
性能超MAE、BEiT和MoCoV3!商汤&港中文提出MixMIM:在混合图像上进行MIM

极市导读
导读本文作者提出了混合(Mixed)和掩蔽(Masked)图像建模(MixMIM),这是一种简单但有效的MIM方法,适用于各种层次的视觉Transformer。 >>加入极市CV技术交流群,走在计算机视觉的最前沿
【摘要】
在本研究中,作者提出了混合(Mixed)和掩蔽(Masked)图像建模(MixMIM),这是一种简单但有效的MIM方法,适用于各种层次的视觉Transformer。现有MIM方法将输入token的随机子集替换为一个特殊的[MASK]符号,目的是从损坏的图像重建原始图像token。然而,作者发现使用[MASK] token会大大减慢训练速度,并由于较大的掩蔽率(例如,BEiT中的40%),会导致训练和微调不一致。相反,作者将一个图像的mask token替换为另一个图像的视觉token,即创建一个混合图像。然后,作者进行双重重建,从混合输入中重建原始两幅图像,这显著提高了效率。虽然MixMIM可以应用于各种架构,但本文探索了一种更简单但更强大的层次Transformer,并使用MixMIM-B、-L和-H进行缩放模型。实验结果表明,MixMIM可以有效地学习高质量的视觉表示。
1 论文和代码地址

论文地址:https://arxiv.org/abs/2205.13137
代码地址:https://github.com/Sense-X/MixMIM
2 Motivation
以自监督的方式利用未标记的视觉数据来学习表示是一件有趣但富有挑战性的事情。继自然语言处理领域的BERT之后,掩蔽图像建模(MIM)预训练视觉表征在各种下游视觉任务(包括图像分类、目标检测、语义分割、视频分类)中展现出了强大的能力。
现有MIM方法通常使用[MASK] token替换部分输入token,并旨在恢复原始图像块。然而,使用[MASK] token会导致两个问题。一方面,预训练中使用的[MASK] token从未出现在网络微调阶段,导致预训练-网络微调不一致。另一方面,预训练网络在处理非信息性[MASK]符号时浪费了大量计算,使得预训练低效。当使用较大的掩蔽率时,这些问题会变得更加严重。例如,在BEiT中,在预训练中使用40%的掩蔽比率,即,40%的输入token被[MASK]符号替换。因此,BEiT需要相对更多的epoch进行预训练。此外,由于高掩蔽率导致了大量的与训练-微调不一致,BEiT在下游任务上的性能受到限制。
MAE不存在上述问题,因为它丢弃了mask token,并且只在轻量级解码器中使用了[MASK]符号。然而,MAE破坏了输入图像的2D结构,并且不适用于卷积网络或者层次的ViT结构。因此,目前如何用MIM有效与训练一个层次ViT结构(如Swin Transformer)是一个问题。
在这项工作中,作者提出了MixMIM,这是一种广义MIM方法,它利用了BEiT和MAE的优点,又避免了它们的局限性。给定训练集中的两幅随机图像,MixMIM创建一幅以随机混合mask为输入的混合图像,并训练一个层次ViT来重建两幅原始图像以学习视觉表示。从一个图像的角度来看,不是用特殊的[MASK]符号替换图像的mask token,而是用另一个图像的视觉token替换mask token。MixMIM采用编码器-解码器设计。编码器处理混合图像以获得两个部分掩蔽图像的隐藏表示,而解码器重建两个原始图像。
自注意操作有一个全局感受野,每个token都可以和其他token交互。完全融合两个部分图像的token也会导致预训练和微调的差异,因为这两组token可能来自外观显著不同的图像。为了避免引入新的差异,MixMIM使用了一种掩蔽注意机制来明确防止两组token之间的交互。此外,作者在层次编码器的不同阶段通过最近插值对混合掩码进行上采样,以匹配attention map的分辨率。
MixMIM可以广泛应用于预训练层次VIT,如Swin Transformer、PVT等。本文的MixMIM还探索了一种轻量级架构,将Swin Transformer修改为预训练和知识迁移的编码器。由于层次结构,MixMIM自然可以应用于目标检测和语义分割。根据实验结果发现,在模型尺寸和FLOPs相似的情况下,MixMIM在广泛的下游任务上始终优于BEiT和MAE,包括ImageNet、iNaturalist和Places上的图像分类、COCO上的目标检测和实例分割以及ADE20K上的语义分割。
3 方法
在本节中,作者将介绍所提出的MixMIM,用于通过岩壁图像建模学习视觉表示。作者首先回顾MIM,然后介绍MixMIM如何创建训练输入和执行图像重建,以及本文提出的架构。最后,作者提出了如何减少借口任务(pretext task)的难度,以提高预训练的效率。
3.1 A Revisit of Masked Image Modeling
继BERT之后,最近的工作提出了MIM用于学习视觉表征。给定输入图像x,MIM首先将图像分割为非重叠的图像patch。然后,采样随机mask,以掩蔽部分图像patch,并用特殊符号[MASK]填充掩蔽位置,,其中⊙ 表示按元素乘法。通过图像编码器对掩蔽图像进行处理以产生潜在表示,并利用轻量级解码器基于潜在表示重建原始图像。重建目标可以选择为归一化原始像素或视觉token。MIM计算重建图像patch和原始图像patch之间的均方误差(MSE)作为重建损失,,损失仅在mask patch上计算。预训练后,解码器被丢弃,编码器用于进一步微调下游视觉任务。
3.2 Mixed and Masked Image Modeling (MixMIM)

