
爬虫实战三:关键词搜索小红书帖子
没想到上一篇爬虫抓取小红书图片的文章阅读量还不错,正好有朋友也提了抓小红书帖子的需求,我们一起来看下:
上次提到,抓数难度上 App>网页版>=微信小程序,所以当时选择小红书的微信小程序来下手的。但经过测试后发现小程序有个限制:选择不同的品类可以返回上限1000条,但搜索关键词时却只能返回100条帖子,数量太少。
小红书的网页版没有搜索关键词的入口,小红书App中搜索关键词是没有100条数目限制的(但经过测试有1000条的限制,我们后续再讲)。
正常的爬虫流程都是研究搜索关键词的请求,然后去破解相关参数来仿造请求;但今天我来展示一种不破解、纯刷帖的爬虫方法,同样可以安全快速抓取到想要的结果。
先说下大致思路:首先配置好手机和电脑 Charles,使得手机端浏览小红书帖子时在电脑端可以抓包(手机端刷到的帖子可以在电脑端 Charles 加载出来);完成配置后在手机端运行脚本自动下划刷帖子;最终将 Charles 中的数据包进行解析拿到结果。
1. root手机配置
此方法最难的点就是 Charles 抓包,正常情况下我们手机打开小红书 App 是抓不到包的,这时就只能拿 root 过的手机来碰运气。
手机ROOT通常是指针对Android系统的手机而言,它使得用户可以获取Android操作系统的超级用户权限。
百度百科-手机ROOT
比较幸运,拿root过的手机可以直接截到小红书搜索关键词的包(废话,不然也不会有这篇文章了):
