点击上方“小白学视觉”,选择加"星标"或“置顶”
重磅干货,第一时间送达
来自 | 知乎 作者 | roger
链接 | https://zhuanlan.zhihu.com/p/138855612
编辑 | 深度学习这件小事
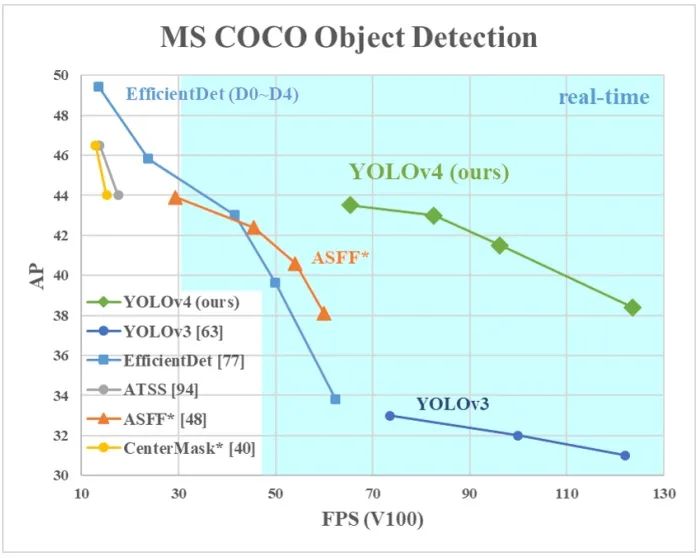
深度学习可以说是一门实验科学,业界要落地一个算法必然要尝试各种tricks,本文介绍目标检测领域的常用tricks,当然其中涉及到的一些tricks也可使用于其他任务,如mixup,label smooth等。YOLO-V4[1]将目标检测中的tricks分为以下两类,本文以此展开介绍:Bag-of-Freebies,在inference阶段不引入额外计算复杂度
Bag-of-Specials,在inference阶段引入的计算复杂度相比精度增加可忽略,这些tricks可认为增强了模型的某种属性,如增大了感受野、引入了attention机制、更好的信息融合等。
像素级别Data augmentation:最常用的bag-of-freebies,包含亮度、对比度、饱和度、噪声、旋转、flip,crop等。
模拟物体遮挡:下图是几种常用方法可视对比。在网络训练阶段,采用模拟遮挡的方式一方面可提升模型抗遮挡能力,同时这种方式相当于数据集层面的一种正则,帮助模型更好的学习全局信息。random erase/cutout:随机选择图片中一块矩形区域,将其像素值置为随机值或者0,模拟物体遮挡情况,这种数据增强方式在多个任务中均可提升模型精度;
grid mask:随机在图片中选择多个矩形区域,将像素值置为0;
HS(hide-and-seek):主要为解决弱监督检测问题中网络attention只集中在物体局部,导致检测框不准,HS训练中随机隐藏输入图像一部分区域,迫使网络学习到物体全局信息;
 dropout系列,包括dropout,dropconnect和dropblock,这三种方式都是提升模型抗过拟合能力,具体如下:
dropout系列,包括dropout,dropconnect和dropblock,这三种方式都是提升模型抗过拟合能力,具体如下:dropout,用于全连接层,以一定概率随机将输出神经元置0,BP阶段不更新对应神经元;
dropconnect,用于全连接层,以一定概率随机将神经元输入权重以一定概率置0;
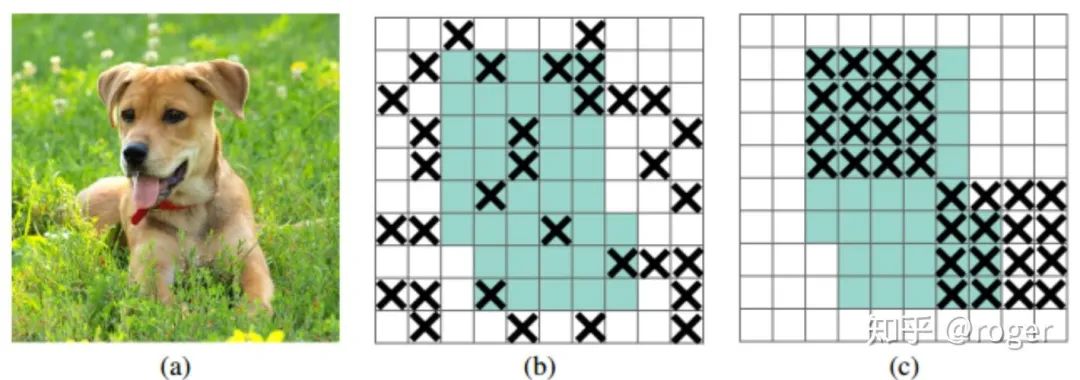
dropblock,如下图所示,随机将特征图某一个部分置为0,(b)作用于每一个像素,(c)作用于每一个block,对(b)来说,drop掉的像素的信息可以通过相邻像素学习得到,而(c)drop掉一块区域,会迫使网络学习其他区域信息,更有利于提取全局特征,效果更好,所以本方法称为dropblock。可以看到dropblock和random erase等有类似之处,不同在于random erase作用于输入图像,而dropblock作用于网络中间层特征图。
