
盘点数据挖掘竞赛中的泄露(Leak)
本文是姬哀同学总结的泄露案例和识别方法,非常值得阅读和学习,文章较长建议收藏。
0 前言
泄露是常见的。
如果在一场比赛的中后期,有一些队伍的成绩异常,明显超出常规方案所能达到的成绩,那么他们有可能找到了(或者无意中撞到了)泄露(除此之外还有可能是水平远超其它队伍、运气远超其它队伍、评测错误、多小号单测等)。
如果你认真做了很久仍然和前面的队伍有很大的差距,那么别灰心,你可以尝试着找找泄露。事实上,国内的数据挖掘竞赛中,大约有一半的赛题包含泄露,国外的比赛也常有泄露出现(当然,可能存在部分比赛包含无人发现的泄露)。
泄露是有趣的。
挖掘泄露是一件十分有趣的事情,有时甚至比完成原本赛题任务还要有趣。当然泄露的意义也不只存在于比赛之中。比赛的赛题通常是对真实业务问题的模拟。我常见到有数据挖掘工作者在解决真实业务问题时,设计的测试方案包含泄露,导致他们的方案的评测效果能够轻松达到99%,但实际效果不佳。
挖掘和利用泄露常需要较强的数据理解能力和分析能力,需要利用我们所掌握的各种信息来分析可能存在的问题,并想办法证实和加以利用。挖掘和利用泄露的能力应该是数据挖掘者的基本技能之一,这种能力与解决真实业务场景中的一般数据挖掘问题的能力是相仿的,找泄露和找特征并没有很大的区别,分析数据也是正常的数据挖掘流程中的必要步骤。
本文将对数据挖掘竞赛中出现的泄露进行总结,并列举这些泄露案例。 其中一部分是我及其他江离数据挖掘俱乐部成员参加过的、用过的泄露,也有一些是其他人提供给我们的泄露(这部分泄露已注明提供者和提供地点)。部分泄露略为复杂,需要对赛题有一定的理解才能明白。
1 绪论
泄露(xièlòu,也作泄漏、洩露、洩漏,也可以读作xièlù;英文leakage,也作leak)。数据挖掘竞赛的泄露:
我给出的定义是「数据挖掘竞赛中, 因为赛题方的失误 ,参赛选手可以取得的意料之外的信息」 ; 另一个常见的定义是「数据挖掘竞赛中, 不能应用于真实业务场景的信息」;
这两个定义有时会有差别。我更倾向于前一个定义。因为我认为赛题方不希望参赛者掌握的信息,即便可以应用于真实业务场景,也应属于泄露。
反之亦然;如果在参赛者发现了一个疑似的泄露之后,赛题方出来说「我们本来就希望你们能够掌握这个信息」,那么就应该不算泄露。本文以下说的泄露,包含这两种定义下的泄露,因而可能包含一些有争议的泄露。
有些比赛的泄露可以大幅提升成绩,也有些比赛的泄露对成绩影响不大。有些比赛中排名靠前的所有队伍都用了泄露,也有些比赛只有个别队伍发现了泄露并偷偷利用。
有些比赛的泄露非常明显,一不小心就会撞到;也有些比赛的泄露十分隐蔽,要从一些反常之处出发仔细分析才能挖掘出。有的比赛在泄露被指出后,赛题方及时更新赛题或数据,消除了泄露;也有的比赛,赛题方默许参赛者使用泄露;还有的比赛自始至终始终没有人指出泄露,但个别或者大量队伍在默默地使用。