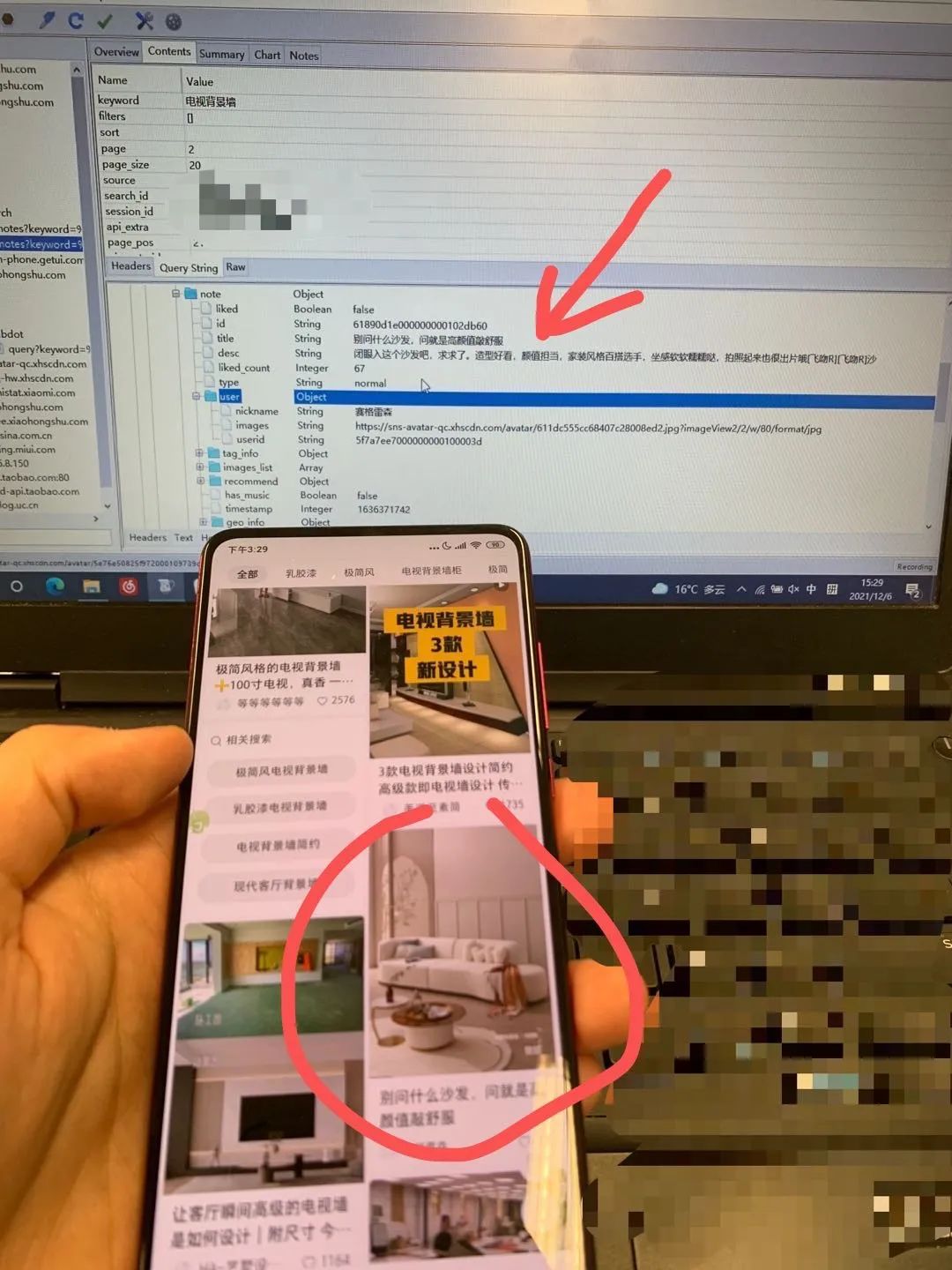
root 手机是个比较复杂的工程,我也是工作需要才接触到这玩意,所以这也算是层门槛,没有资源的朋友权当看个思路吧。
2. 脚本刷帖
想必大家也听说过手机自动刷抖音、刷帖子,这里推荐下 AutoJS (只适用于安卓机)。我们只需先在小红书中搜索特定关键词,之后设置好刷帖动作和间隔时间,运行脚本便可以自动刷帖了:
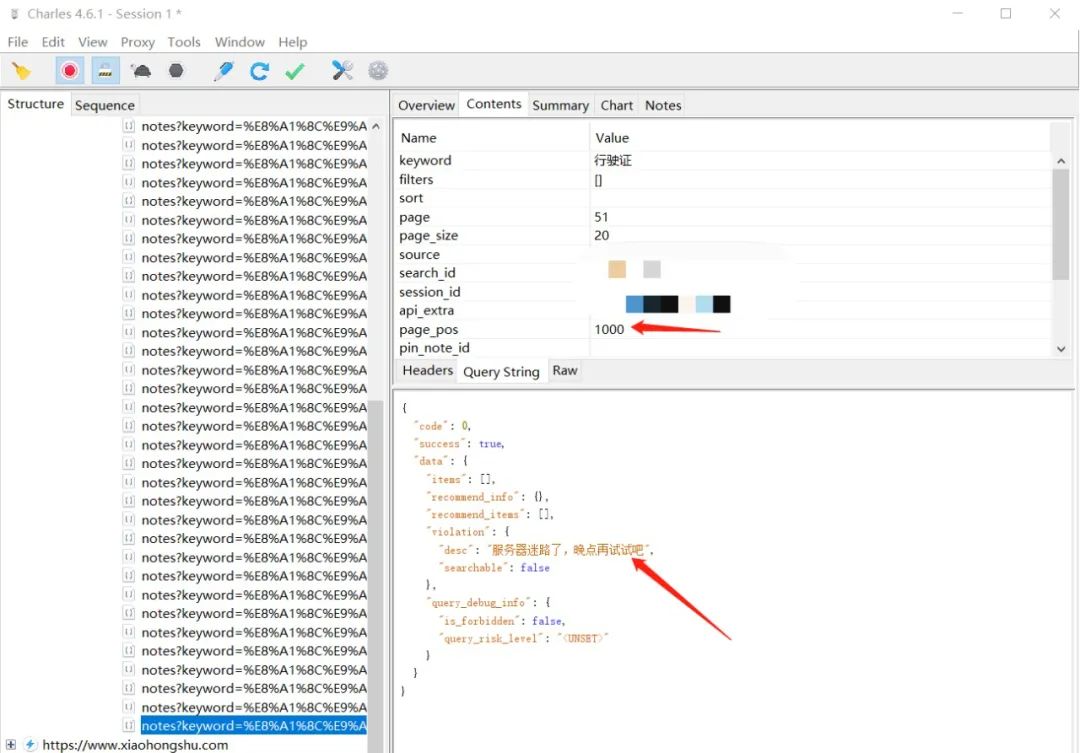
经过脚本的测试,发现搜索关键词出的帖子是有1000条数目限制的,手机端刷到最后是这样的:

电脑端抓到最后:
3.抓包并解析
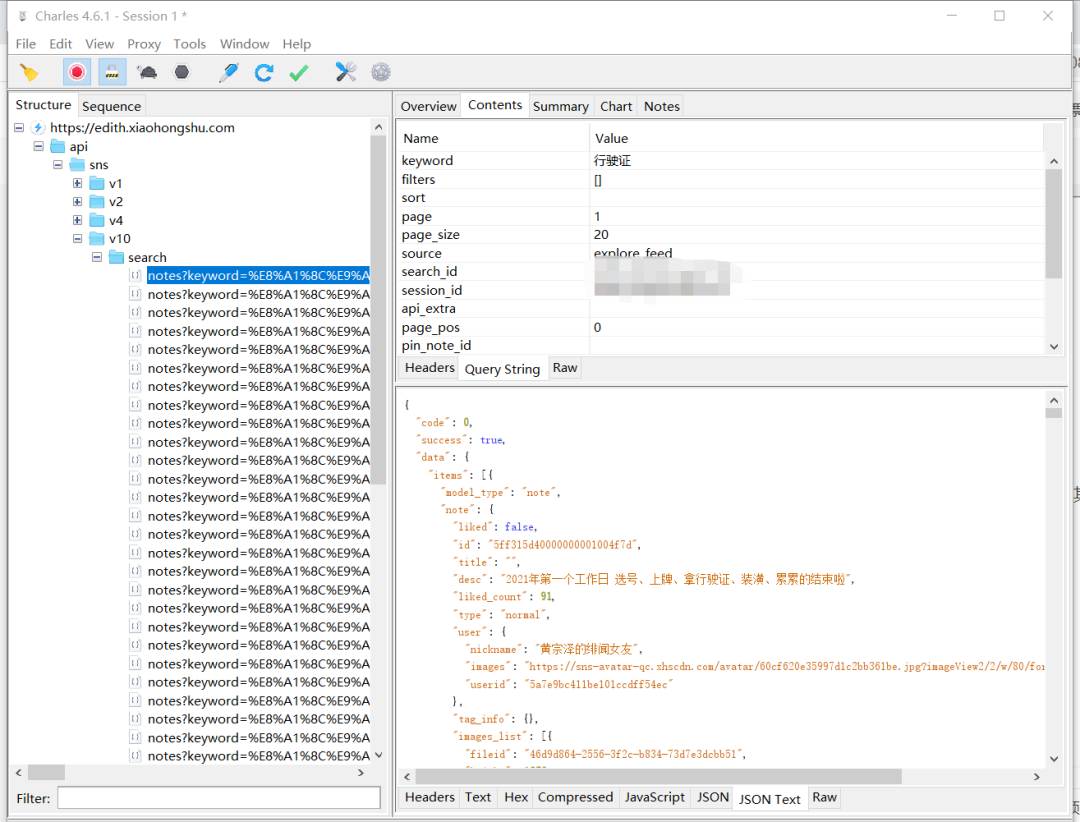
将 Charles 中所有帖子对应数据包保存到本地,针对其数据格式通过代码解析成 Excel 格式的数据结果。
比如 Charles 端加载的数据格式如下:
最终按所需的字段整理出 Excel 结果:

最终,便能顺利抓取到每个关键词对应的 1000 条帖子内容了。
如果觉得1000条帖子太少,注意看下小红书搜索关键词时可以还有很多可选项,比如“最热”、“最新”,以及相关的分类。同时虽然是关键词搜索,但其返回的结果也是推荐流形式,所以不同的时间、不同的账号、不同的限定条件下刷出的内容大概率也不相同。