 多图融合的数据增强,主要包括mixup和cutmix,前面提到的像素级别数据增强作用于单个图像,mixup和cutmix作用于两个样本间,两者区别如下图,mixup依据一定的比例融合了两者图像,cutmix就是cut掉一张图片的部分区域,使用另一张图片部分区域进行填充。下图是mixup和cutmix的示例效果。
多图融合的数据增强,主要包括mixup和cutmix,前面提到的像素级别数据增强作用于单个图像,mixup和cutmix作用于两个样本间,两者区别如下图,mixup依据一定的比例融合了两者图像,cutmix就是cut掉一张图片的部分区域,使用另一张图片部分区域进行填充。下图是mixup和cutmix的示例效果。 mixup,下图是mixup计算方法,可以看到加权融合同时作用在图片和label两个维度。原作者在这里给出了mixup的解释。
mixup,下图是mixup计算方法,可以看到加权融合同时作用在图片和label两个维度。原作者在这里给出了mixup的解释。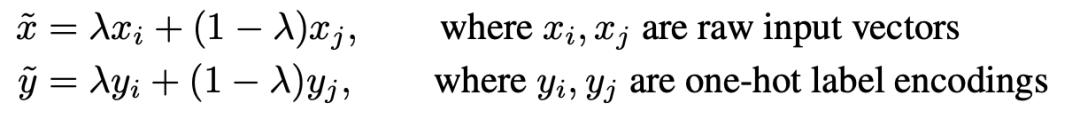 yolo-v4提出了Mosaic数据增强,融合了四张图片,如下图所示,而cutmix只融合了两张图片。作者采用这种数据扩增方式主要是为实现单卡训练模型,每一张图片相当于融合了四张图的纹理信息。
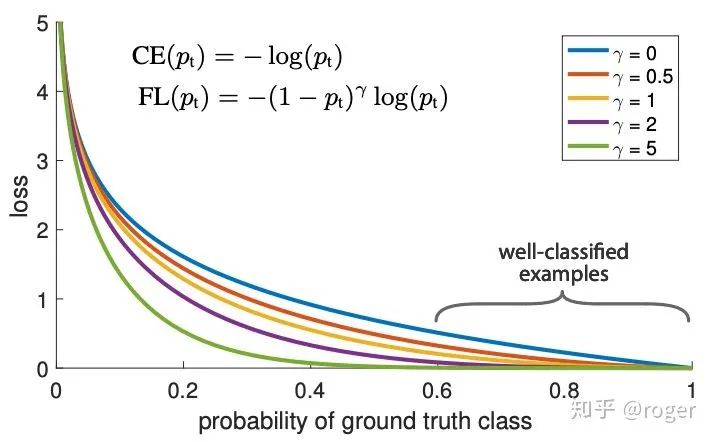
yolo-v4提出了Mosaic数据增强,融合了四张图片,如下图所示,而cutmix只融合了两张图片。作者采用这种数据扩增方式主要是为实现单卡训练模型,每一张图片相当于融合了四张图的纹理信息。 数据分布不均衡:目标检测的子任务之一是分类,对one-stage detector来说,负样本远多于正样本,若不做处理直接训练,模型偏向于将输入预测为负样本。SSD采取了基于分类置信度的难例样本挖掘策略,具体来说,选择分类置信度高的负样本(更容易分错)作为难例样本,最终保证正负样本比例为1:3进行训练,另一种难例样本挖掘策略基于分类loss,选择loss大的样本作为难例样本。前面提到的两种策略本质是在训练中均衡正负样本数量,但未考虑样本的分类难易程度,focal loss主要解决这一问题,在训练中减小易分类样本权重,增加难分类样本权重,如下图所示,
数据分布不均衡:目标检测的子任务之一是分类,对one-stage detector来说,负样本远多于正样本,若不做处理直接训练,模型偏向于将输入预测为负样本。SSD采取了基于分类置信度的难例样本挖掘策略,具体来说,选择分类置信度高的负样本(更容易分错)作为难例样本,最终保证正负样本比例为1:3进行训练,另一种难例样本挖掘策略基于分类loss,选择loss大的样本作为难例样本。前面提到的两种策略本质是在训练中均衡正负样本数量,但未考虑样本的分类难易程度,focal loss主要解决这一问题,在训练中减小易分类样本权重,增加难分类样本权重,如下图所示,  表示cross-entropy损失,
