【关于 AAAI 2021 之 命名实体识别论文串烧】那些你不知道的事
作者:杨夕
论文学习项目地址:https://github.com/km1994/nlp_paper_study
《NLP 百面百搭》地址:https://github.com/km1994/NLP-Interview-Notes
个人介绍:大佬们好,我叫杨夕,该项目主要是本人在研读顶会论文和复现经典论文过程中,所见、所思、所想、所闻,可能存在一些理解错误,希望大佬们多多指正。
NLP && 推荐学习群【人数满了,加微信 blqkm601 】
1.2 命名实体识别
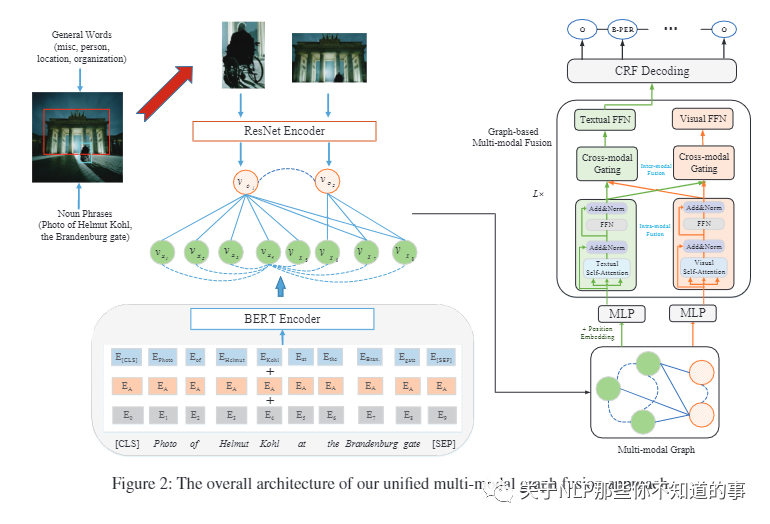
【Multi-Modal Graph Fusion for Named Entity Recognition with Targeted Visual Guidance (UMGF)】
作者:Dong Zhang,1Suzhong Wei,2Shoushan Li,1∗Hanqian Wu,2Qiaoming Zhu,1Guodong Zhou1
介绍:多模态命名实体识别 (MNER) 旨在发现自由文本中的命名实体,并将它们分类为带有图像的预定义类型。
动机:占主导地位的 MNER 模型并没有充分利用不同模态语义单元之间的细粒度语义对应关系,这有可能改进多模态表示学习。
论文方法:提出了一种统一的多模态图融合(UMGF)方法。
首先使用统一的多模态图来表示输入的句子和图像,该图捕获了多模态语义单元(单词和视觉对象)之间的各种语义关系。
然后,我们堆叠多个基于图的多模态融合层,这些层迭代地执行语义交互以学习节点表示。
最后,我们使用 CRF 解码器为每个单词和性能标记实现了基于注意力的多模态表示。
实验结果:在两个基准数据集上的实验证明了我们的 MNER 模型的优越性。
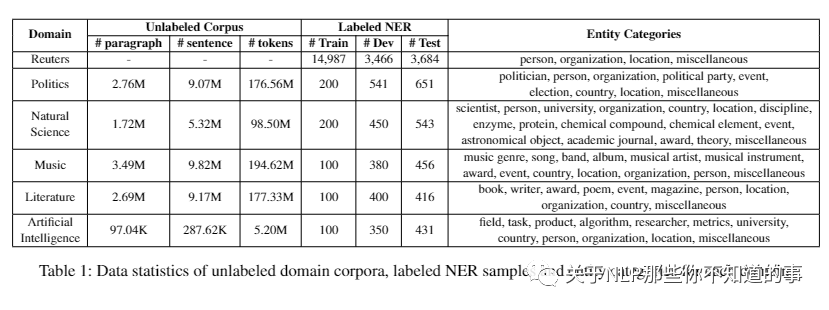
【CrossNER: Evaluating Cross-Domain Named Entity Recognition ()】 【github】
作者:Zihan Liu, Yan Xu, Tiezheng Yu, Wenliang Dai, Ziwei Ji, Samuel Cahyawijaya, Andrea Madotto, Pascale Fung