泄露的分类是一个比较复杂的问题。本文将尝试对泄露做一些简单的分类。
对泄露的态度
比赛中的泄露是赛题方不认真、不专业造成的,应由赛题方自行负责。对于参赛者来说,泄露信息只是普通的、可以利用的信息,和其它信息并没有区别。
参赛者没有义务去区分哪些是普通信息、哪些信息是泄露信息,也没有义务帮赛题方找泄露、解决泄露,或是自觉不使用泄露,更没有义务帮赛题方隐瞒泄露。
参赛者既可以私下里和主办方沟通,指出泄露,也可以直接将泄露公布到比赛讨论群或是论坛中,还可以不告诉任何人,自己偷偷地使用,而不需要有任何心理负担。要求参赛者在发现泄露后及时公开或是主动自觉地不使用是一种道德绑架。
在一些比赛中,赛题方在泄露被指出后,要求参赛者自觉不使用泄露,这是一个十分无理的要求。正确的做法应该是更换数据,自行消除泄露。
在比赛中使用泄露不应该被认为是作弊。参赛者凭借自己的数据分析和业务理解能力找到泄露,用来提升成绩无可厚非,并没有违反比赛规则;而在很多比赛中,泄露事实上是公开的,排名靠前的队伍也并非是靠泄露取胜的。我们不应该对在包含泄露的比赛中取得名次的队伍有什么特别的想法。
但要指出的是,部分参赛者凭借泄露取得了较好的成绩,却在分享他们的方案时隐瞒了这个事实,这是需要受到批评的。这种做法可能会误导其他参赛选手,使他们错误地关注一些并没有出色效果的方案。
我在此前一些比赛中的做法也存在这类问题;我已经做了反思,并会在今后加以注意。由于我坚决反对数据挖掘竞赛的答辩,我不会对答辩中陈述自己方案时的任何隐瞒或欺骗行为加以指责;但如果是靠泄露取得成绩的,在答辩后应如实地给大家讲清楚。
如何挖掘泄露
那么如果我们怀疑某场比赛有泄露,我们如何挖出他们呢?
很遗憾,我也并不特别擅长挖掘泄露,我用过的很多泄露都是来自他人的指点,因而不能向大家传授更多的经验。我只能建议大家:可以多分析历史比赛的泄露案例,根据这些案例寻找类似的泄露;或是从一些数据的异常分布、成绩的异常变化入手,顺藤摸瓜地找出泄露。
标识类泄露
这是最低级的泄露了,通常由于主办方未正确进行脱敏而导致。
标识泄露
即标识中包含的泄露,通常各种标识(如用户标识、商品标识等)中不应该包含任何有效信息,如果某些标识包含了有效信息,那么很有可能属于「赛题方不希望参赛者掌握的信息」。(当然有些赛题中标识包含的信息是主办方希望参赛者掌握的,这种应该不属于泄露)
案例:客户用电异常行为分析
这场比赛的用户标识为一个整数,这个整数和标签强相关,并且远强于常规特征。直接将这个整数的每一位作为特征来训练就能得到较高的成绩。
然后复赛时赛题方对用户标识做了MD5处理,但由于预先知道是原始标识是整数,直接遍历整数的MD5就很容易逆推出原始标识(有大神直接分享了逆推的结果);最终主办方放弃了对这个问题解决,默许了选手使用这个泄露。
这里脱敏的正确的做法应该是打乱之后取序号作为新的标识。
案例:津南数字制造算法挑战赛
这场比赛的数据中,id相邻的样本标签一般会比较接近。后来这场比赛中途更换了一份不包含id的数据,去掉了这个泄露。