表示cross-entropy损失,  表示focal loss损失,
表示focal loss损失,  表示正确分类的概率,越大,表示越容易分对,对应权重越小,
表示正确分类的概率,越大,表示越容易分对,对应权重越小,  时,focal loss退化为普通的cross-entropy损失,
时,focal loss退化为普通的cross-entropy损失,  越大,对易分类样本施加的权重越小。
越大,对易分类样本施加的权重越小。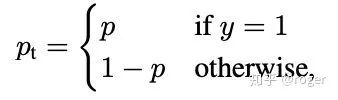
 标签平滑(Label smooth):深度模型训练中一般伴随着过拟合问题,常用的预防过拟合的方法包括l1/l2 正则,dropout等,这些方式作用于网络隐层权重,而label smooth作用于网络输出。分类网络一般采用one-hot编码,图片所属类别编码为1,其余类别位置编码为0,这种方式存在over-confident的问题,比如对一张标注为BMW的图片,其和标注为Audi的图片是存在一定的相似性,两者在分类label层面不应该是0/1关系,所以label smooth对标签做了软化,如下所示,对非标注类别制定一个很小的分类概率
标签平滑(Label smooth):深度模型训练中一般伴随着过拟合问题,常用的预防过拟合的方法包括l1/l2 正则,dropout等,这些方式作用于网络隐层权重,而label smooth作用于网络输出。分类网络一般采用one-hot编码,图片所属类别编码为1,其余类别位置编码为0,这种方式存在over-confident的问题,比如对一张标注为BMW的图片,其和标注为Audi的图片是存在一定的相似性,两者在分类label层面不应该是0/1关系,所以label smooth对标签做了软化,如下所示,对非标注类别制定一个很小的分类概率  。可以看到label smooth和knowledge distillation存在类似之处,只是KD中的软标签含有更丰富的不同类别间的建模信息。Bounding box regression:在目标检测中,预测框回归一般采用l2或者smooth_l1损失,这种方式存在两个问题:1、对框的尺度不具有不变性,即使YOLO-V1中对框的宽高取了根号进行回归,但仍然存在loss对不同尺度物体不一致的问题;2、物体检测采用mAP作为评判指标,其中判断预测框和GT是否match采用IoU,而相同l2损失的预测框和GT的IoU可能不一致,如下图所示,两者之间存在的这种gap表明了l2并不是在mAP这种评判机制下的最佳loss选择,一种好的损失函数应该和IoU一一对应关系。
