
开源!基于Transformer改进YOLOv5的目标检测框架 | 航空遥感目标检测
来源:https://zhuanlan.zhihu.com/p/525649526 (已授权)
编辑:AI算法与图像处理
大家好,我是阿潘
今天分享航空遥感目标检测系列文章之基于Transformer改进YOLOv5的目标检测框架
标题:TPH-YOLOv5: Improved YOLOv5 Based on Transformer Prediction Head for Object Detection on Drone-captured Scenarios
地址:https://openaccess.thecvf.com/content/ICCV2021W/VisDrone/papers/Zhu_TPH-YOLOv5_Improved_YOLOv5_Based_on_Transformer_Prediction_Head_for_Object_ICCVW_2021_paper.pdf
代码:https://github.com/cv516Buaa/tph-yolov5
改进版本:https://github.com/Gumpest/YOLOv5-Multibackbone-Compression
增加小目标检测层:https://mp.weixin.qq.com/s/3ecefgmOZU-zugMdMWlTaA
详细介绍
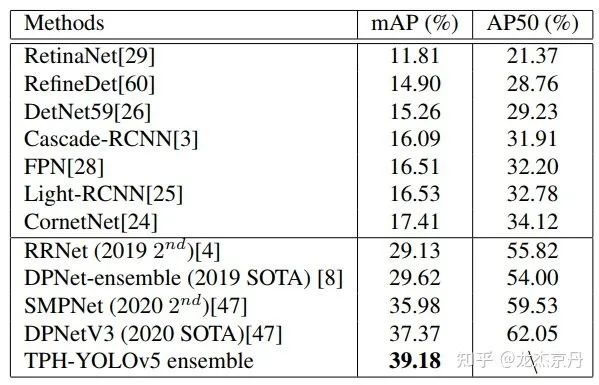
本文主要针对尺度变化和由于高速低空拍摄带来的密集目标运动模糊这两个问题,提出一种TPH-YOLOv5。基于YOLOv5,增加一个预测头来检测不同尺度的目标。然后用结合Transformer的预测头(Transfromer Prediction Head, TPH)代替原始的预测头,来探索具备自注意力的预测潜力。此外,还结合了卷积块注意模型(CBAM)来搜索密集区域的感兴趣区域。为了更进一步的提升性能。本文还提供了很多有用的策略,例如数据增强、多尺度测试、多模态融合和利用额外的分类器。在VisDrone2021数据集上进行实验,证明了所提方法的有效性和优越性。在测试集上,所提方法达到39.18%的AP值,比先前的SOTA方法(DPNetV3)提高了1.81%。在2021年的VisDrone挑战赛上,所提的TPH-YOLOv5获得第五名的成绩,与第一名的模型(AP 39.43%)保持相当的成绩。与基准模型(YOLOv5)相比,所提方法提高了约7%。
Motivation:

航拍图像中需要解决的三个问题:从第一行到第三行分别表示尺度变化、高密度和大范围。首先,由于无人机飞行高度的不同,目标的尺度变化剧烈。其次,无人机拍摄的图像包含高密度的目标,导致目标间存在严重遮挡。再次,由于很大的覆盖范围,无人机拍摄的图像通常包含令人混淆的地理元素。