虽然之前的MIM在自监督的视觉表征预训练方面取得了很大的进展,但它们通常需要大量的时间来进行预训练。一个原因是,它们在处理非信息性[MASK]符号时浪费了大量计算。此外,使用[MASK]符号也会导致预训练和微调不一致,因为这些符号在微调期间从未出现。为了解决这个问题,作者从成对的未标记训练图像中创建混合图像作为训练输入,这些图像是通过混合两幅图像中的两组视觉token生成的,用于预训练。通过MixMIM对混合输入进行处理,同时重建原始图像。为了更好地将学习到的多尺度表示迁移到下游任务,作者引入了一个简单的层次视觉Transformer作为所提出的MixMIM的编码器。上图展示了本文的框架。
Mixed Training Inputs
给定两组随机训练图像的图像patch,作者通过使用或中相应的视觉token填充每个空间位置来创建混合图像。将M=1表示为从中选择token,反之亦然。因此,混合训练图像被表示为:
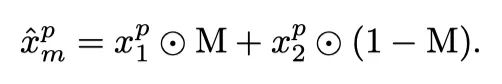
然后,MixMIM在预训练期间将混合图像作为重建输入。混合图像不再有额外的[MASK]符号,从而在下游任务中获得更好的性能。该设计与MAE的原理相同,但本文的方法没有分解2D图像的结构,使其更灵活地适应各种视觉主干,如PVT和Swin Transformer。作者按照常规做法使用随机掩蔽,掩蔽比为0.5,掩蔽patch大小为32×32。
Hierarchical Vision Transformer
为了更好地编码多尺度表示,作者基于Swin Transformer构建了MixMIM编码器,并引入了一些小的修改,使MixMIM编码器更简单但更强大。
与常规Swin Transformer类似,输入被分割为非重叠的图像patch,并由线性投影层进行处理。然后,添加了位置嵌入的图像patch由4个阶段的Transformer块处理,以生成层次表示,每两个连续阶段之间有一个下采样层。然而,作者不使用复杂的移位窗口来跨非重叠窗口进行信息传播。相反,作者使用相对较大的窗口大小(即14×14),并且只在第三和第四阶段进行全局自注意。较大的窗口大小带来的计算开销可以忽略不计,但可以更好地集成全局上下文。由于MIM中通常使用较大的掩蔽比,因此全局上下文对于更好的重建非常重要。作者发现,与Swin Transformer相比,更简单的结构在下游任务上具有更好的性能。
作者使用下面列出的配置参数缩放MixMIM编码器:
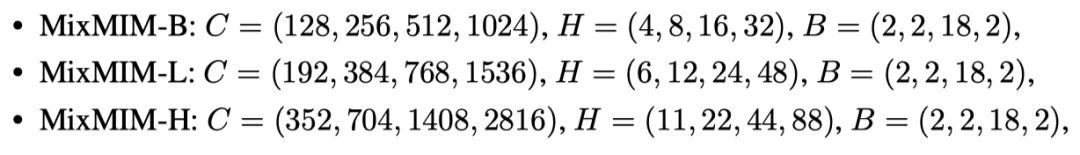
其中C、H和B表示通道数量、注意力头数量和每个阶段的block数量。在编码器和解码器之间添加线性层,以将编码器输出的嵌入维度转换为512。
Dual Reconstruction
在对混合输入进行编码后,作者根据掩码M将嵌入的token分解为两组。然后,作者使用解码器从这两组中重建原始的两幅图像,解码器有8个Transformer块,嵌入维度为512。因此,损失设置为