。可以看到label smooth和knowledge distillation存在类似之处,只是KD中的软标签含有更丰富的不同类别间的建模信息。Bounding box regression:在目标检测中,预测框回归一般采用l2或者smooth_l1损失,这种方式存在两个问题:1、对框的尺度不具有不变性,即使YOLO-V1中对框的宽高取了根号进行回归,但仍然存在loss对不同尺度物体不一致的问题;2、物体检测采用mAP作为评判指标,其中判断预测框和GT是否match采用IoU,而相同l2损失的预测框和GT的IoU可能不一致,如下图所示,两者之间存在的这种gap表明了l2并不是在mAP这种评判机制下的最佳loss选择,一种好的损失函数应该和IoU一一对应关系。
 IoU损失的不足在于当两个框不相交时,不能反映两个框的距离远近,同时也不可导,GIoU解决了这一问题,计算方式如下图。GIoU损失=1-GIoU,可以看到当两个框不相交时,GIoU小于0,对这种情况惩罚更大。
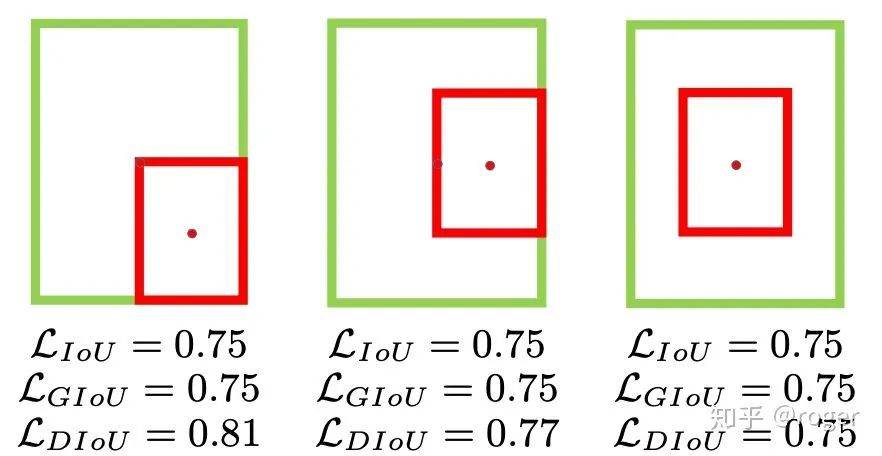
IoU损失的不足在于当两个框不相交时,不能反映两个框的距离远近,同时也不可导,GIoU解决了这一问题,计算方式如下图。GIoU损失=1-GIoU,可以看到当两个框不相交时,GIoU小于0,对这种情况惩罚更大。 GIoU的不足如下图所示,当两个框处于包含关系时,红色框在绿色框内不同位置时GIoU损失相等,但显而最右边的框位置最优,因为红色框和绿色框中心点位置最近,所以DIoU损失在IoU损失的基础上引入了中心点的距离,解决了这个问题,当然两个框不相交的问题通过这个约束也不存在了。DIoU损失如下式所示,其中
GIoU的不足如下图所示,当两个框处于包含关系时,红色框在绿色框内不同位置时GIoU损失相等,但显而最右边的框位置最优,因为红色框和绿色框中心点位置最近,所以DIoU损失在IoU损失的基础上引入了中心点的距离,解决了这个问题,当然两个框不相交的问题通过这个约束也不存在了。DIoU损失如下式所示,其中  表示两个框中心点距离,
表示两个框中心点距离,  表示两个框最小外接矩形对角线距离。DIoU优化函数中包含两个点距离,模型收敛更快。
表示两个框最小外接矩形对角线距离。DIoU优化函数中包含两个点距离,模型收敛更快。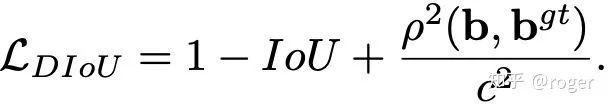
 CIoU全称complete-IoU,在DIoU的基础上添加了两个框宽高一致性约束。由以上可以看出,bounding box回归要求检测框和GT更加贴合,其中有三个关键点:1、重叠面积大;2、中心点距离近;3、宽高一致,CIoU就是按照这个要求来设计的。不过就本质来说,当两个框的重叠面积大时,那么2和3一定是满足的,这里额外约束2和3,其实是将其从1中解耦出来进行学习,添加了人为先验,降低了模型的学习难度,相当于告诉了模型按这个约束走下去会更好。增加感受野:SPP(spatial pyramid pooling)提出之初是为解决模型输入分辨率不一致的问题,它将输入特征图采用分块+pooling的方式,实现了对不同分辨率输入保持输出维度不变,如下图所示。
