
长时舞蹈生成:数秒钟可生成极长的3D舞蹈
大数据文摘
共 5164字,需浏览 11分钟
· 2024-04-11
 大数据文摘受权转载自将门创投
大数据文摘受权转载自将门创投
针对目前音乐生成3D舞蹈动作中存在的长序列生成动作质量差,生成效率低的问题,本文提出了Lodge,可以高效地根据输入音乐生成极长的3D人体舞蹈动作。本文将Lodge设计为两阶段的由粗到细的Diffusion框架,并提出了特征化的舞蹈基元动作作为两阶段Diffusion的中间层表征,从而让Lodge可以兼顾全局编舞规律和局部的动作质量,并且增强舞蹈的表现力。此外,本文还提出了脚步优化模块以缓解脚和地面的接触问题如脚滑、脚步漂浮等。文本通过大量的定量和定性实验证明了Lodge的有效性。代码已经开源,欢迎体验。
论文题目:
Lodge: A Coarse to Fine Diffusion Network for Long Dance Generation Guided by the Characteristic Dance Primitives 论文链接: https://arxiv.org/abs/2403.10518 主页链接: https://li-ronghui.github.io/lodge 代码链接:
https://github.com/li-ronghui/LODGE
一、 研究动机
近年来,随着生成式人工智能 的快速发展,现有方法如FineDance[1] ,EDGE[2]已经展示出了数秒钟高质量舞蹈的能力。然而,实际应用中的舞蹈表演和社交舞通常持续3至5分钟,舞蹈剧可以持续15分钟以上。因此,现有的舞蹈生成算法难以满足实际需求,而如何生成高质量的长序列舞蹈动作成为了正待解决的问题。然而,生成长序列的舞蹈仍面临着不少挑战:
- 长序列数据显著增大了计算开销,如何开发计算友好的方法,提高训练和推理阶段的效率?
- 现有的方法主要采用自回归模型,迭代地生成长序列舞蹈。然而这些方法往往面临着误差累积问题,且无法学习到全局的编舞规律。
- 由于神经网络的训练只关注与整体loss的收敛,因此网络更倾向于生成保守的动作,这导致了最终的舞蹈缺少富有表现力的动作,展现出了平淡和中庸的效果。
- 我们提出了一个可以并行生成长舞蹈的扩散模型。我们的方法能够学习整体的编舞模式,同时保证局部动作的质量。并行生成策略可以在数秒钟生成极长的3D舞蹈。
- 我们提出了characteristic dance primitives作为两个扩散模型之间的中间表示,提高了生成舞蹈的张力。
- 我们提出了一个脚部优化模块,并采用足部与地面的接触损失来缓解脚步和地面接触的问题诸如脚滑、脚部漂浮和脚与地面穿模等。
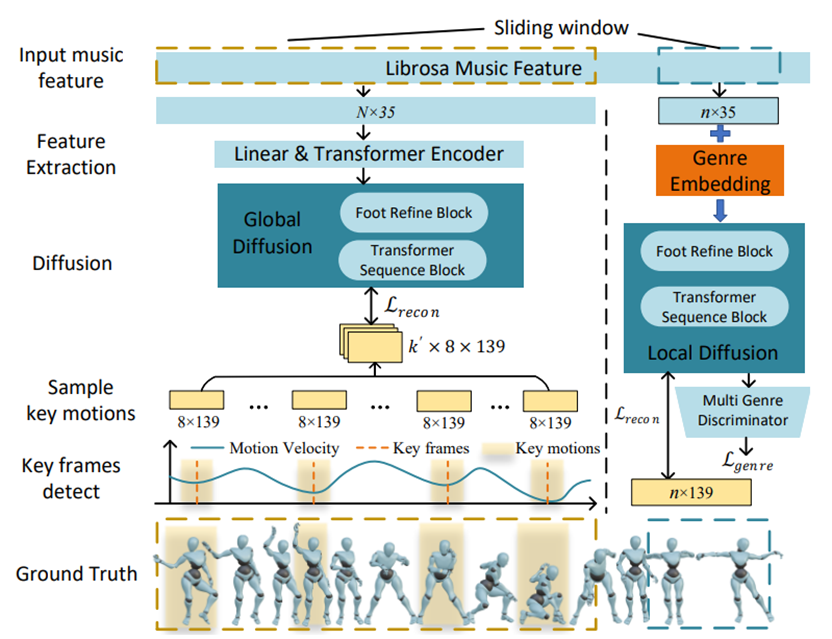
图1. Lodge训练过程。
在推理阶段,首先输入长音乐特征,用Global Difusion生成蕴含编舞规律的多个dance primitives。每个dance primitives的维度是,其中 8 是帧,139是动作的维度。然后,我们将它们按照时间顺序分为用于支持并行生成的hard-cue key motion 和用于增强舞蹈表现的soft-cue key motion 。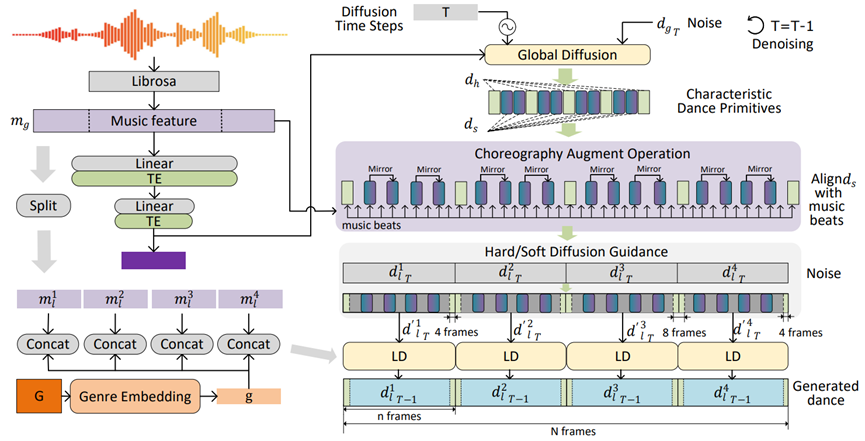