贡献:
增加一个预测头来解决目标间的尺度变化;
在YOLOv5中结合Transformer预测,可以精确的定位高密度场景中的目标;
在YOLOv5中结合CBAM,可以使网络在大范围区域中找到感兴趣区域;
提供大量有用的tricks并滤除一些无用的tricks,用于航拍图像的目标检测
利用自训练分类器来提升一些容易混淆的类别间的分类能力;
在VisDrone2021数据集上进行实验,获得很不错的检测性能。
方法:
YOLOv5回顾
YOLOv5包含四个不同的模型,包括YOLOv5s,YOLOv5m,YOLOv5l,YOLOv5x。一般来讲,YOLOv5分别使用一个结合空间金字塔池化层(SPP)的CSPDarknet53作为主干网络,PANet作为Neck,YOLO作为检测头。为了进一步优化整个网络,提供了大量的技巧。因为这个网络是最著名且方便的一阶段检测器,本文选择它作为基准算法。
当作者在VisDrone2021数据集上结合数据增强策略(Mosaic和MixUp)对模型进行训练时,从结果中可以看出YOLOv5x的性能比其他三个好得多,AP值之间的差距超过1.5%。尽管YOLOv5x的训练代价比其他三个模型都要大,本文依然选择YOLOv5x来实现最好的检测性能。此外,根据无人机拍摄图像的特征,对常用的光度畸变和几何失真的参数做出调整。
2. TPH-YOLOv5
TPH-YOLOv5的框架如下图所示,作者对原始的YOLOv5框架进行修改使之适应VisDrone2021数据集。
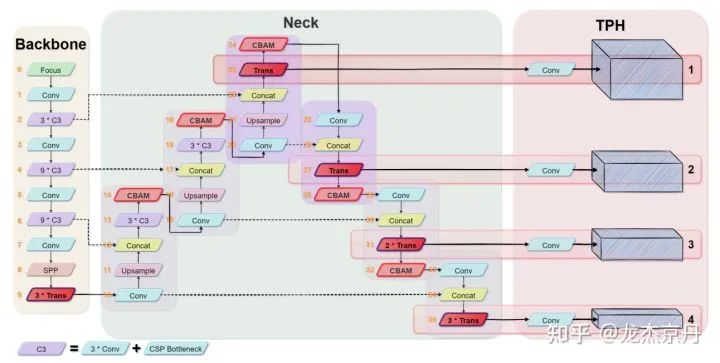
用于微小目标的预测头:作者通过对VisDrone2021数据集进行调研,发现它包含了大量的极度小目标,因此作者额外增加了一个预测头用于微小目标的检测。与其他三个预测头进行联合,本文提出的四分支检测结构可以减轻由于剧烈尺度变化引起的负面影响。如上图所示,第一个预测头是由底层的、高分辨率的特征图中生成的,这对微小目标更敏感。增加一个附加的检测头之后,尽管计算量和内存代价增加了,但微小目标的检测性能得到了大幅的提升。
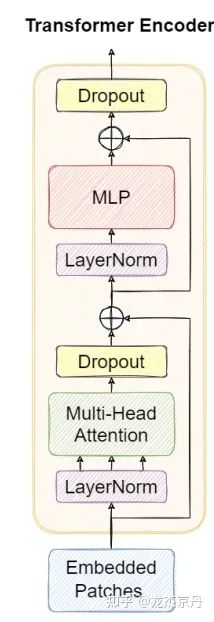
Transformer编码块:受视觉Transformer的启发,本文用Transformer的编码块来代替原始YOLOv5中的一些卷积块和CSP瓶颈块。这个结构如下图所示。与原始CSPDarknet53中的transformer瓶颈块相比,作者相信transformer编码块能够采集丰富的全局信息和上下文信息。每个transforme编码包含两个子层,第一个子层是一个多头的注意力层,而第二个子层(MLP)是一个全连接层。在每个子层中间添加残差连接。Transformer编码块增加了采集不同局部信息的能力。它还可以通过自注意力机制挖掘特征表示的潜能。在VisDrone2021数据集中,transformer编码块对于高密度的遮挡目标具有更好的检测性能。
基于YOLOv5,本文只在头网络部分应用了transformer编码块来构成Transformer预测头(TPH)和主干网络的后端。因为网络后端的特征图分辨率很低,在低分辨率特征图上应用TPH会减少昂贵的计算代价和内存代价。此外,当对输入图像的分辨率放大时,作者选择性的在早期层去掉一些TPH块,使得训练过程可行。
卷积块注意力模块(CBAM): CBAM是一个简单且有效的注意力模块。这是一个轻量的模块,可以插入到大多数主流的CNN框架中,而且可以以端到端的形式进行训练。给定一个特征图,CBAM连续地从空间和通道两个分离的维度推断注意图,然后通过将注意图与特征图相乘进行自适应的特征精炼。CBAM的结构如下图所示。根据CBAM原文中的实验,通过将CBAM融入到不同的模型中,在不同的分类和检测数据集中进行实验,模型的性能得到很大的提升,也证明了这个模块的有效性。