CIoU全称complete-IoU,在DIoU的基础上添加了两个框宽高一致性约束。由以上可以看出,bounding box回归要求检测框和GT更加贴合,其中有三个关键点:1、重叠面积大;2、中心点距离近;3、宽高一致,CIoU就是按照这个要求来设计的。不过就本质来说,当两个框的重叠面积大时,那么2和3一定是满足的,这里额外约束2和3,其实是将其从1中解耦出来进行学习,添加了人为先验,降低了模型的学习难度,相当于告诉了模型按这个约束走下去会更好。增加感受野:SPP(spatial pyramid pooling)提出之初是为解决模型输入分辨率不一致的问题,它将输入特征图采用分块+pooling的方式,实现了对不同分辨率输入保持输出维度不变,如下图所示。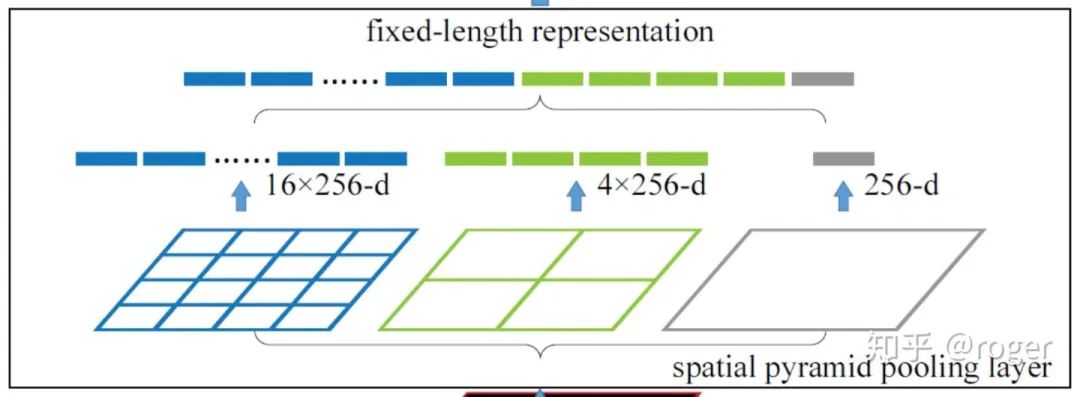 考虑到SPP最终输出的是一维向量,不适用于全卷积网络,所以yolo-v3作者对此改进,使用多个不同kernel size(如1、5、9和13)的卷积作用于输入特征图,最终输出通过concat各分支结果得到,这种方式通过使用大卷积核增加了感受野。可以看到,这种方式和GoogleNet中采用的inception module类似,都是在同一层使用了不同大小的卷积核,更进一步,MixNet中的MixConv采用了一种更简便的方式,将卷积通道分组,不同组使用不同大小的卷积核,以达到相似效果。ASPP和改进版的SPP类似,只是不同分支使用相同大小卷积核&不同的dilation rate,在不增加计算复杂度的情况下,提升模型感受野。attention机制:attention机制广泛应用于分类和目标检测领域,分为channel-wise attention和spatial attention,这两种方法的代表性工作为SE(squeeze-and-excitation)和SAM(spatial attention module)。SE是分类任务的标配,一般添加后都可带来1个点的提升。SAM在CBAM(convolutional block attention module)中提出,包含CAM和SAM两个模块,如下图所示,本质也是学习channel或者spatial维度的重要性,加权融合特征。attention机制有效的一种解释是为网络认为重要的信息提供了更流畅的信息通路。
