
一文理解RetNet
共 31725字,需浏览 64分钟
· 2023-07-29
前言
微软研究院最近提出了一个新的 LLM 自回归基础架构 Retentive Networks (RetNet)[1,4],该架构相对于 Transformer 架构的优势是同时具备:训练可并行、推理成本低和良好的性能,不可能三角。

论文中给出一个很形象的示意图,RetNet 在正中间表示同时具备三个优点,而其他的架构 Linear Transformer、Recurrent Network 和 Transformer 都只能同时具备其中两个有点。
接下来看一下论文给出的 RetNet 和 Transformer 的对比实验结果:
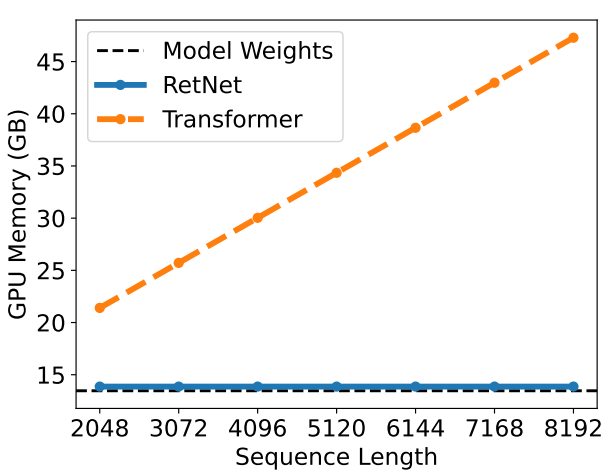
当输入序列长度增加的时候,RetNet 的 GPU 显存占用一直是稳定的和权值差不多,而 Transformer 则是和输入长度成正比。
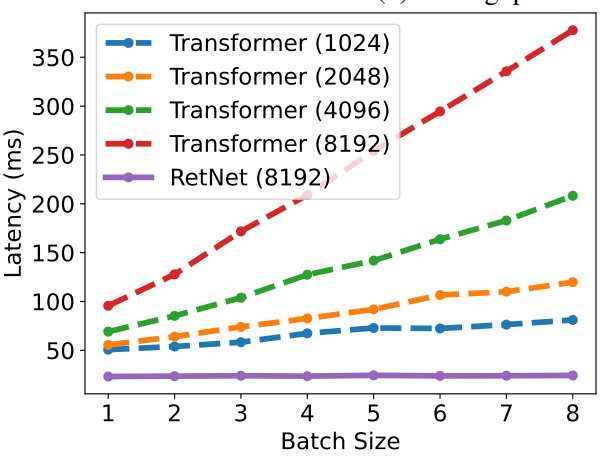
首先看红色线和紫色线,都是输入长度在 8192 下,RetNet 和 Transformer 推理延时的对比。
可以看到当 batch size 增加的时候, RetNet 的推理延时也还是很稳定,而 Transformer 的推理延时则是和 batch size 成正比。
而 Transformer 即使是输入长度缩小到 1024 ,推理延时也还是比 RetNet 要高。
RetNet 架构解读
RetNet 架构和 Transformer 类似,也是堆叠 层同样的模块,每个模块内部包含两个子模块:一个 multi-scale retention(MSR)和一个 feed-forward network (FFN)。
下面详细解读一下这个 retention 子模块。
首先给定一个输入序列 :
其中 表示序列的长度。然后输入序列首先经过 embedding 层得到词嵌入向量:
其中 表示隐含层的维度。
Retention 机制
首先对给定输入词嵌入向量序列 中的每个时间步 的向量 都乘以权值 得到 :
然后同样有类似 Transformer 架构的 Q 和 K 的投影:
其中 是需要学习的权值。
接着假设现在有一个序列建模的问题,通过状态 将 映射为 向量。首先来看论文中给出的映射方式定义:
其中 是一个矩阵, 表示时间步 对应的 投影则 。同样 表示时间步 对应的 投影。
那么上面公式中的 计算公式是怎么得出来呢,下面详细解释一下,首先将 展开:
其中 表示单位矩阵(主对角线元素为1,其余元素为0的方阵)。然后我们假定 为初始状态元素为全0的矩阵,则有:
再继续上述推导过程:
所以根据上述推导过程和条件归纳可得:
然后我们来看一下 矩阵是什么,论文中定义了 是一个可对角化的矩阵,具体定义为:
其中
都是
维的向量,
是一个可逆矩阵,而要理解
首先得复习一下欧拉公式 [2]:
其中
表示任意实数,
是自然对数的底数,
是复数中的虚数单位,也可以表示为实部
,虚部
的一个复数,欧拉公式[2]建立了指数函数、三角函数和复数之间的桥梁。
而这里 是一个 维向量:
则 也就是将向量元素两两一组表示分别表示为复数的实部和虚部:
然后 就是一个对角矩阵,对角元素的值就对应将 和 转成复数向量相乘再将结果转回实数向量的结果。
关于复数向量相乘可以参考文章:
一文看懂 LLaMA 中的旋转式位置编码(Rotary Position Embedding)
现在我们知道了矩阵 的构成就能得到:
这里因为 是可逆矩阵则有性质
其中 为单位矩阵,则将 次方展开:
就是 个 矩阵相乘,中间相邻的 都消掉了,所以可得:
然后我们回到计算 的公式:
接着论文中提出把 吸收进 和 也就是 和 分别用 和 替代当作学习的权值,那么可得:
接着将公式简化,将 改为一个实数常量,那么可得:
在继续推导前,先来仔细看一下 ,借助欧拉公式展开:
然后复习一下三角函数的性质[3]:
则有:
转为复数形式表示就是:
刚好就对应 的共轭
所以可得:
其中 表示共轭转置操作。
Retention 的训练并行表示
首先回顾单个时间步 的输出 的计算公式如下:
而所有时间步的输出是可以并行计算的,用矩阵形式表达如下:
其中 ,而 表示两个矩阵逐元素相乘, 和 每一行对应一个时间步的 q 和 k 向量。
而 每一行对应向量 。 就是对应 矩阵的共轭,也就是将 矩阵每一行改为复数的共轭形式。
而 矩阵是一个下三角矩阵,其中第 行第 列的元素计算方式:
Retention 的推理循环表示
推理阶段的循环表示论文中定义如下:
怎么理解呢,还是先回顾单个时间步 的输出 的计算公式:
上述公式最后一步和推理阶段循环表示公式中各个元素的对应关系是:
对应论文中的图示: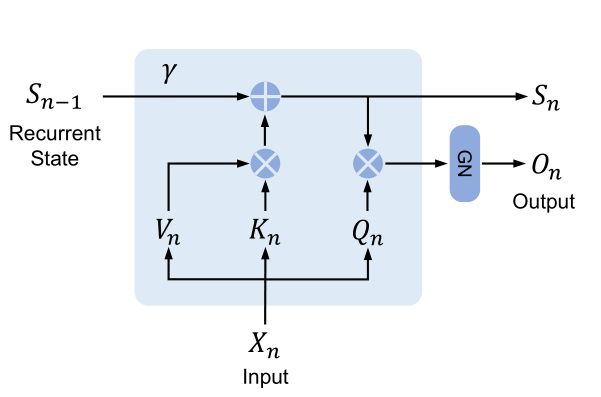
图中的 表示 GroupNorm。
可以看到在推理阶段,RetNet 在计算当前时间步 的输出 只依赖于上一个时间步产出的状态矩阵 。
其实就是把计算顺序改了一下,先计算的 和 的相乘然后一直累加到状态矩阵 上,最后再和 相乘。
而不是像 Transformer 架构那样,每个时间步的计算要先算 和前面所有时间步的 相乘得到 attention 权值再和 相乘求和,这样就需要一直保留历史的 和 。
Gated Multi-Scale Retention
然后 RetNet 每一层中的 Retention 子模块其实也是分了 个头,每个头用不同的 参数,同时每个头都采用不同的 常量,这也是 Multi-Scale Retention 名称的来由。
则对输入 , MSR 层的输出是:
其中, , 是激活函数用来生成门控阈值,还有由于每个头均采用不同的 ,所以每个头的输出要单独做 normalize 之后再 concat。
参考资料
-
[1] https://arxiv.org/pdf/2307.08621.pdf -
[2] https://en.wikipedia.org/wiki/Euler's_formula -
[3] https://en.wikipedia.org/wiki/List_of_trigonometric_identities -
[4] https://github.com/microsoft/torchscale/blob/main/torchscale/architecture/retnet.py