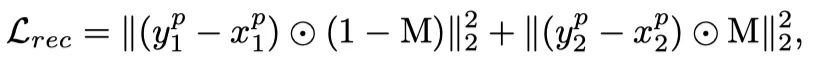
其中将对应于的重建图像。这背后的直觉是,由于混合输入包含来自两个图像的token,因此可以通过重建两个图像来对神经网络进行预训练来充分利用它们。由于解码器是轻量级的,因此重建两幅图像的计算开销可以忽略不计。本文的方法比以前的工作效率要高得多。
3.3 Reducing the Difficulty of the Pretext Task
虽然双重重建有几个优点,但由于图像token的混合,这是一个更具挑战性的优化问题,这会导致模型收敛缓慢。为了减少优化困难,作者通过探索以下方法来促进双重重建。
Mix embedding
除了位置嵌入之外,还向视觉添加了两个混合嵌入,以隐式区分这两个混合组。每个混合嵌入都是一个向量,并为来自同一图像的token共享。在实验中,作者对编码器的4个阶段使用不同的混合嵌入,并在每个阶段的开始添加嵌入。
Masked self-attention:
由于自注意力机制的灵活性,还可以通过掩蔽自注意力来明确区分两幅混合图像。具体而言,对于每个token,仅允许从属于同一图像的token聚合信息。作者通过重用混合掩码M来实现掩蔽的自注意力。此外,作者在不同阶段通过最近插值对掩模M进行上采样,以匹配特征图的分辨率。
两种方法都不会引入太多的计算开销或额外的参数。实验结果表明,这两种方法都可以帮助获得更好的结果。但是,第二种方法也导致更快的收敛速度,这对于大规模的预训练至关重要。默认情况下,使用的是第二种方法。
4 实验
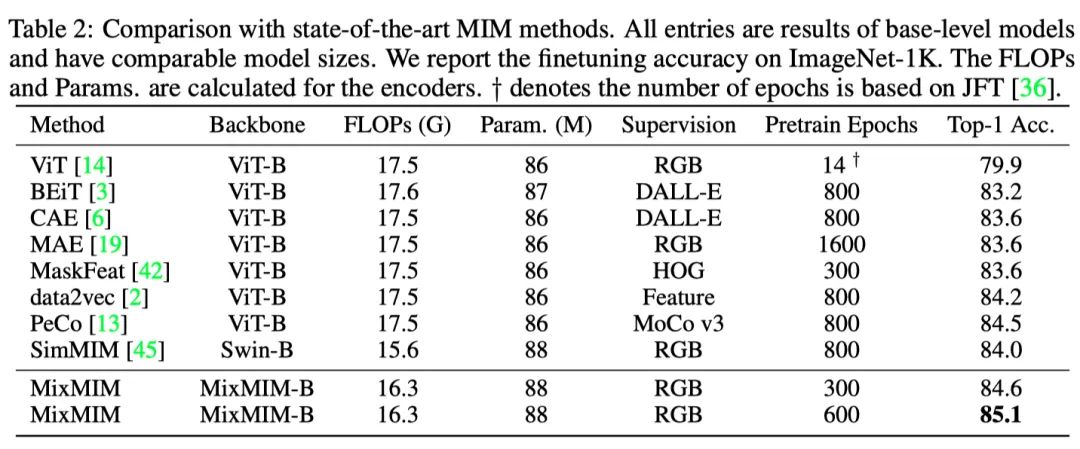
上表展示了MixMIM和SOTA的掩蔽图像建模(MIM)方法之间的比较。本文的MixMIM可以获得更高的精确度,同时需要较少的预训练时间。
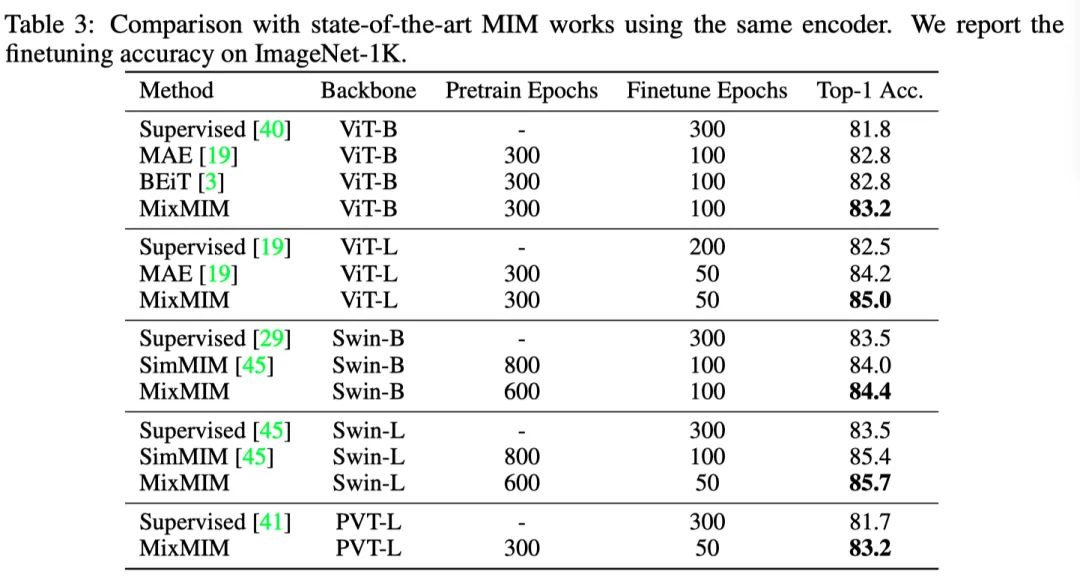
虽然之前的工作可能仅限于特定的结构,但本文提出的MixMIM可以推广到各种视觉主干,包括普通ViT、Swin Transformer和PVT。作者使用固定编码器与其他MIM方法进行了彻底的比较。如上表所示,MixMIM在预训练中使用相同或更少的时间,但始终获得更好的表现。
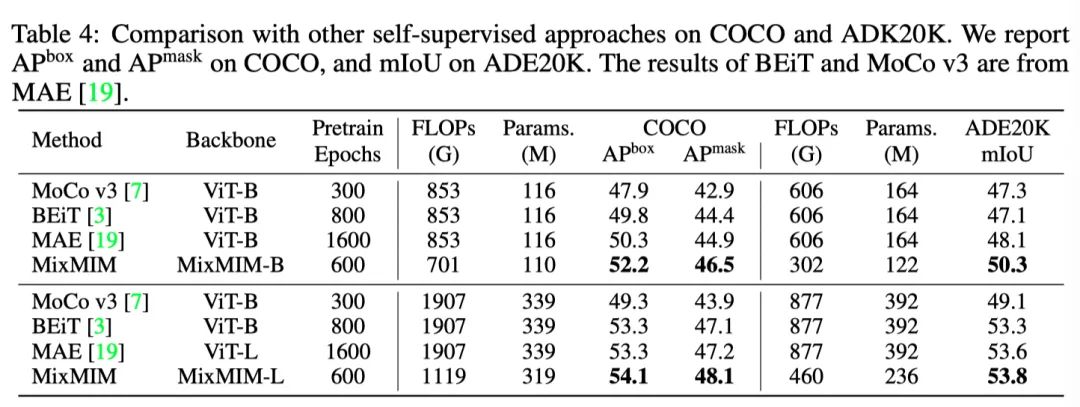
作者在上表中展示了COCO 的结果。通过在ImageNet-1K上对600个epoch进行预训练,本文的MixMIM-B实现了52.2和46.5,超过了以前的自监督方法,具有更少的FLOPs和参数。
本文的MixMIM还可以在目标检测任务中扩展到更大的模型,并获得更好的性能。如上表所示,本文的MixMIM-L实现了54.1和48.1,超过了以前的,比BEiT高出+0.8和+1.0,同时预训练所需的时间减少了200个 epoch,推理所需的FLOPs减少了41%。