毕竟海量帖子里随随便便捞1000条都是轻而易举的,比如搜“行驶证”:
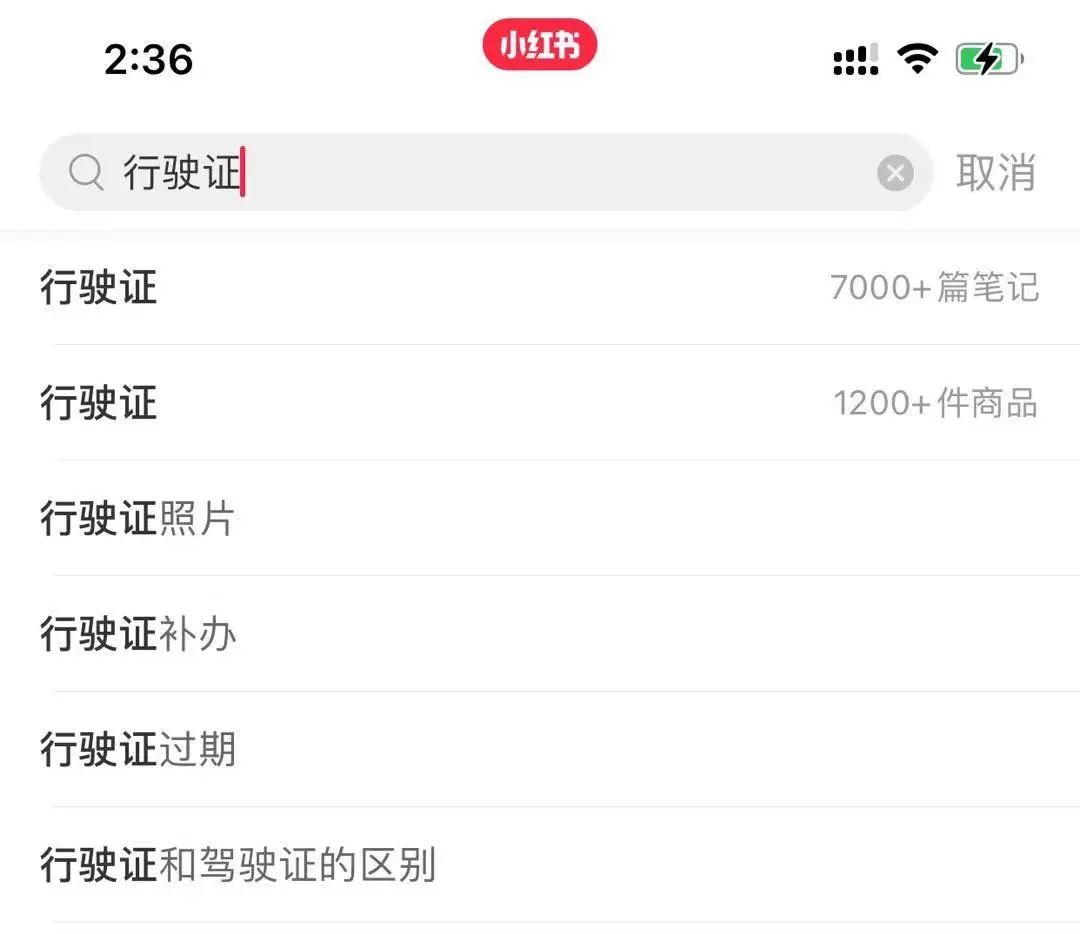
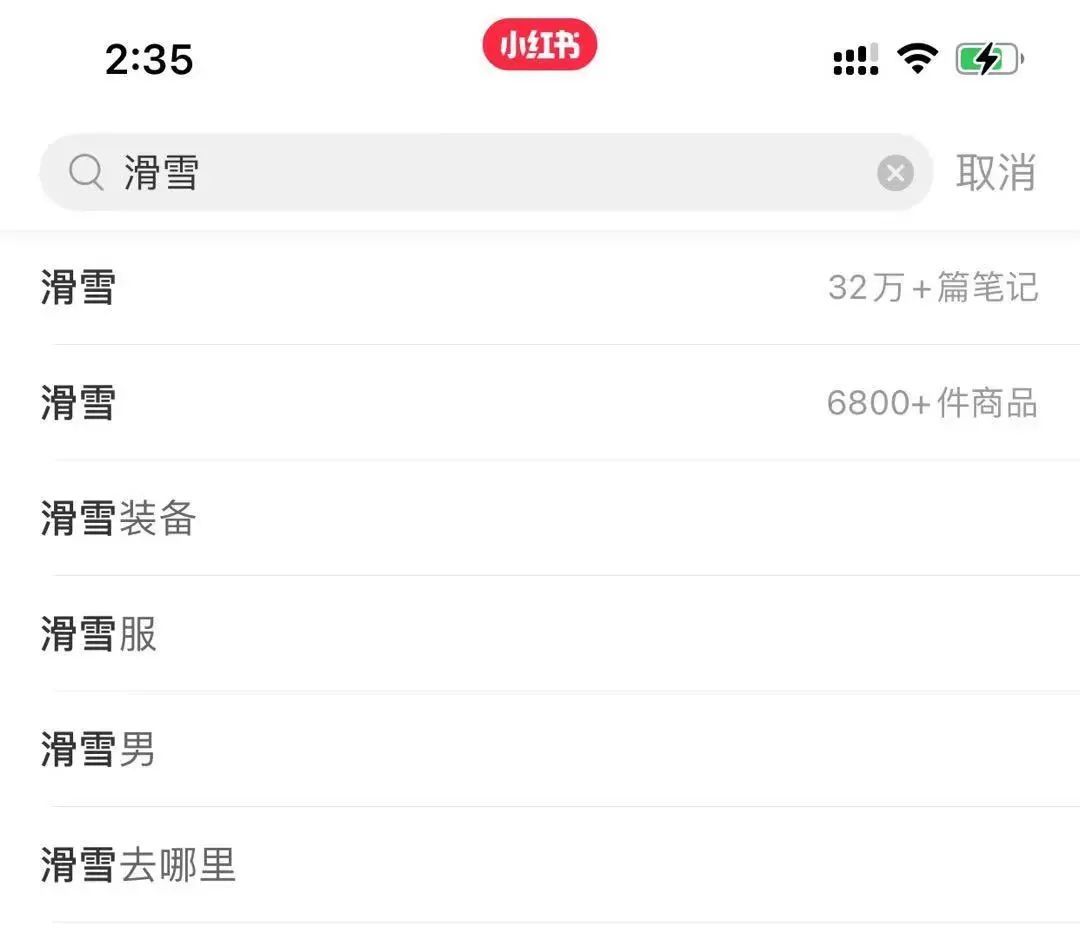
再比如搜个“滑雪”:
4.爬虫的价值
单纯从数据层面上看,这些爬虫抓取到的帖子可以分析广告、商品投放情况等,还可以针对不同品类下的帖子内容进行研究等。
我们普通用户刷小红书是满足个人需求基本用不到爬虫,通常爬虫数据都是拿来做数据分析和调研。这里也可以比较直观地看到爬虫在某些情景下也是高效获取数据的途径。
那么回归现实,如果自己做不到爬虫想去买数据,我随便搜了下淘宝爬虫小红书的商家,问了下价格:
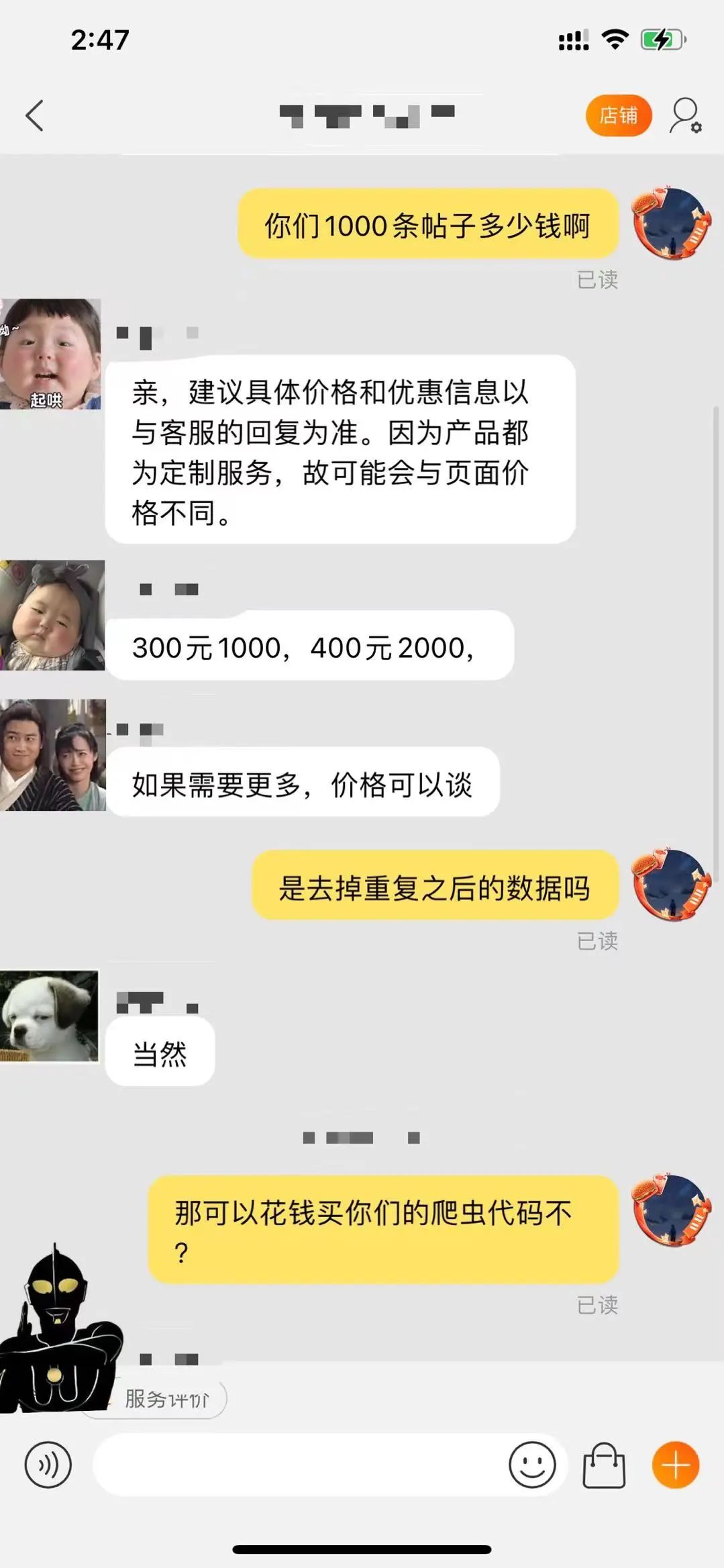
数据很值钱。
最后,再说回爬虫方法上,经过一番搜索以及与淘宝商家的交流,小红书爬虫多数是破解加密参数后仿造请求来抓取数据的。这个破解过程涉及的知识点就更多了,也有一定风险,后续有机会我们再探讨;手机刷帖配合电脑抓包解析,最大程度上模拟用户操作,在很多情况下反倒是不错的选择。
最最后,细心的你可能注意到了文章里的截图时间,没错,是凌晨。十点到家到现在,要搞到 3 点了,如果文章对你有帮助,求个赞不过分吧~
如果你也有关于爬虫、自动化等需求或想法,欢迎来交流哦~!

●就想写个爬虫,我到底要学多少东西啊?(转自崔庆才,爬虫大佬哦)