图2. Lodge推理过程。“TE”为Transformer Encoder,“LD”为Local Diffusion。
随后进行Local Diffusion的并行生成。我们将在时间维度切分为,并行地采用4个Local Diffusion并行生成对应的舞蹈片段。如图3所示,在生成过程种,我们利用hard-cue key motion和Diffusion inpainting技术控制 的最后四帧与对应的前4帧一致,而的前4帧与该 的后4帧一致。从而让 与 可以无缝衔接。同时,在扩散模型去噪过程中,soft-cue key motion仅在最初的步中起到指导作用,其中T是扩散去噪步数。通过调整超参数“”,我们可以控制Local Diffusion受这些soft-cue key motion影响的程度。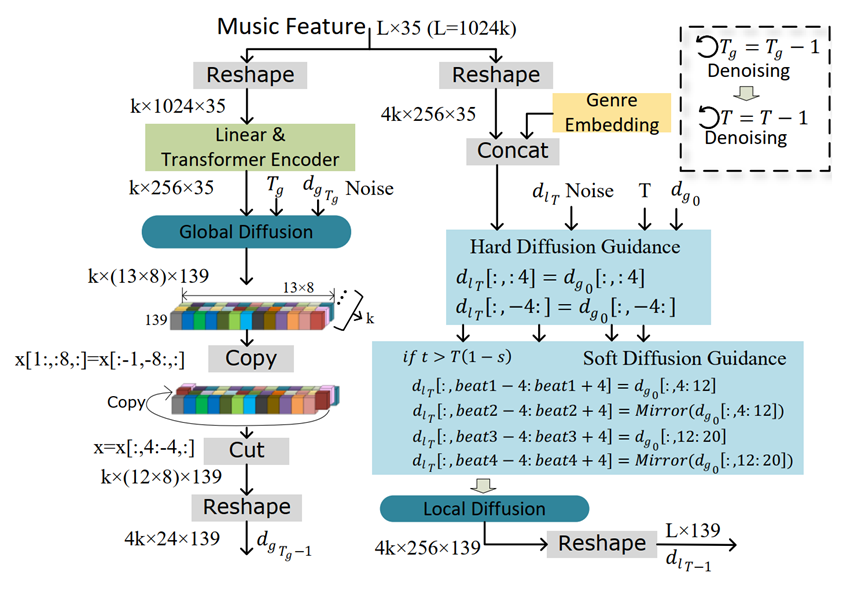
图3. Hard/Soft Diffusion Guidance
三、实验
我们在FineDance[1]和AIST++[5]两个数据集上进行实验。由于FineDance平均每段舞蹈的时长是152.3秒,远高于AIST++的13.3秒,因此我们主要用FineDance数据集进行训练和测试。 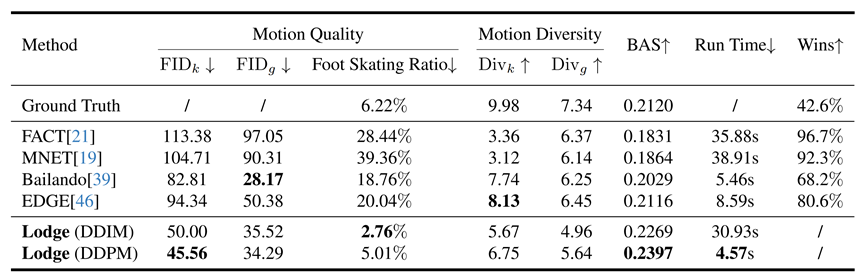
表1. 在FineDacne数据集上与其他方法对比 。
值得一提的是,采用DDIM采样策略可以获得不错的性能,并且生成1024帧舞蹈的推理时间降低到了4.57s。而得益于我们的并行生成架构,继续增大需要生成的舞蹈的序列长度,推理时间也不会显著增大。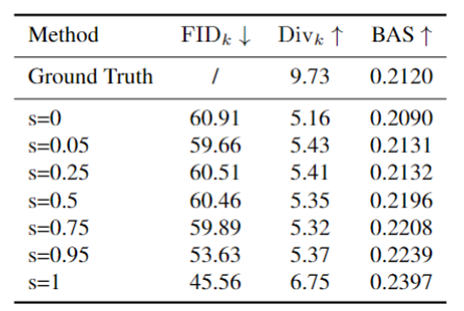
表2. 超参数“s”的消融实验,测试于FineDance数据集。
我们的soft-cue key motion对结果的影响程度可以使用超参数“s”进行调整,其中“s”值越大表示效果越强。表2 展示了设置各种“s”值所产生的结果。随着“s”的增加,和节拍对齐分数BAS也相应增强。当“s”设置为 1 时,可获得最佳的性能。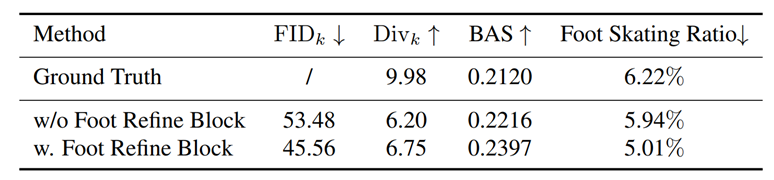
表3. Foot Refine Block的消融实验,测试于FineDance数据集。
如表3所示,加入Foot Refine Block后,运动质量FID_k有了很大的改善,特别是Foot Skating Ratio从5.94%下降到5.01%,这证明我们提出的Foot Refine Block可以有效改善脚部与地面的接触质量,降低脚部脚滑现象出现的频率。 四、总结 在这项工作中,我们引入了 Lodge,一种两级从粗到细的扩散网络,并提出characteristic dance primitives作为两个扩散模型的中间级表示。Lodge 已通过用户研究和标准指标进行了广泛的评估,取得了最先进的结果。