作者进一步将MixMIM迁移到其他4个分类数据集,结果如上表所示。这些数据集具有挑战性,因为准确度相对较低,例如,MAE-B的Places365的top-1准确度为57.9%。本文的MixMIM仍然可以优于以前的自监督方法。
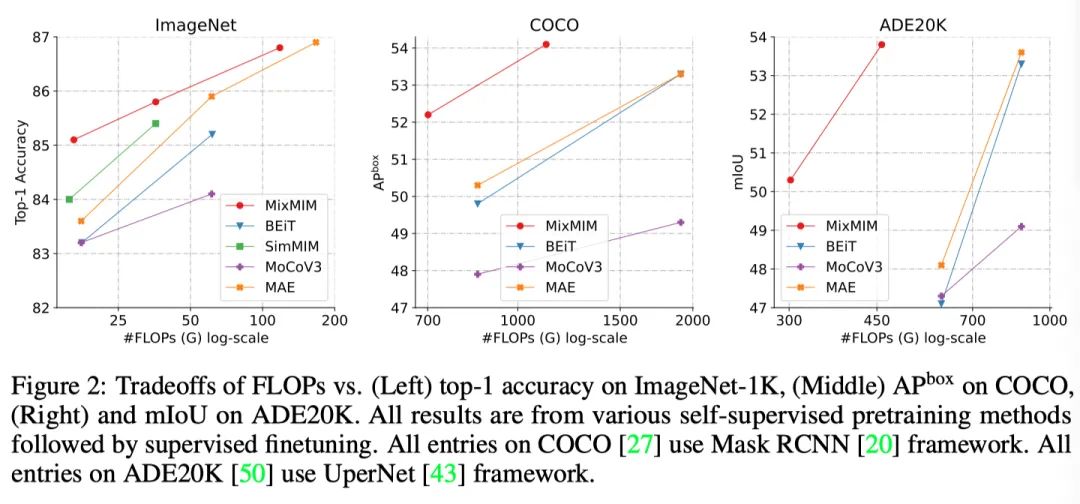
从上图中可以看出,在常见的CV任务,本文提出的MixMIM都具有明显的性能和效率优势。