介绍:跨域命名实体识别 (NER) 模型能够解决目标域中 NER 样本的稀缺问题。
动机:大多数现有的 NER 基准缺乏专门领域的实体类型或不关注某个领域,导致跨领域评估效率较低。
论文方法:引入了跨域 NER 数据集 (CrossNER),这是一个完全标记的 NER 数据集合,跨越五个不同的域,具有针对不同域的专门实体类别。此外,我们还提供了一个领域相关的语料库,因为使用它来继续预训练语言模型(领域自适应预训练)对于领域适应是有效的。然后,我们进行了全面的实验,以探索利用不同级别的领域语料库和预训练策略对跨领域任务进行领域自适应预训练的有效性。
实验结果:结果表明,专注于包含领域专用实体的分数语料库并在领域自适应预训练中利用更具挑战性的预训练策略有利于 NER 域适应,并且我们提出的方法可以始终优于现有的跨域 NER 基线.尽管如此,实验也说明了这种跨域 NER 任务的挑战。我们希望我们的数据集和基线能够促进 NER 域适应领域的研究。
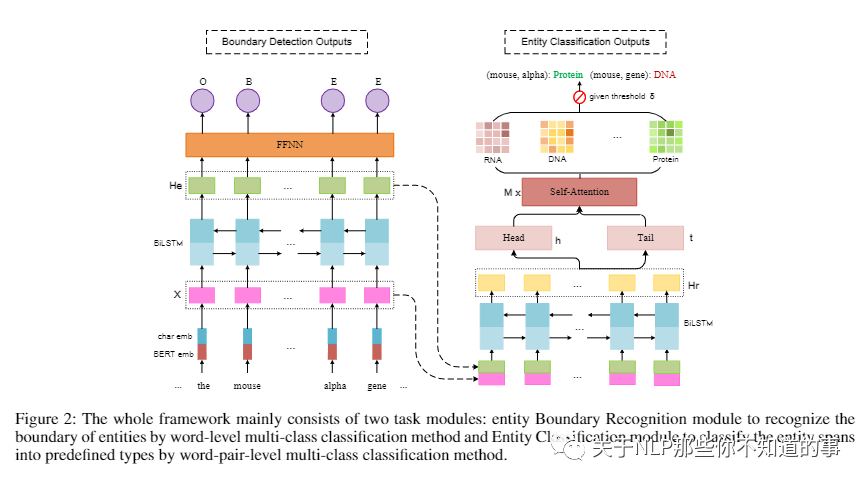
【A Supervised Multi-Head Self-Attention Network for Nested Named Entity Recognition ()】
作者:Yongxiu Xu,1Heyan Huang,2*Chong Feng,2Yue Hu1
介绍:近年来,研究人员对识别具有嵌套结构的重叠实体表现出越来越大的兴趣。
动机:大多数现有模型忽略了不同实体类型下单词之间的语义相关性。考虑到句子中的单词在不同的实体类型下扮演不同的角色,我们认为应该考虑句子中每个实体类型的成对单词的相关强度。
论文方法:将命名实体识别视为词对的多类分类,
设计了一个简单的神经模型来处理这个问题。我们的模型应用有监督的多头自注意力机制,其中每个头对应一种实体类型,以构建每种类型的词级相关性。我们的模型可以根据相应类型下其头尾的相关强度灵活地预测跨度类型。
通过多任务学习框架融合了实体边界检测和实体分类,可以捕获这两个任务之间的依赖关系。