考虑到SPP最终输出的是一维向量,不适用于全卷积网络,所以yolo-v3作者对此改进,使用多个不同kernel size(如1、5、9和13)的卷积作用于输入特征图,最终输出通过concat各分支结果得到,这种方式通过使用大卷积核增加了感受野。可以看到,这种方式和GoogleNet中采用的inception module类似,都是在同一层使用了不同大小的卷积核,更进一步,MixNet中的MixConv采用了一种更简便的方式,将卷积通道分组,不同组使用不同大小的卷积核,以达到相似效果。ASPP和改进版的SPP类似,只是不同分支使用相同大小卷积核&不同的dilation rate,在不增加计算复杂度的情况下,提升模型感受野。attention机制:attention机制广泛应用于分类和目标检测领域,分为channel-wise attention和spatial attention,这两种方法的代表性工作为SE(squeeze-and-excitation)和SAM(spatial attention module)。SE是分类任务的标配,一般添加后都可带来1个点的提升。SAM在CBAM(convolutional block attention module)中提出,包含CAM和SAM两个模块,如下图所示,本质也是学习channel或者spatial维度的重要性,加权融合特征。attention机制有效的一种解释是为网络认为重要的信息提供了更流畅的信息通路。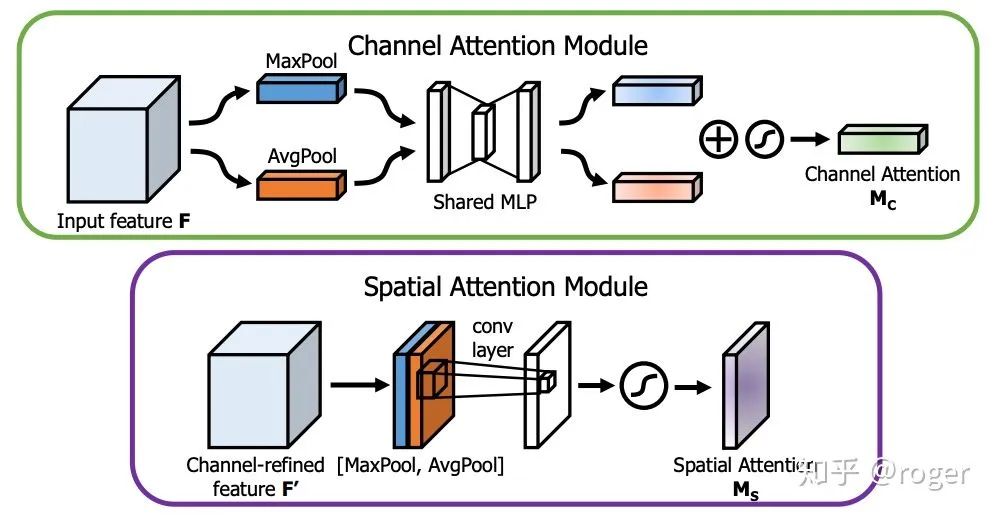 特征融合:自从FPN成为检测任务的标配后,如何融合不同层次的特征成为一个新的问题,这一方向的工作包含SFAM,ASFF和BiFPN。SFAM使用SE模块re-weight融合后的特征图,ASFF使用softmax re-weight融合后的特征图。这些方法的本质是自适应的融合不同level的特征,而不是手工采用concat或者sum的方式。激活函数:一个好的激活函数在不增加计算复杂度的情况下,可以让梯度传递通路更流畅。ReLU是现在最广泛使用的激活函数,相比sigmoid和tanh缓解了梯度弥散现象。LReLU和PReLU主要是解决ReLU在输出小于0时梯度为0的情况,ReLU6和Hard-swish主要应用于需要量化的模型,不过RegNet作者指出在轻量级模型中使用hard-swish效果相比relu好,对depthwise卷积更是如此,这也是为什么mobilenetv3中大量使用了hard-swish激活函数的原因。后处理:目标检测领域的后处理主要是NMS,当一个物体预测出多个框时,保留置信度最高的,去除其他的候选框,这种方式可能产生以下问题,红色框置信度相比绿色框置信度高,所以NMS选择保留红色框,但当两者IoU大于设定threshold时,绿色框会被移除,这样会产生漏检,Soft-NMS对这一问题进行改进,当两个IoU大于设定threshold时,降低绿框的置信度,而不是暴力的移除。anchor-free是目前目标检测的另一个研究方向,其中某些方法(如CenterNet)不需要NMS后处理。
