
【关于 AAAI 2021 之 关系抽取论文串烧】那些你不知道的事
作者:杨夕
论文学习项目地址:https://github.com/km1994/nlp_paper_study
《NLP 百面百搭》地址:https://github.com/km1994/NLP-Interview-Notes
个人介绍:大佬们好,我叫杨夕,该项目主要是本人在研读顶会论文和复现经典论文过程中,所见、所思、所想、所闻,可能存在一些理解错误,希望大佬们多多指正。
NLP && 推荐学习群【人数满了,加微信 blqkm601 】
1.3 关系抽取
【FL-MSRE: A Few-Shot Learning Based Approach to Multimodal Social Relation Extraction(L-MSRE)】
介绍:社会关系抽取(简称SRE)旨在推断日常生活中两个人之间的社会关系,在现实中已被证明具有重要价值。
动机:现有的 SRE 方法只考虑从文本或图像等单模态信息中提取社会关系,而忽略了多模态信息中的高耦合。而且,以往的研究忽视了社会关系分布的严重失衡。
论文方法:提出了 FL-MSRE,这是一种基于少量学习的方法,用于从文本和面部图像中提取社会关系。据我们所知,这是第一次尝试同时利用文本和图像进行 SRE。考虑到多模态社会关系数据集的缺乏,本文提出了三个多模态数据集,标注了四个经典杰作和相应的电视剧。受 BERT 成功的启发,我们提出了一个基于强 BERT 的基线来仅从文本中提取社会关系。经验表明,FL-MSRE 显着优于基线。这表明使用人脸图像有利于基于文本的 SRE。进一步的实验还表明,使用来自不同场景的两张人脸图像可以获得与来自同一场景的相似性能。这意味着FL-MSRE适用于范围广泛的SRE应用,其中关于不同人的面部图像只能从不同场景中收集。
【Multi-View Inference for Relation Extraction with Uncertain Knowledge】
介绍:知识图谱 (KG) 被广泛用于促进关系提取 (RE) 任务。
动机:虽然大多数先前的 RE 方法都专注于利用确定性 KG,但不确定 KG 为每个关系实例分配置信度分数,可以提供关系事实的先验概率分布作为 RE 模型的宝贵外部知识。
论文方法:提出利用不确定知识来改进关系抽取。具体来说,我们将 ProBase,一个不确定的 KG,指示目标实体在多大程度上属于一个概念,到我们的 RE 架构中。然后,我们设计了一个新颖的多视图推理框架,以系统地整合三个视图中的本地上下文和全局知识:提及视图、实体视图和概念视图。
实验结果表明,我们的模型在句子级和文档级关系提取方面都取得了有竞争力的性能,这验证了引入不确定知识和我们设计的多视图推理框架的有效性。
【GDPNet: Refining Latent Multi-View Graph for Relation Extraction(GDPNet)】
介绍:关系提取(RE)是预测一段文本中提到的两个实体的关系类型,例如句子或对话。
动机:当给定的文本很长时,识别用于关系预测的指示词是很有挑战性的。RE 任务的最新进展来自基于 BERT 的序列建模和基于图的序列中标记之间关系的建模。
论文方法:建议构建一个潜在的多视图图来捕获令牌之间的各种可能关系。然后我们细化这个图来选择重要的词进行关系预测。最后,将细化图的表示和基于 BERT 的序列表示连接起来以进行关系提取。具体来说,在我们提出的 GDPNet(高斯动态时间扭曲池化网络)中,我们利用高斯图生成器 (GGG) 来生成多视图图的边。然后通过动态时间扭曲池 (DTWPool) 对图形进行细化。
实验结果:在 DialogRE 和 TACRED 上,我们表明 GDPNet 在对话级 RE 上实现了最佳性能,并且在句子级 RE 上与最先进的性能相当。
【Progressive Multi-Task Learning with Controlled information Flow for Joint Entity and Relation Extraction】
介绍:多任务学习在同时学习多个相关任务方面表现出良好的性能,并且已经提出了模型架构的变体,特别是对于监督分类问题。多任务学习的一个目标是提取一个良好的表征,该表征能够充分捕获每个学习任务的输出的相关输入部分。
动机:为了实现这一目标,本文基于观察到一些相关任务(实体识别和关系提取任务)的输出之间存在相关性
论文方法:设计了一个多任务学习架构,它们反映了需要从输入中提取的相关特征。由于未观察到输出,我们提出的模型利用神经模型较低层的任务预测,在这项工作中也称为早期预测。但是我们控制早期预测的注入,以确保我们提取出良好的特定于任务的表示进行分类。我们将此模型称为具有显式交互(PMEI)的渐进式多任务学习模型。
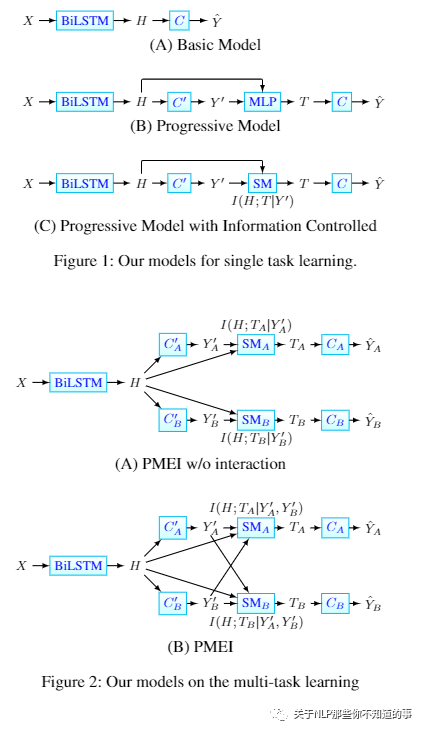
实验结果:在多个基准数据集上的大量实验在联合实体和关系提取任务上产生了最先进的结果
【Curriculum-Meta Learning for Order-Robust Continual Relation Extraction】 【github】
介绍:连续关系提取是一项重要的任务,它侧重于从非结构化文本中逐步提取新的事实。
动机:鉴于关系的先后到达顺序,这项任务容易面临两个严重的挑战,即灾难性遗忘和顺序敏感性。
论文方法:提出了一种新的课程元学习方法来解决连续关系提取中的上述两个挑战。
将元学习和课程学习相结合,以快速使模型参数适应新任务,并减少先前任务对当前任务的干扰。
通过关系的域和范围类型的分布设计了一种新颖的关系表示学习方法。这种表示被用来量化课程构建任务的难度。
提出了新的基于难度的指标来定量测量给定模型的顺序敏感程度,
提出了评估模型稳健性的新方法。
实验结果:在三个基准数据集上的综合实验表明,我们提出的方法优于最先进的技术。
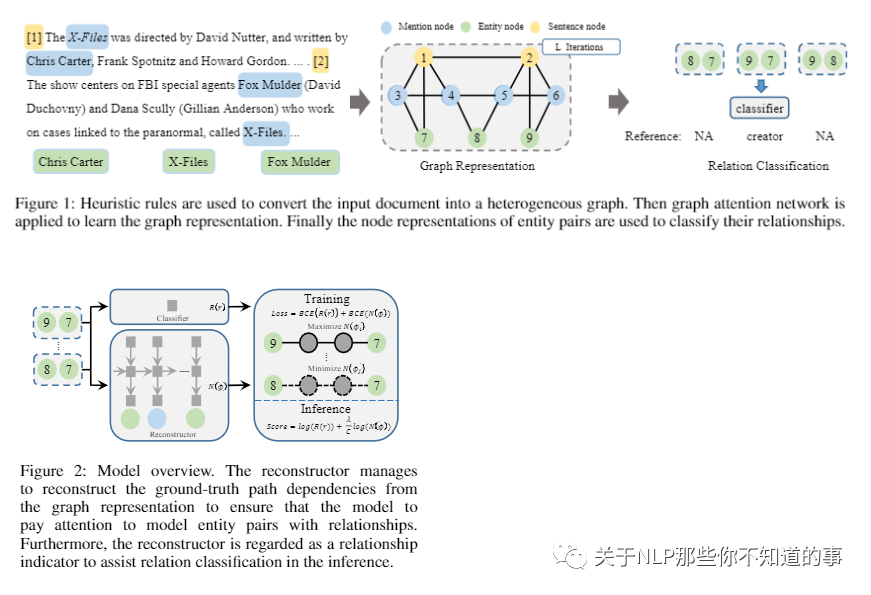
【Document-Level Relation Extraction with Reconstruction】
介绍:在文档级关系提取(DocRE)中,图结构通常用于对输入文档中的关系信息进行编码,以对每个实体对之间的关系类别进行分类,并且在过去几年中极大地推进了 DocRE 任务。
动机:无论这些实体对之间是否存在关系,学习到的图表示都可以通用地对所有实体对之间的关系信息进行建模。因此,那些没有关系的实体对分散了编码器-分类器 DocRE 对有关系的注意力,这可能会进一步阻碍 DocRE 的改进。
论文方法:为 DocRE 提出了一种新颖的编码器-分类器-重构器模型。重建器设法从图表示中重建真实路径依赖关系,以确保所提出的 DocRE 模型更加关注在训练中对具有关系的实体对进行编码。此外,在推理中将重构器作为关系指标来辅助关系分类,可以进一步提高DocRE模型的性能。
实验结果:在大规模 DocRE 数据集上的实验结果表明,所提出的模型可以显着提高基于强异构图的基线关系提取的准确性。
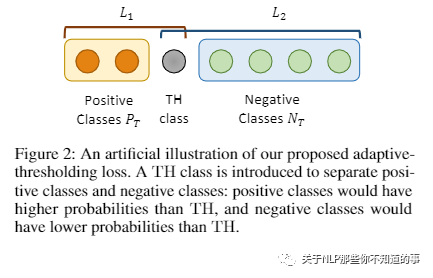
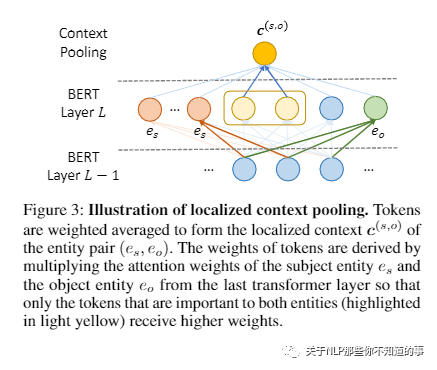
【Document-Level Relation Extraction with Adaptive Thresholding and Localized Context Pooling(ATLOP )】 【github】
动机:与其句子级对应物相比,文档级关系提取 (RE) 提出了新的挑战。一个文档通常包含多个实体对,一个实体对在与多个可能关系相关联的文档中多次出现。

论文方法:提出了两种新技术,自适应阈值化和局部上下文池化,以解决多标签和多实体问题。
自适应阈值用可学习的实体相关阈值代替了先前工作中用于多标签分类的全局阈值。
局部上下文池化直接将注意力从预先训练的语言模型转移到定位对确定关系有用的相关上下文。
实验结果:在三个文档级 RE 基准数据集上进行了实验:DocRED,一个最近发布的大规模 RE 数据集,以及生物医学领域的两个数据集 CDR 和 GDA。我们的 ATLOP(自适应阈值和本地化上下文池)模型达到了 63.4 的 F1 分数,并且在 CDR 和 GDA 上也显着优于现有模型。
【Entity Structure Within and Throughout: Modeling Mention Dependencies for Document Level Relation Extraction(SSAN)】 【PaddlePaddle/Research】 【BenfengXu/SSAN】
介绍:实体作为关系抽取任务的基本要素,具有一定的结构。

论文方法:在这项工作中,我们将这样的结构表述为提及对之间的独特依赖关系。然后我们提出了 SSAN,它在标准的自注意力机制和整个编码阶段中结合了这些结构依赖。具体来说,我们在每个自注意力构建块内设计了两个替代转换模块,以产生注意力偏差,从而自适应地调整其注意力流。
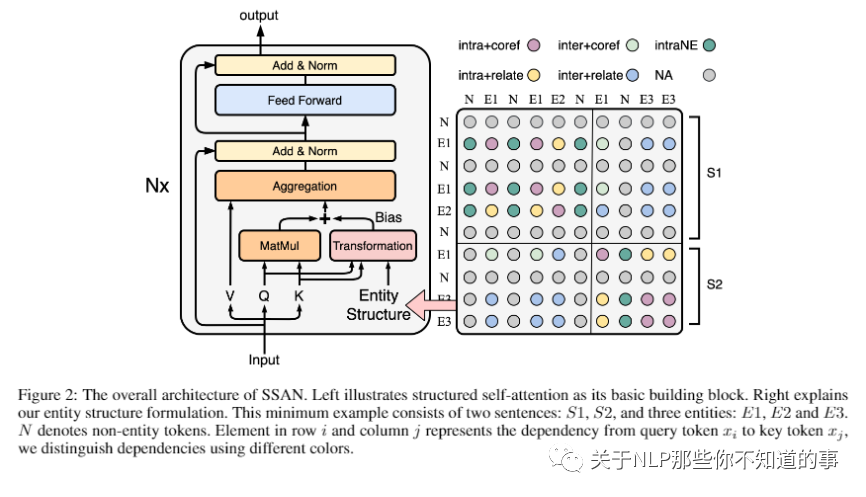
实验结果:实验证明了所提出的实体结构的有用性和 SSAN 的有效性。它显着优于竞争基线,在三个流行的文档级关系提取数据集上取得了最新的最新结果。我们进一步提供消融和可视化来展示实体结构如何指导模型以更好地提取关系。
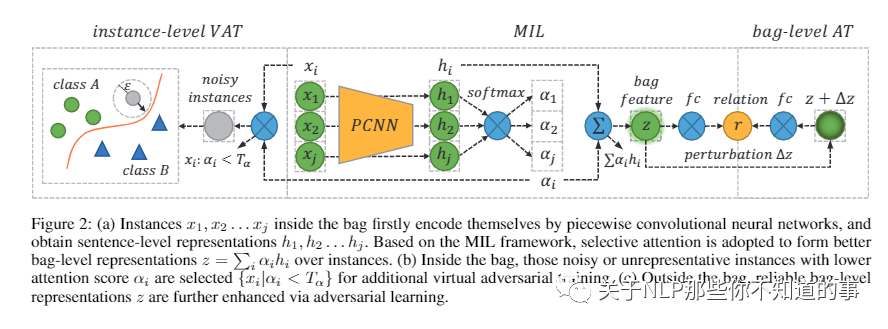
【Empower Distantly Supervised Relation Extraction with Collaborative Adversarial Training( MULTICAST)】
介绍:随着远程监督 (DS) 关系提取 (RE) 的最新进展,利用多实例学习 (MIL) 从嘈杂的 DS 中提取高质量监督受到了极大的关注。
动机:在这里,我们超越标签噪声,确定 DS-MIL 的关键瓶颈在于其数据利用率低:由于 MIL 对高质量监督进行了细化,MIL 放弃了大量训练实例,导致数据利用率低并阻碍模型训练来自有丰富的监督。
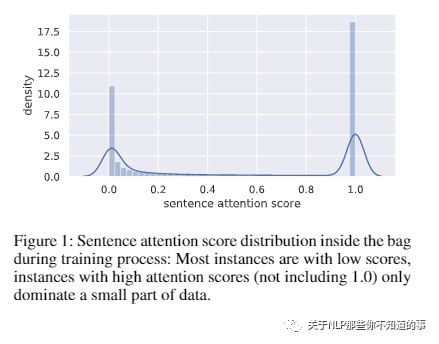
论文方法:提出了协同对抗训练来提高数据利用率,在不同层次上协调虚拟对抗训练(VAT)和对抗训练(AT)。具体来说,由于 VAT 是无标签的,我们采用 instance-level VAT 来回收 MIL 放弃的实例。此外,我们在包级部署AT,以释放MIL 获得的高质量监督的全部潜力。
实验结果:我们提出的方法为先前的技术水平带来了持续的改进(~5 绝对 AUC 分数),这验证了数据利用问题的重要性和我们方法的有效性。
【Clinical Temporal Relation Extraction with Probabilistic Soft Logic Regularization and Global Inference(CTRL-PG)】 【github】
介绍:医学界一直需要精确提取临床事件之间的时间关系。特别是,时间信息可以促进各种下游应用,例如病例报告检索和医学问答。
动机:现有方法要么需要昂贵的特征工程,要么无法对事件之间的全局关系依赖性进行建模。
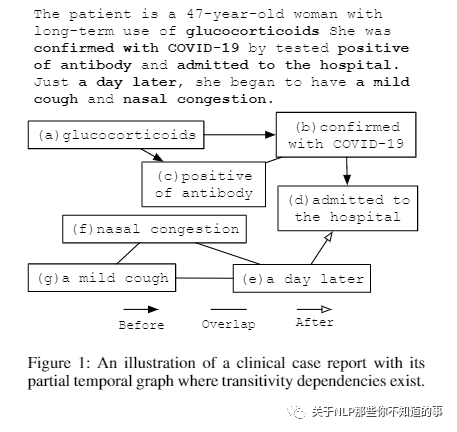
来自典型的 CCR 文件的图表,具有三种常见的时间关系类型,“之前”、“之后”和“重叠”。Glucocortocoids 被描述为该患者的用药史,发生在 COVID-19 确诊之前并且抗体阳性。nasal congestion 与 a mild cough 之间存在“重叠”时间关系。我们将上述临床概念视为事件,而将一天后视为时间表达。事件与事件(E-E)、事件与时间表达(E-T)或时间表达与时间表达(T-T)之间可能存在时间关系。
论文方法:提出了具有概率软逻辑正则化和全局推理(CTRL-PG)的临床时间关系提取,这是一种在文档级别解决问题的新方法。
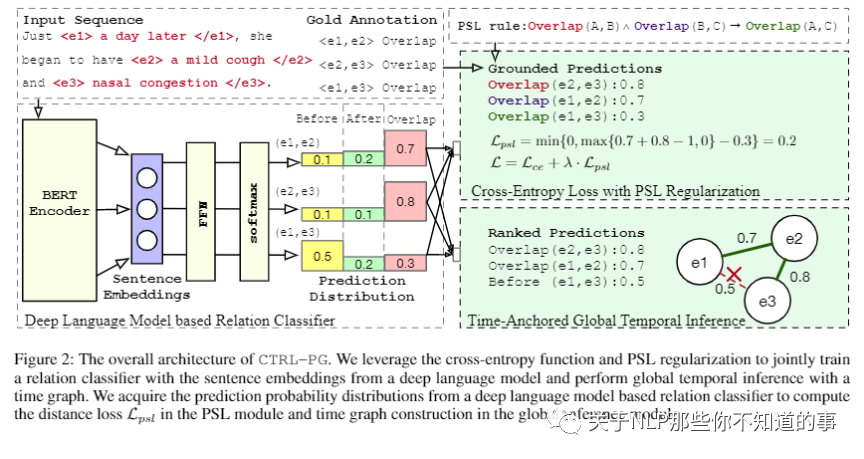
实验结果:在两个基准数据集 I2B2-2012 和 TB-Dense 上的大量实验表明,CTRL-PG 显着优于用于时间关系提取的基线方法
【A Unified Multi-Task Learning Framework for Joint Extraction of Entities and Relations】
介绍:实体和关系的联合提取侧重于使用统一模型同时检测实体对及其关系。
动机:基于提取顺序,以前的工作主要通过关系最后、关系第一和关系中间的方式来解决这个任务。然而,这些方法仍然存在模板依赖、非实体检测和非预定义关系预测问题。
论文方法:提出了一个统一的多任务学习框架,将任务划分为三个相互作用的子任务。
首先介绍了用于主题提取的类型注意方法,以明确提供先验类型信息。
然后,提出了基于全局和局部语义组合的主题感知关系预测来选择有用的关系。
第三,我们提出了一种基于问题生成的 QA 方法,用于对象提取以自动获取不同的查询。值得注意的是,我们的方法在不依赖于 NER 模型的情况下检测主题或对象,因此它能够处理非实体场景。
最后通过参数共享将三个子任务集成为一个统一的模型。
实验结果:实验表明所提出的框架在两个基准数据集上的性能优于所有基线方法,并进一步在非预定义关系上取得了优异的性能。