实验结果:为了验证我们模型的性能,我们对嵌套和平面数据集进行了大量实验。实验结果表明,我们的模型在没有任何额外的 NLP 工具或人工注释的情况下,在多项任务上的表现优于之前的最先进方法
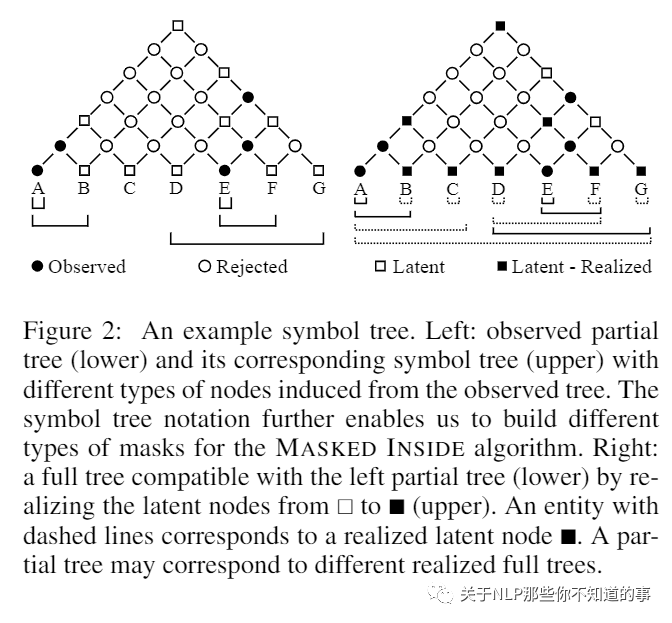
【Nested Named Entity Recognition with Partially-Observed TreeCRFs (Partially-Observed-TreeCRFs)】 【github】
作者:Yao Fu, Chuanqi Tan, Mosha Chen, Songfang Huang, Fei Huang
介绍:命名实体识别 (NER) 是自然语言处理中一项经过充分研究的任务。
动机:广泛使用的序列标记框架很难检测具有嵌套结构的实体。
论文方法:
将嵌套 NER 视为使用部分观察到的树进行选区解析,并使用部分观察到的 TreeCRF 对其进行建模。具体来说,将所有标记的实体跨度视为选区树中的观察节点,将其他跨度视为潜在节点。
使用 TreeCRF,我们实现了一种统一的方式来联合建模观察到的和潜在的节点。
为了计算部分边缘化的部分树的概率,提出了一种内部算法的变体,\textsc{Masked Inside} 算法,它支持不同节点的不同推理操作(对观察的评估、对潜在的边缘化和拒绝对于与观察到的节点不兼容的节点)具有高效的并行化实现,从而显着加快了训练和推理速度。
实验结果:在 ACE2004、ACE2005 数据集上达到了最先进的 (SOTA) F1 分数,并在 GENIA 数据集上显示出与 SOTA 模型相当的性能。
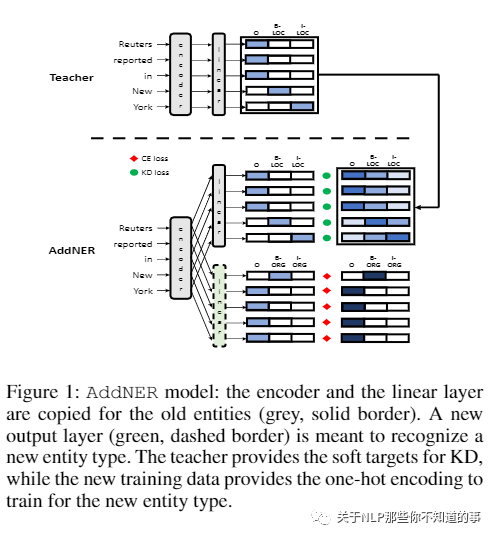
【Continual Learning for Named Entity Recognition】 [***]
作者
介绍:命名实体识别 (NER) 是各种 NLP 应用程序中的一项重要任务。
动机:在许多现实世界的场景中(例如,语音助手)经常引入新的命名实体类型,需要重新训练 NER 模型以支持这些新的实体类型。当存储限制或安全问题重新限制对该数据的访问时,为新实体类型重新 标注 原始训练数据可能成本高昂甚至不可能,并且随着类型数量的增加,为所有实体注释新数据集变得不切实际且容易出错.
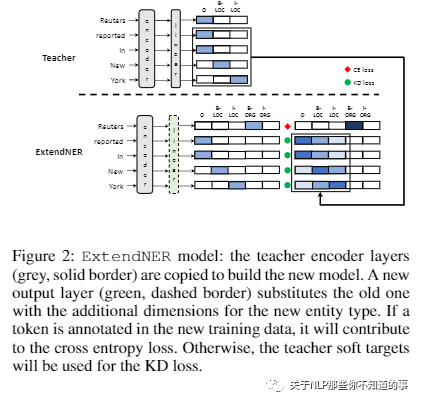
论文方法:引入了一种新颖的持续学习方法,它需要仅针对新的实体类型 标注 新的训练材料。为了保留模型先前学到的现有知识,我们利用知识蒸馏(KD)框架,其中现有的 NER 模型充当新 NER 模型(即学生)的老师,该模型通过以下方式学习新的实体类型使用新的训练材料并通过在这个新训练集上模仿教师的输出来保留旧实体的知识。
实验结果:这种方法允许学生模型“逐步”学习识别新的实体类型,而不会忘记以前学习的实体类型。我们还提供了与多个强基线的比较,以证明我们的方法在不断更新 NER 模型方面是优越的
AddNER
ExtendNER
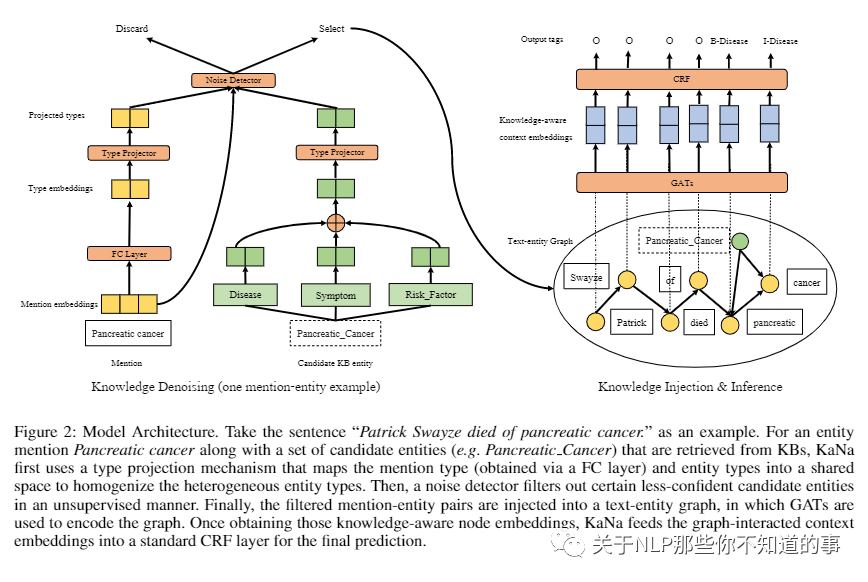
【Knowledge-Aware Named Entity Recognition with Alleviating Heterogeneity】
介绍:命名实体识别 (NER) 是许多下游 NLP 任务的基本且重要的研究课题,旨在检测非结构化文本中提到的命名实体 (NE) 并将其分类为预定义的类别。
动机:当涉及特定领域或时间演变的实体(例如医学术语或餐厅名称)时,仅从标记数据中学习是远远不够的。幸运的是,开源知识库 (KB)(例如 Wikidata 和 Freebase)包含在不同域中使用预定义类型手动标记的 NE,这可能有利于识别实体边界和更准确地识别实体类型。特定领域的 NER 任务通常独立于当前 KB 的任务,因此不可避免地会表现出异质性问题,这使得原始 NER 和 KB 类型(例如PersoninNER 可能匹配Presidentin KB)之间的匹配不太可能,或者在不考虑特定领域知识的情况下引入了意外噪声(例如,在餐厅相关任务中,Bandin NER 应该映射到OutofEntityTypes)。
论文方法:为了更好地合并和去噪知识库中丰富的知识,我们提出了一种新的知识库感知 NER 框架(KaNa),它利用类型异构知识来改进 NER。
对于一个实体mention 以及一组从KBs 链接的候选实体,KaNa 首先使用一种类型投影机制,将mention 类型和实体类型映射到共享空间中,以同质化异构实体类型;
然后,基于投影类型,噪声检测器以无监督的方式过滤掉某些不太自信的候选实体。
最后,过滤后的提及实体对被注入到一个 NER 模型中作为一个图表来预测答案。
实验结果:证明了 KaNa 在来自不同领域的五个公共基准数据集上的最先进性能,平均超过强基线 1.33 个 F1 点
【Denoising Distantly Supervised Named Entity Recognition via a Hypergeometric Probabilistic Model】
介绍:去噪是基于远程监督的命名实体识别的必要步骤。
动机:以前的去噪方法大多基于实例级置信度统计,忽略了不同数据集和实体类型上潜在噪声分布的多样性。这使得它们难以适应高噪声率设置。
论文方法:提出了超几何学习 (HGL),这是一种用于远程监督 NER 的去噪算法,它同时考虑了噪声分布和实例级置信度。具体来说,在神经网络训练期间,我们自然地按照由噪声率参数化的超几何分布对每批中的噪声样本进行建模。然后,根据从先前训练步骤得出的标签置信度以及该采样批次中的噪声分布,将批次中的每个实例视为正确或有噪声的实例。
实验表明,HGL 可以有效地对从远程监督中检索到的弱标记数据进行去噪,从而对训练模型进行显着改进。
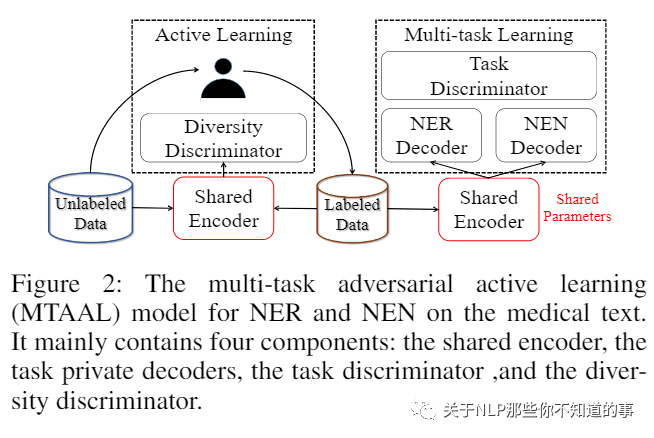
【MTAAL: Multi-Task Adversarial Active Learning for Medical Named Entity Recognition and Normalization(MTAAL)】
介绍:自动化医学命名实体识别和规范化是构建知识图谱和构建 QA 系统的基础。
动机:当涉及到医学文本时,标注 需要专业知识和专业精神的基础。现有方法利用主动学习来降低语料库注释的成本,以及多任务学习策略来对不同任务之间的相关性进行建模。然而,现有模型没有考虑针对不同任务和查询样本多样性的任务特定特征。
论文方法:提出了一种多任务对抗性主动学习模型,用于医学命名实体识别和归一化。在我们的模型中,对抗性学习保持了多任务学习模块和主动学习模块的有效性。任务鉴别器消除了不规则任务特定特征的影响。多样性判别器利用样本间的异质性来满足多样性约束。两个医学基准的实证结果证明了我们的模型对现有方法的有效性。