案例:AI战疫·成药属性预测大赛
泄露情况暂未知。

主办方发文承认泄露并更新数据和清空排行榜,是正确的处理办法;但「因部分选手将id列算做有效特征」一句将问题归于选手的态度却不够端正。正确的态度应该类似这样。
行(Row)号泄露
(对Row和Column的翻译一向很混乱,这里的行指Row。)即行号中包含的泄露。有些比赛在提取数据之后未进行正确的打乱,导致行号和标签相关。
案例:OGeek算法挑战赛(2018)
这场比赛的数据结构如下:

其中训练集和测试集可能会有完全相同的样本,但这并不是泄露,因为相同的样本可能是不同用户做出的相同查询,也可能是相同用户做出的两次查询,因而标签并不一定相同。这也符合正常的业务场景。
这场比赛的泄露在于,如果训练集和测试集的相同行号的样本恰好相同,那么它们极有可能是同一个样本,并有相同的标签。例如,训练集和测试集都有样本("花小皮", 《花小皮女装攻略》),它们未必有相同的标签;但如果它们分别是各自的1357行,那么它们大概率标签相同。这个泄露的原因不明,留给大家思考和想象。
案例:ACCV 2020 Webly-Supervised Fine-Grained Recognition Challenge
这场比赛给出的提交样例没有打乱顺序,其顺序就是测试集类别的顺序。只需要按照每类20张图,对于提交样例的文件顺序进行切分,就能获得测试集所有的真实标签。

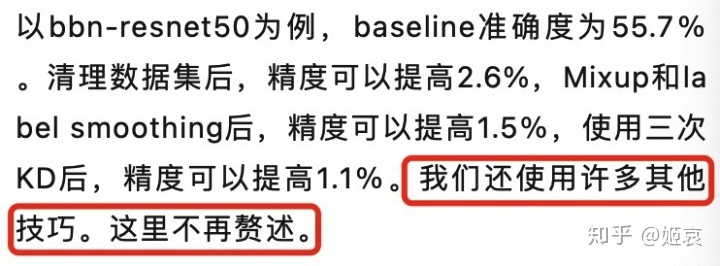
这场比赛后来换了新的测试集,但是没有公布老测试集的标签;相当于发现泄露的人多10w干净的训练数据,体现在排行榜上就是68直接到71。如冠军方案解读所述,第一名使用「不再赘述」的其他技巧直接提升将近6个点。
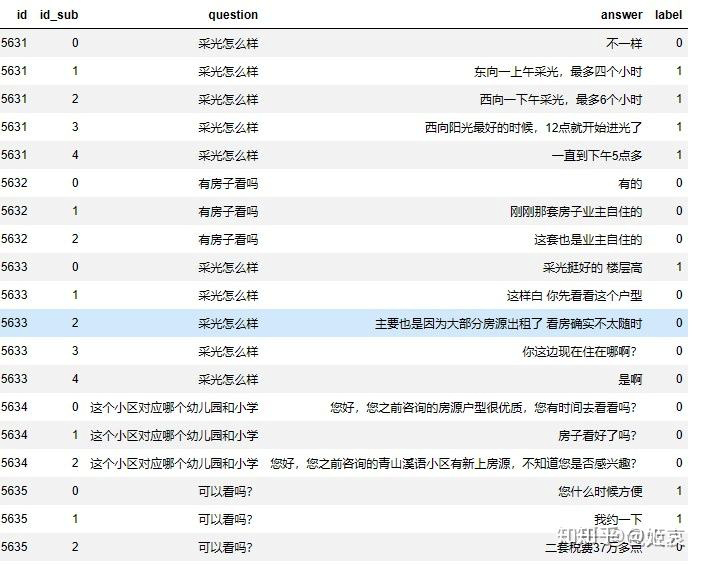
案例:房产行业聊天问答匹配
标签中存在连续的1,因为构造数据没有shuffle,连续的回答question的answser紧靠在一起,并且都是同一个answer。所以这不仅仅是个NLP的问题,当然这也是聊天中存在的问题,就是有人习惯一个问题,分好几句来回答。
元信息泄露
一些文件的元信息,如时间戳等,也包含和答案有关的信息。
案例:Two Sigma Connect: Rental Listing Inquiries
这场比赛表格数据没有泄露,但是给出的图片数据的保存时间戳含有部分信息量。这场比赛进行的过程中,有人指出这个泄露,主办方默许大家使用。
案例:混凝土泵车砼活塞故障预警
这场比赛可以根据时间戳区分正负样本。这场比赛后来更换了数据,消除了泄露。
每条样本都是一个设备一段时间内的若干条传感器采样数据,单独存放一个csv文件,就会有很多csv文件,然后正样本的文件创建时间和负样本的是先后关系没打散。
案例:“华为・昇腾杯”AI+行人重识别(2020)