作者提出了四种mask方式进行消融实验,四种方式的可视化例子如上图所示。

四种mask方式的消融结果如上表所示,可以看出相比于其他方法,Mix的方法性能最佳。

作者在上表中消融了提出的双重重建。双重重建大大提高了下游任务的性能。在ADE20K上,性能差距更大。由于解码器是轻量级的,所以双重重建的计算开销可以忽略不计。
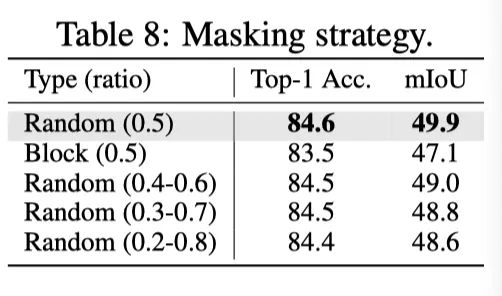
作者在上表中研究了掩蔽策略。与block掩蔽相比,使用随机掩蔽在下游任务上获得更好的性能。作者发现,使用block掩蔽往往会产生更大的预训练损失,这表明pretext任务更难学习。此外,作者发现使用0.5的掩蔽比效果最好。

由于双重重建,本文的MixMIM可以在很少的预训练时间内实现强大的性能,结果如上表所示。

为了降低优化难度,作者提出了两种方式来区分不同的图片patch,结果如上表所示,可以看出masked self-attention可以达到更好的结果。
5 总结
本文提出了一种混合掩蔽图像建模(MixMIM),用于有效的视觉表征学习。本文的MixMIM使用随机掩蔽混合两幅图像创建的混合输入,并应用双重重建从混合输入中恢复原始两幅图像。作者进一步探索了一种更简单但更强大的层次Transformer,以实现高效学习。在7个视觉基准上的实证结果表明,MixMIM可以有效地学习高质量的视觉表示,并且与之前的MIM作品相比,具有更好的FLOPs/性能权衡。
公众号后台回复“CVPR 2022”获取论文合集打包下载~

# 极市平台签约作者#

小马
作品精选
