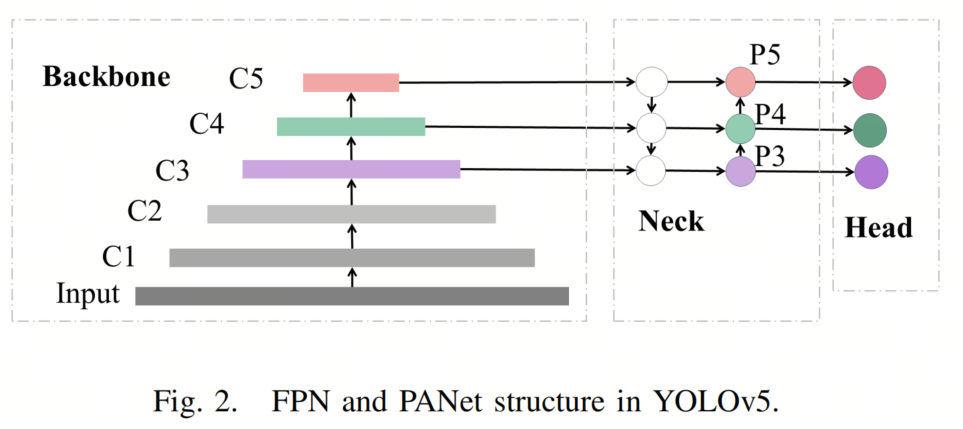
特别地,FPN通过融合高层和低层的特征来检测小型和微小目标,以获得高分辨率和强语义特征。然而,在原始的YOLOv5中,在Neck的开始处采用了1×1的卷积来减少通道数,从而显著提高了计算效率,但也降低了通道信息,导致PANet的性能较差。受Tia-YOLOv5启发,作者在Backbone和Neck之间添加了一个Involution块。通道信息得到了改善和共享,从而减少了FPN初始阶段的信息损失。因此,这一改进有助于提高FPN的性能,特别有益于检测较小尺寸的目标。
此外,值得强调的是,从不同的空间位置来看,Involution在适应不同的视觉模式方面具有更好的性能。
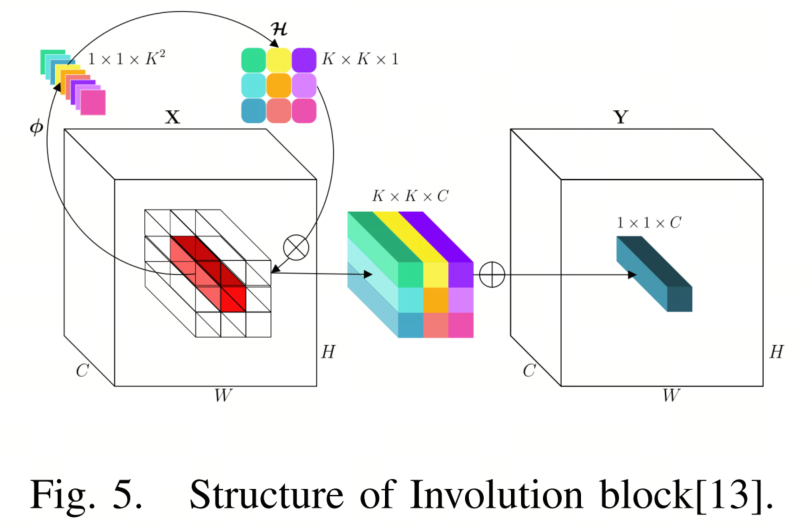
Involution的结构如图5所示。Involution核表示为 ,设计用于在空间和通道领域中展现逆属性的变换,其中 和 表示特征图的高度和宽度, 是卷积核大小, 表示组的数量,每个组共享相同的involution核。
特别地,为像素 (为简洁起见,省略了C的下标)设计了特定的involution核,表示为,同时在通道上共享。最后,involution的输出特征图 如下获得:
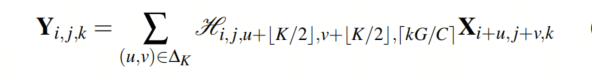
因此,单个像素的通道维度中包含的信息被隐式地分散到其空间邻域,这有助于获取丰富的感受野信息。
C. 预测Head
YOLOv5中的3个预测Head具有不同的分辨率(80×80、40×40和20×20),这对各种应用场景中的检测能力有很大贡献,但也使得检测小型和微小目标变得困难。YOLOv5在微小目标检测上表现不佳的原因是微小目标的特征通常只包含很少的像素,容易被忽略。尽管卷积块在从特征图中提取特征方面发挥了重要作用,但当网络的深度增加时,它们也会降低特征图的分辨率,因此难以提取微小目标的特征。
为了解决这个问题,作者提出了一个额外的预测Head——Small Object Detection Head(SODH),旨在检测具有更高分辨率(160×160)的特征图。从小型和微小目标中提取特征变得越来越容易。
每个预测Head以由Backbone和Neck提取和融合的特征作为输入,最终输出一个向量,包含回归边界框(坐标和大小)、目标边界的置信度和目标的类别。在生成最终的边界框之前,作者生成Anchor框以形成候选边界框。这些Anchor框是根据数据集通过 生成的,并针对3个不同的预测Head定义在3个不同的尺度上,适应小型、中型和大型目标。额外的预测Head的Anchor框也是通过 生成的。
D. 损失函数
HIC-YOLOv5的损失函数包括3个部分:目标性、边界框和类别概率,可以表示如下:
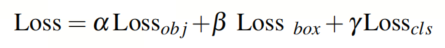
作者对目标性和类别概率使用二元交叉熵损失,对边界框回归使用CIoU损失。
E. 数据增强
数据增强是增强模型鲁棒性的重要技术。在YOLOv5中,数据增强包括Mosaic、Copy paste、Random affine、MixUp、HSV增强和Cutout。
除此之外,作者发现在Visdrone2019数据集中,许多小人和小车位于图像的中心。因此,作者对上述的数据增强技术添加了额外的中心裁剪。
3、实验
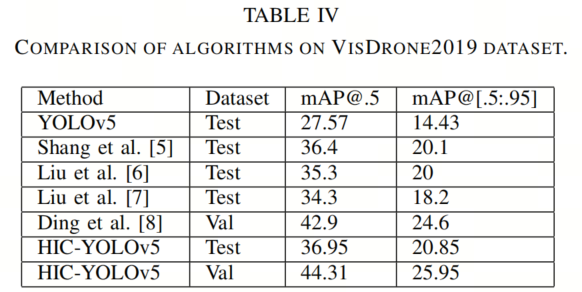
从表格 IV 可以看出,与 YOLOv5s 模型相比,mAP@[.5:.95] 提高了 6.42%,mAP@0.5 提高了 9.38%。精确度和召回率分别提高了 10.29% 和 6.97%。小目标检测Head极大地有助于保留小目标的特征。
此外,Involution 有效地增强了通道信息,而 CBAM 块在Backbone内部的特征提取过程中有选择地强调了关键特征。YOLOv5s 和 HIC-YOLOv5 之间的检测效果如图 7 所示。它直观地表示,使用改进的方法可以检测到更多的小目标。

作者还将作者的改进模型与在 VisDrone2019 上测试的其他算法进行了比较。结果如表格 IV 所示。可以看出,作者提出的模型相对于其他检测模型具有更高的性能。例如,[ Improved gbs-yolov5 algorithm based on yolov5 applied to uav intelligent traffic] 应用了递归门控卷积来增强空间交互作用,但由于 1×1 卷积层可能导致通道信息的丢失。与 [ Improved gbs-yolov5 algorithm based on yolov5 applied to uav intelligent traffic] 相比,作者采用了 Involution 块来增强 PANet 的通道信息,从而提高了小目标检测的性能。
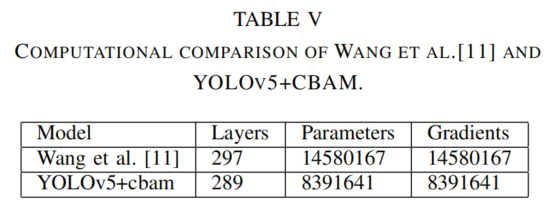
Tia-yolov5在Backbone的末端添加了一个 Transformer 层,但这样做会导致计算成本较大的缺点。相反,作者应用了轻量级的 CBAM 块,从而减少了训练时间和计算成本。Tia-yolov5 和 YOLOv5+CBAM 的层数、参数和梯度数量列在表格 V 中。由于Tia-yolov5使用了另一个不同的数据集,mAP 无法进行比较。
消融实验
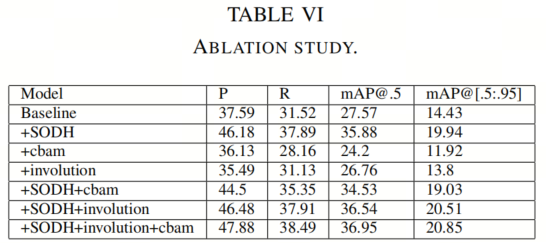
作者进行了多个实验来研究3个修改的效果:额外的预测Head、Involution 块和 CBAM。消融研究的结果如表 VI 所示。可以观察到,第4个预测Head对模型的性能贡献最大,将 mAP@0.5 和 mAP@[.5:.95] 分别提高了 8.31% 和 5.51%。相反,单独的 CBAM 和 Involution 块在没有第4个预测Head的情况下不能改善模型。
作者推测,这是因为在 VisDrone2019 数据集中有很多小目标,如果这些小目标不能首先被检测到,那么单独的 CBAM 和 Involution 块无法表现良好。基于添加了第4个预测Head,Involution 块也对模型有很大的改进,mAP@0.5 和 mAP@[.5:.95] 分别提高了 0.66% 和 0.57%。此外,mAP@0.5 和 mAP@[.5:.95] 分别提高了 0.41% 和 0.34%。
4、参考
[1].HIC-YOLOv5: Improved YOLO5 For Small Object Detection.
5、推荐阅读

可以取代NMS?IOU感知校准,取代NMS,成就YOLOX等目标检测更快的后处理方法
DMKD蒸馏 | 模型学习,空间/通道信息我都要!超越FKD、FGD、MGD以及AMD方法!
DualToken-ViT | 超越LightViT和MobileNet v2,实现更强更快更轻量化的Backbone

点击上方卡片,关注「AI视界引擎」公众号