这场比赛的数据是一些从监控视频中截取的图片。对于每张待测图片,要求参赛者识别出包含相同行人的图片。

经过观察可以发现,**图片的ID已经被打乱顺序,但图片的时间戳并没有被重置。按时间戳对图片进行排序,可以发现相同的行人会出现在时间相近的图片中。**可以利用这一点轻易找出包含相同行人的图片。
数据分布类泄露
这种比较常见。由于赛题方没有正确地处理数据而导致。
穿越泄露
大概属于最常见的数据分布类泄露了吧。测试样本的答案(或是一些有用的、原本得不到的信息),被泄露给了参赛者。有两种常见的情况:
某条测试样本的标签(或相关特征)被包含在其它测试样本中; 某条测试样本的标签(或相关特征)被包含在本应该无关训练样本中。
穿越泄露常由不正确的时间划分导致。 例如给出5月份的10000条样本,要求预测6月份的10000条样本。那么我们在预测6月1日的数据时,可以利用6月2日的测试样本所包含的信息;又或者我们将5月份的样本随机分成两份,用其中的5000条去预测另外5000条,那么我们也同样可以在训练集中找到泄露信息。
有些同学在做线下测试时,由于没有确保线下训练数据和线下测试特征数据中不包含线下测试数据的标签信息,引起了类似穿越泄露的问题,这通常表现为线下效果极好,但线上效果极差。
对于有时间先后顺序的问题,最可靠的做法就是卡时间,比如卡7月3日,给出7月3日之前的数据做训练样本,7月3日一天的数据做测试样本;如果一天之内还泄露,那么就卡小时、卡分钟。如果这样的数据量太少,那么就应该办成代码赛,选手调用赛题方提供的接口获取数据,提交这一份数据的预测结果才能获取到下一份测试数据。
另外还有一些影响比较小的泄露。例如很多赛题的特征可以将训练集和测试集放到一起归一化,这应该也属于穿越泄露(可能有争议)。这种泄露比较广泛,但影响很小,这里就不举例子了。
案例:生活大实惠:O2O优惠券预测
这场比赛是一个二分类问题。给出3, 4, 5, 6月份的用户领券数据及消费数据,以及7月份的用户领券数据,要求参赛者预测7月份的用户消费情况。
这场比赛包含了典型的穿越泄露。比如一个用户7月16日领了优惠券,我们可以利用该用户7月17日、18日等的数据来做预测,例如我们可以提取距离下次领券时间、后续领券次数、后续消费次数等泄露特征。
这场比赛进行的过程中,没有人指出这个泄露,主办方也没有对这个泄露做任何处理。不过排名靠前的队伍大概都用到了这个泄露。
案例:用户预订售卖房型概率预测
这场比赛的数据结构如下:
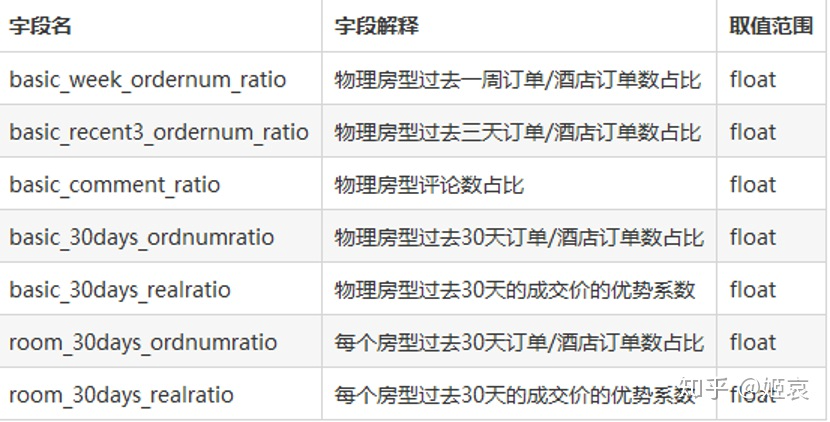
题目要求预测7天的数据,所以前6天的数据在这些特征上是穿越的。我们可以训练两个模型来分别预测前6天和第7天。
案例:“达观杯”个性化推荐算法挑战赛
这场比赛的目标是利用一批用户和候选资讯内容数据,预测每个用户在第4天(记为第N+1天)会产生行为的资讯列表。