在无人机拍摄的图片中,大范围的区域通常包含很多使人混淆的地理元素。使用CBAM可以帮助TPH-YOLOv5提取受关注区域,减少易混淆信息并关注有用的目标信息。
多尺度测试和模型集成:本文根据模型集成的不同角度训练五个不同的模型。在推断阶段,作者首先在单个模型上执行多尺度测试。多尺度测试的实现细节主要有以下三个步骤:1)将测试图像放大1.3倍。2)分别将图像减少到1倍,0.83倍和0.67倍。3)对图像进行水平翻转。最后,作者将六个不同的放缩图像送入TPH-YOLOv5网络中,然后使用NMS融合预测结果。
对于不同的模型,本文采用同样的多尺度测试,并通过WBF融合五个预测得到最终的结果。
自训练分类器:通过TPH-YOLOv5在VisDrone2021数据集上训练之后,作者在test-dev集上进行测试,然后分析了一些失败案例,总结出这个网络框架又很好的定位能力但是很差的分类能力。作者进而利用混淆矩阵发现一些困难类别,例如三轮车和带蓬三轮车的精度比较低。因此,本文提出一个额外的自训练分类器。首先通过裁减ground-truth的边界框和放缩每个图像块为64  64,构建一个训练集。然后,选择ResNet18作为分类器网络。正如实验结果中所示,依靠自训练分类器,本文方法得到将近0.8%~1.0%的性能提升。
64,构建一个训练集。然后,选择ResNet18作为分类器网络。正如实验结果中所示,依靠自训练分类器,本文方法得到将近0.8%~1.0%的性能提升。

Iou阈值是0.45时的混淆矩阵,置信度阈值是0.25
实验:
实验细节:Pytorch 1.8.1, NVIDIA RTX3090 GPU.
数据分析:根据作者先前的工程经验,在训练模型之前浏览数据集是很重要的,这对提升mAP的性能会有很大帮助。作者对VisDrone2021数据集中的边界框进行分析,当输入图像的尺寸设定为1536,总共342391个标签中有622个小于3个像素。如下图说是,这些小目标很难识别,当用灰色正方形包围这些小目标,并用来训练模型,mAP提升了0.2,比没有操作性能要好。
实验对比:
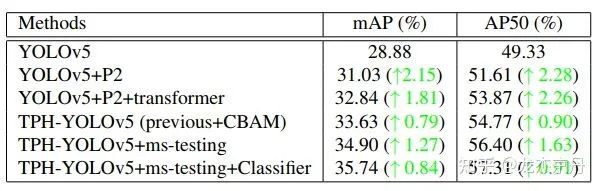
消融实验:
单类指标:

可视化结果:

结论与分析:
本文融入了很多先进的技术,例如transformer的编码块,CBAM和一些技巧,将这些技术融入到YOLOv5框架中,有利于航拍图像中的目标检测。所提方法在VisDrone2021数据集上刷新纪录,并达到SOTA的性能。作者尝试了大量的特征,并用其中一些来提升目标检测器的精度。
本文专门针对航拍图像数据集,融入了一些技术或模块,能够有效提升航拍图像目标检测的性能,这对航拍图像的信息理解有很重要的工程指导意义,而且也能够对其他具有类似场景中的图像处理。结合transoformer技术在CV的各个领域着实火了一把,但是这些方法的理论创新不是很大,很难有很大的理论贡献。下次我计划分享一篇切片辅助超推理的开源框架“Slicing Aided Hyper Inference and Fine-tuning for Small Object Detection”,且听下次分解!