
2024 知乎爬虫源代码 | 「如何看待华农黄教授被学生联合举报学术造假...
之前分享过 不少关于知乎站点的采集爬虫,大部分应该都失效了。
近来后台有超过五位读者留言有关知乎回答的采集问题,索性就把知乎回答爬虫写完推送出来,代码见文末,可以方便采集一个问题下的所有回答。
以最近的最火的话题之一:「如何看待华中农业大学黄某若教授被课题组十一名成员联合举报学术造假?」为例。
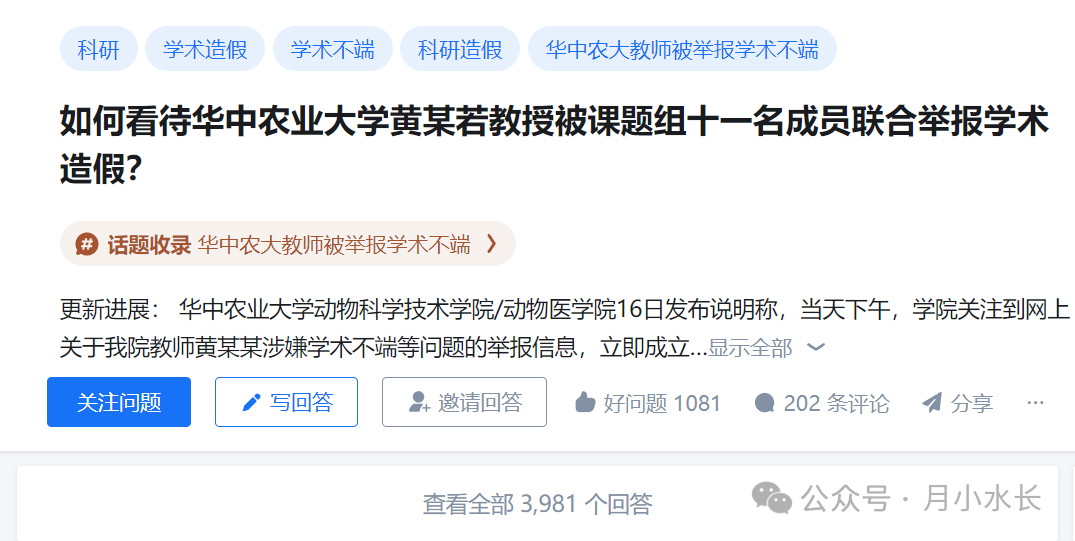
问题链接:https://www.zhihu.com/question/639775801,其中 639775801 就是这个问题的 id。
共采集到约 4000 条数据,每条数据都包括问题描述、问题链接、问题创建时间、问题更新时间、 回答链接、回答创建时间、回答更新时间、答主名、答主性别、答主链接、答主粉丝数、回答概述、回答详情、回答赞同数、评论数、喜欢数 累计约 20 个字段。
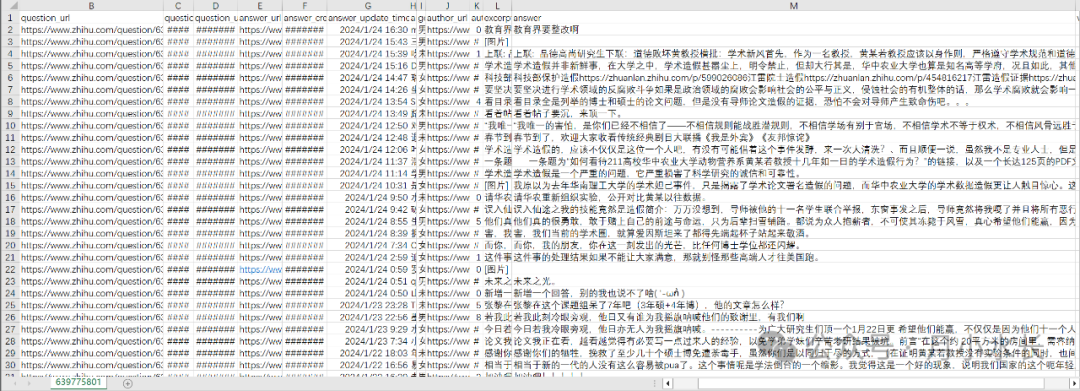
接口地址为, https://www.zhihu.com/api/v4/questions ,
接口参数主要为 offset 、 limit 和 order ,分别控制翻页、条数和排序方式。
访问接口没有太多限制,不带 Headers 都可以直接访问,
不过一般为了表示尊重还是带上 Headers ,里面只有 User-Agent 即可,
进一步为了保证数据完整性,可以带上 Cookie ,总之,丰俭由人。
把采集的代码封装成了一个函数,可以直接修改问题 question_id 采集对应的回答,且可以修改回答排序按时间或者是默认顺序,
以及修改结束页数 max_page ,意即最多爬到第 max_page 页即自动停止,而不论是否还有没有更多数据。
crawl_answer_by_question_id(question_id='639775801', order_type='最新', max_page=10000)
完整代码具有以下功能:
- 根据指定
question_id采集指定问题下的回答、修改方便、字段灵活。 - 文件保存在标准格式 CSV 中,追加采集时自动清洗去重,按照回答时间排序。
- 纯 Python 源代码,主要依赖 requests + pandas 实现,相对轻量级。
- 代码遵循 PEP8 规范,0 error 0 warning,包含爬虫请求->解析->保存三部曲,可作为基础爬虫入门实战项目学习。
示例的 4000 条回答数据和完整代码上传至面包多,下载地址如下:
https://mbd.pub/o/bread/ZZqVl59u