我们生成的样本表明,Lodge 可以并行生成符合编舞规则的舞蹈,同时保留局部细节和物理真实感。广泛的消融实验验证了我们不同模块、粗到细框架、舞蹈基元和足部细化网络的有效性。然而,我们的方法目前无法生成带有手势或面部表情的舞蹈动作,这对于表演也至关重要。我们将很高兴在未来看到长序列全身舞蹈生成的新工作。 参考文献 [1] Li, Ronghui, et al. "FineDance: A Fine-grained Choreography Dataset for 3D Full Body Dance Generation." Proceedings of the IEEE/CVF International Conference on Computer Vision. 2023.[2] Tseng, Jonathan, Rodrigo Castellon, and Karen Liu. "Edge: Editable dance generation from music." Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 2023.
[3] Blom, Lynne Anne, and L. Tarin Chaplin. The intimate act of choreography. University of Pittsburgh Pre, 1982.
[4] Chen, Kang, et al. "Choreomaster: choreography-oriented music-driven dance synthesis." ACM Transactions on Graphics (TOG) 40.4 (2021): 1-13.
[5] Li, Ruilong, et al. "Ai choreographer: Music conditioned 3d dance generation with aist++." Proceedings of the IEEE/CVF International Conference on Computer Vision. 2021.
[6] Huang, Ruozi, et al. "Dance revolution: Long-term dance generation with music via curriculum learning." arXiv preprint arXiv:2006.06119 (2020).
[7] Siyao, Li, et al. "Bailando: 3d dance generation by actor-critic gpt with choreographic memory." Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 2022.
Illustration From IconScout By 22

租:4090/A800/H800/H100
售:现货H100/H800
特别适合企业级应用
 扫码了解详情☝
扫码了解详情☝
评论