
本周AI开源项目精选(下) |基于PaddlePaddle的出色多语言OCR工具包、钢琴MIDI数据集
本周关键词:MIDI数据集、ORC、矢量模型、轻量级AutoML基准
GiantMIDI-Piano 钢琴MIDI数据集
钢琴转谱是一项将钢琴录音转为音乐符号(如 MIDI 格式)的任务。在人工智能领域,钢琴转谱被类比于音乐领域的语音识别任务。然而长期以来,在计算机音乐领域一直缺少一个大规模的钢琴 MIDI 数据集。
近期,字节跳动发布了全球最大的古典钢琴数据集 GiantMIDI-Piano [1]。在数据规模上,数据集不同曲目的总时长是谷歌 MAESTRO 数据集的 14 倍。
GiantMIDI-Piano 中前 100 位不同作曲家的曲目数量分布:
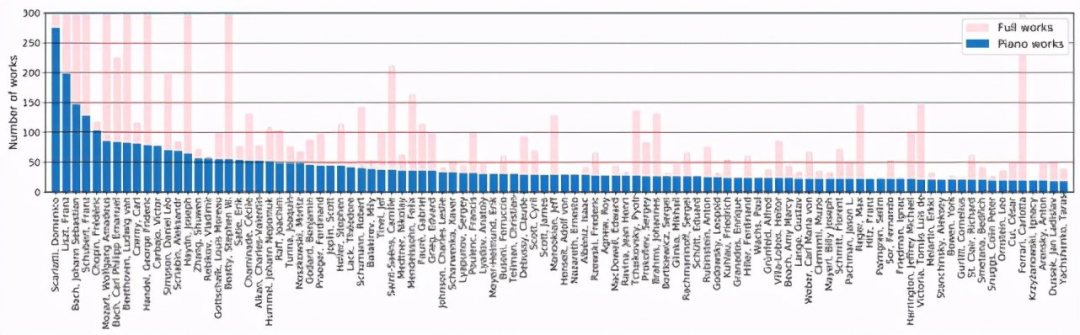
GiantMIDI-Piano 的特点是使用钢琴转谱技术,通过计算机将音频文件自动转为 MIDI 文件,并通过该技术转谱了大规模的 MIDI 数据集。研究者首先从开放的国际音乐数字图书馆 IMSLP 获取了18,067位作曲家的143,701首作品名信息,并通过 YouTube 搜索到60,724个音频。然后,研究者设计了基于音频卷积神经网络(CNN)的钢琴独奏检测算法,筛选出来自 2,786 位作曲家的 10,854 部钢琴作品。最后,研究者开发并开源了一套高精度钢琴转谱系统(High-resolution Piano Transcription with Pedals by Regressing Precise Onsets and Offsets Times)[2],将所有音频转谱成 MIDI 文件,进而构建了 GiantMIDI-Piano 数据库。
GiantMIDI-Piano 数据集具备以下特点:
包含来自 2,784 位作曲家 10,854 首作品的 MIDI 文件。
包含 34,504,873 个音符。
所有的曲目都是不同的,MIDI 文件的总时长为 1,237 小时。
由高精度转谱系统转谱音频而成。转谱的 MIDI 文件包括音符的起始时间、力度和踏板信息。
GiantMIDI-Piano 的转谱相对错误率为 0.094,在 Maestro 钢琴数据集上的转谱 F1 值为 96.72%。
所有 MIDI 文件都有统一的格式,文件名格式为「姓_名_曲目名_youtubeID.mid」。
包含作曲家国籍和出生年份信息。
数据集大小为 193 Mb。
使用许可为 CC BY 4.0。
项目地址:
https://github.com/bytedance/GiantMIDI-Piano
PaddleOCR 基于PaddlePaddle的出色多语言OCR工具包
PaddleOCR旨在打造一套丰富、领先、且实用的OCR工具库,助力使用者训练出更好的模型,并应用落地。
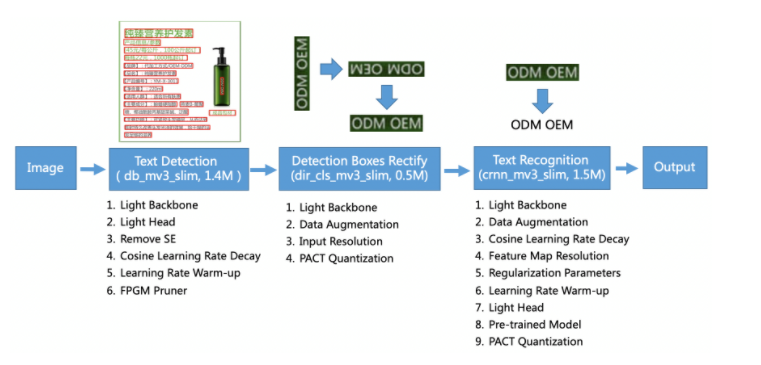
特性:
PPOCR系列高质量预训练模型,准确的识别效果
超轻量ppocr_mobile移动端系列:检测(3.0M)+方向分类器(1.4M)+ 识别(5.0M)= 9.4M
通用ppocr_server系列:检测(47.1M)+方向分类器(1.4M)+ 识别(94.9M)= 143.4M
支持中英文数字组合识别、竖排文本识别、长文本识别
支持多语言识别:韩语、日语、德语、法语
丰富易用的OCR相关工具组件
半自动数据标注工具PPOCRLabel:支持快速高效的数据标注
数据合成工具Style-Text:批量合成大量与目标场景类似的图像
支持用户自定义训练,提供丰富的预测推理部署方案
支持PIP快速安装使用
可运行于Linux、Windows、MacOS等多种系统