特征融合:自从FPN成为检测任务的标配后,如何融合不同层次的特征成为一个新的问题,这一方向的工作包含SFAM,ASFF和BiFPN。SFAM使用SE模块re-weight融合后的特征图,ASFF使用softmax re-weight融合后的特征图。这些方法的本质是自适应的融合不同level的特征,而不是手工采用concat或者sum的方式。激活函数:一个好的激活函数在不增加计算复杂度的情况下,可以让梯度传递通路更流畅。ReLU是现在最广泛使用的激活函数,相比sigmoid和tanh缓解了梯度弥散现象。LReLU和PReLU主要是解决ReLU在输出小于0时梯度为0的情况,ReLU6和Hard-swish主要应用于需要量化的模型,不过RegNet作者指出在轻量级模型中使用hard-swish效果相比relu好,对depthwise卷积更是如此,这也是为什么mobilenetv3中大量使用了hard-swish激活函数的原因。后处理:目标检测领域的后处理主要是NMS,当一个物体预测出多个框时,保留置信度最高的,去除其他的候选框,这种方式可能产生以下问题,红色框置信度相比绿色框置信度高,所以NMS选择保留红色框,但当两者IoU大于设定threshold时,绿色框会被移除,这样会产生漏检,Soft-NMS对这一问题进行改进,当两个IoU大于设定threshold时,降低绿框的置信度,而不是暴力的移除。anchor-free是目前目标检测的另一个研究方向,其中某些方法(如CenterNet)不需要NMS后处理。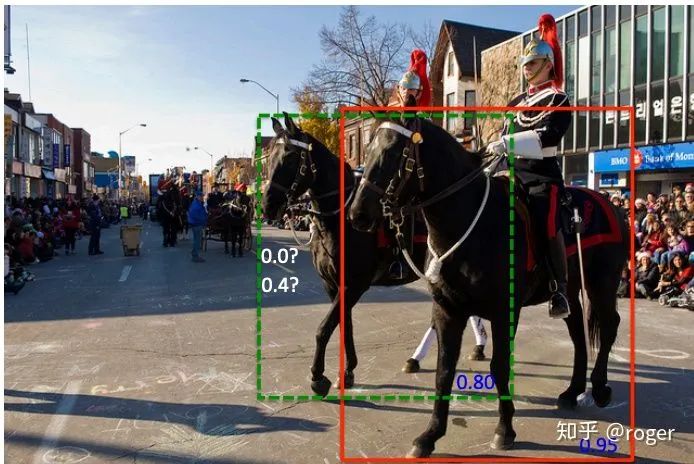
参考文献
https://arxiv.org/pdf/2004.10934.pdf下载1:OpenCV-Contrib扩展模块中文版教程
在「小白学视觉」公众号后台回复:扩展模块中文教程,即可下载全网第一份OpenCV扩展模块教程中文版,涵盖扩展模块安装、SFM算法、立体视觉、目标跟踪、生物视觉、超分辨率处理等二十多章内容。在「小白学视觉」公众号后台回复:Python视觉实战项目,即可下载包括图像分割、口罩检测、车道线检测、车辆计数、添加眼线、车牌识别、字符识别、情绪检测、文本内容提取、面部识别等31个视觉实战项目,助力快速学校计算机视觉。在「小白学视觉」公众号后台回复:OpenCV实战项目20讲,即可下载含有20个基于OpenCV实现20个实战项目,实现OpenCV学习进阶。交流群
欢迎加入公众号读者群一起和同行交流,目前有SLAM、三维视觉、传感器、自动驾驶、计算摄影、检测、分割、识别、医学影像、GAN、算法竞赛等微信群(以后会逐渐细分),请扫描下面微信号加群,备注:”昵称+学校/公司+研究方向“,例如:”张三 + 上海交大 + 视觉SLAM“。请按照格式备注,否则不予通过。添加成功后会根据研究方向邀请进入相关微信群。请勿在群内发送广告,否则会请出群,谢谢理解~