赛题方另外提供了一份公开测试数据供下载测试,公开测试数据不包含计算排行榜时用到的用户。但这份公开测试数据给我们提供了一个比较好的候选资讯,相当于本题额外给了一些其他用户在第4天的行为。
这场比赛中大家基本都是通过这份公开测试数据来构造候选集。
案例:摩拜杯算法挑战赛
这场比赛给出用户的骑行的起点,要求预测用户当次骑行的停车地点。其中有部分用户可以从给出的骑行记录中获得下次骑行的起点以及时间,并将这些信息作为特征。
这场比赛中途有人指出这个泄露。赛题方过滤掉了出现过多次的用户,消除了泄露。
案例:TalkingData AdTracking Fraud Detection Challenge案例:IJCAI-18 阿里妈妈搜索广告预测
题目都是常规的点击率预估(CTR)或是转化率预估(CVR)类题目。这类题目要求预测用户是否点击或是转化,通常会给出用户在一段时间内的所有记录,于是我们就可以利用未来的数据来统计当次距离下次、下下次等的时间间隔、记录数等特征。
这类泄露一般都被默许使用。
案例PAKDD2020 阿里巴巴智能运维算法大赛
赛题方给出了20170731-20180831的硬盘SMART数据(各种状态)及这期间故障的数据;然后给出了20180901-20180930的硬盘SMART数据,要求我们利用这些SMART数据预测哪些硬盘在哪一天会发生故障。
我们可以注意到硬盘在故障之后就不会有SMART数据,因此我们可以直接将硬盘最后一次出现的日期预测为故障(当然实际上是利用这个泄露来选取候选)。
这场比赛的赛题方在这个泄露被指出后要求选手不得使用这个泄露,并承诺会在比赛结束后仔细核查选手的代码,但实际上可能并未做任何相关的检查。
案例:CCF 路况状态时空预测
这场比赛的数据结构如下:
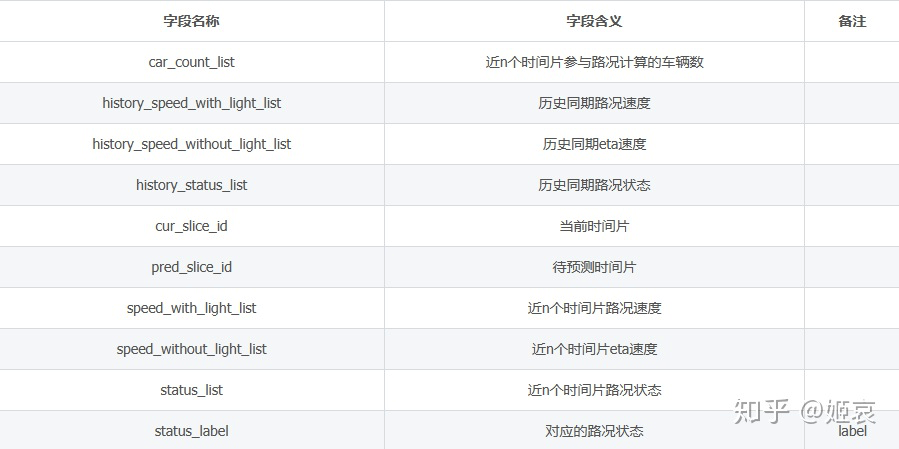
注意每个待测样本都给出了近n个时间片的路况信息。比如某路段当前时间是12:00,待测时间是12:20,那么就会给出11:50~12:00内的路况信息; 如果这个路段同时还要求预测11:50这个时间的路况,那么我们就可以直接得到答案。
(20201118日更新)赛题方已更新测试集数据。新数据不再有「某一路段待测时间或其邻近时间的路况出现在其它测试样本中」的情况。暂未发现新数据中包含可以影响成绩的泄露。
采样泄露
这种泄露是由赛题方采样时用到测试集的标签信息导致的。这种不恰当的采样方式可能会使标签信息在数据分布中留下痕迹,我们可以根据数据分布来逆推出标签。
案例:Byte Cup国际机器学习竞赛
这场比赛的样本是(用户, 问题),即邀请一个用户回答一个问题,要求预测用户是否真的会回答这个问题。一个用户可能被多次邀请回答同一个问题,因此训练集和测试集中有一些重复的(用户, 问题)。
泄露在于,用户被多次邀请回答同一个问题时,最多只能回答一次。 因此对于一个待测样本,如果这个用户在训练集中已经回答了这个问题,那么测试集中的标签便一定是0。