项目地址:
https://github.com/PaddlePaddle/PaddleOCR
paz Python中的分层感知库,用于姿势估计,对象检测,实例分割,关键点估计,面部识别等。
Probabilistic 2D keypoints | 6D head-pose estimation | Object detection |
|
|
|
Emotion classifier | 2D keypoint estimation | Mask-RCNN (in-progress) |
|
|
|
3D keypoint discovery | Haar Cascade detector | 6D pose estimation |
|
|
|
Implicit orientation | Attention (STNs) | Eigenfaces |
|
|
|








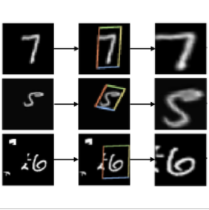

以下模型在PAZ中实现,可以使用您自己的数据进行训练:
任务 | 模型 | 任务 | 模型 |
目标检测 | SSD-512 SSD-300 | 6D姿态估计 | KeypointNet2D |
概率关键点估计 | Gaussian Mixture CNN | 情绪分类 | MiniXception |
检测与分割 | MaskRCNN (in progress) | 关键点估计 | KeypointNet2D |
关键点估计 | HRNet | 注意力机制 | Spatial Transformers |
语义分割 | U-NET | 目标检测 | HaarCascades |
项目地址:
https://github.com/oarriaga/paz
vectorhub 使用最新模型将数据转换为矢量
Vector Hub是一个用于发布,发现和使用最新模型以将数据转换为向量的库。(Text2Vec,Image2Vec,Video2Vec,Face2Vec,Bert2Vec,Inception2Vec,Code2Vec,LegalBert2Vec等)。有很多方法可以从数据中提取向量。该库旨在以简单的方式引入所有最新模型,从而轻松地对数据进行矢量化处理。
Vector Hub提供:
从业人员进入门槛低(使用常用方法)
用3行代码向量化丰富和复杂的数据类型,例如:文本,图像,音频等
检索并找到有关模型的信息
一种轻松处理不同模型的依赖关系的简便方法
安装和编码的通用格式(使用简单的编码方法)。
为了为从业人员提供一种简便的方法来快速进行实验,研究和构建新的模型和特征向量,我们提供了一种通过编码方法来获得向量的简化方法。跨不同用例/域的数千种_____2Vec模型。Vectorhub使人们可以汇总他们的工作并与社区共享。
项目地址:
https://github.com/vector-ai/vectorhub
MedMNIST 医学图像分析的轻量级AutoML基准
我们提出了MedMNIST,它是10个经过预处理的医学开放数据集的集合。 MedMNIST已标准化,可以在不需要背景知识的情况下对28×28的轻量图像执行分类任务。涵盖医学图像分析中的主要数据模式,它在数据规模(从100到100,000)和任务(二进制/多类,有序回归和多标签)方面是多种多样的。 MedMNIST可用于医学图像分析中的教育目的,快速原型制作,多模式机器学习或AutoML。此外,MedMNIST分类十项全能旨在对所有10个数据集的AutoML算法进行基准测试。

关键特性:
教育性的:我们的多模式数据来自具有知识共享(CC)许可的多个开放式医学图像数据集,易于用于教育目的。
标准化:将数据预处理为相同格式,无需用户了解任何背景知识。
多样化:多模式数据集涵盖了各种数据规模(从100到100,000)和任务(二进制/多类,有序回归和多标签)。
轻巧:28×28的小巧尺寸适合快速原型设计和试验多模式机器学习和AutoML算法。
项目地址:
https://github.com/MedMNIST/MedMNIST
回顾精品内容
推荐系统
机器学习
自然语言处理(NLP)
1、AI自动评审论文,CMU这个工具可行吗?我们用它评审了下Transformer论文
2、Transformer强势闯入CV界秒杀CNN,靠的到底是什么"基因"
计算机视觉(CV)
1、9个小技巧让您的PyTorch模型训练装上“涡轮增压”...
GitHub开源项目:
1、火爆GitHub!3.6k Star,中文版可视化神器现身
2、两次霸榜GitHub!这个神器不写代码也可以完成AI算法训练
3、登顶GitHub大热项目 | 非监督GAN算法U-GAT-IT大幅改进图像转换
每周推荐:
1、本周优秀开源项目分享:无脑套用格式、开源模板最高10万赞
七月在线学员面经分享:
1、先工程后算法:美国加州材料博后辞职到字节40万offer
2、 双非应届生拿下大厂NLP岗40万offer:面试经验与路线图分享
3、转行NLP拿下40万offer:分享我面试中遇到的54道面试题(含参考答案)