赛题方在B榜数据中悄悄地去掉了训练集中回答过的样本,消除了这个泄露。
案例:某比赛
这场比赛给出了500万条行为记录数据和20万件商品信息数据;这20万件商品中,有19万多件都在行为记录中出现,唯有300件商品十分突兀地出现在了商品信息数据中。
那么这300件商品来自哪里呢?不难猜出,它们来自测试集的答案。因此我们预测的时候,将这300件作为候选,就能得到较高的分数。
这场比赛复赛中由于赛题的改变,这个泄露消失了。
案例:某比赛
这场比赛的正样本的占比很小,因此赛题方对测试集的负样本进行了1/10采样,正样本没有采样。可是经过对数据的分析,我们发现,正样本都是成类目出现的(也就是说,如果某一个样本是正样本,那么它的同类目样本也很有可能是正样本)。
于是我们只要找出出现较多的类目,并把这一类目的样本预测为正样本就可以了(因为出现较少的类目很有可能是被采样了,因而是负样本)。
不确定这场比赛是否包含这个泄露,更不确定是否有人用到。
案例:阿里巴巴高德地图AMAP-TECH算法大赛
这场比赛中,每个样本给出了几张车载视频图片,要求我们判断图中的路况是畅通还是拥堵;此外每张图片还给出了时间,原意是希望参赛者们利用时间信息,例如高峰时间的路况更容易出现拥堵。
但很快有同学通过分析数据发现,大部分样本中,不同图片之间的时间间隔都是5秒;然而有部分样本的图片间时间间隔超过5秒,而这部分样本绝大部分都是拥堵。 这是一个很强的特征,比图片特征要强得多。
这个泄露产生的原因,推测是人工打标签的时候,拥堵的时候多确认了几张图片,造成给出的图片被向后移动,导致时间间隔变大。
这场比赛的赛题方在这一泄露被指出之后,在复赛中没有给出图片的时间信息,消除了这一泄露。
直接给出的泄露
还有一些题目,数据中直接给出了本不该给出的信息,有时甚至直接给出了标签。
案例:安泰杯跨境电商智能算法大赛
安泰杯的主办方十分虚心,而且在很多方面都做得非常专业,超过大部分其它的天池比赛。但这场比赛有两个较为明显泄露。
这场比赛给了一批训练用户,给出他们在一段时间内的交互商品序列;又给了一批测试用户,给出他们在一段时间内的交互商品序列,要求预测这些用户接下来一次购买的商品。
我们可以以用户前面交互过的商品为候选,以是否是接下来购买的商品作为标签,训练一个二分类模型。 然后我们可以注意到,数据中的buy_flag不是这次记录是否购买,而是当天是否购买了这件商品!而接下来一次的购买日期,大概率就是给出的序列中的最后一天,那么我们可以直接从候选商品中排除掉最后一天出现且buy_flag为0的商品。
另一个泄露见下图:

给出这样的特点描述确实难能可贵。但是我们注意看第3条。很多测试用户浏览过的商品,原本可能作为候选被预测,但由于没有出现在训练集中,而可以被我们直接排除。
这两个泄露都不是正常的业务中能取得的,而且都有明显的提升。在比赛过程中,没有人向主办方指出这些泄露。排名靠前的队伍可能用了它们。
相关阅读: