
20亿参数,大型视觉Transformer来了,刷新ImageNet Top1,All you need is money!
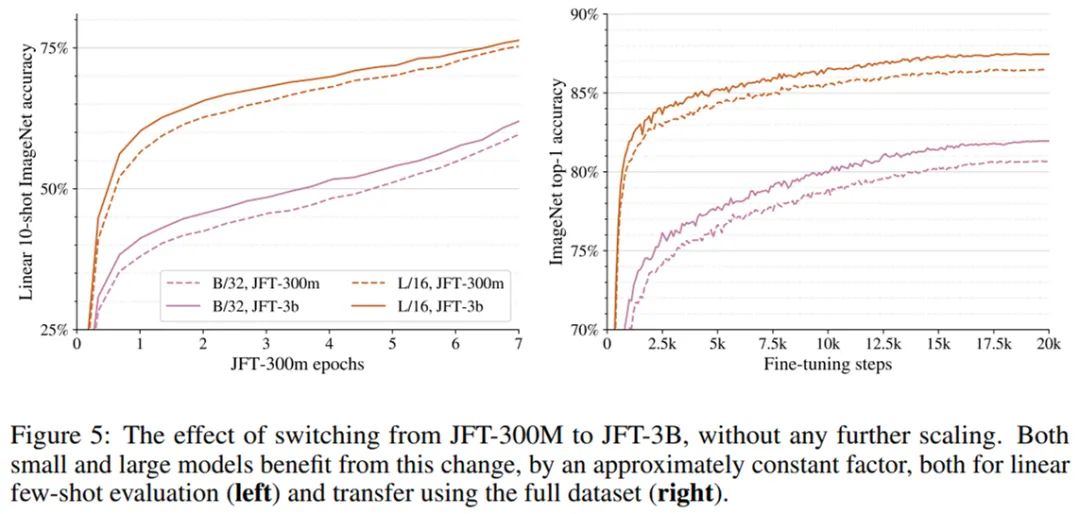
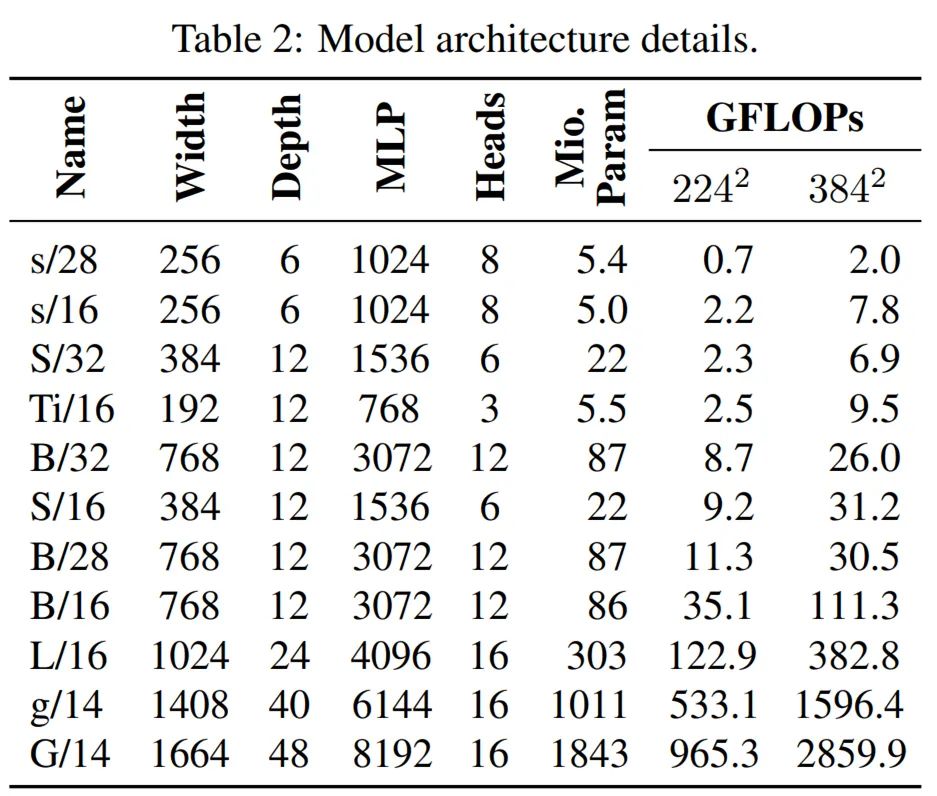
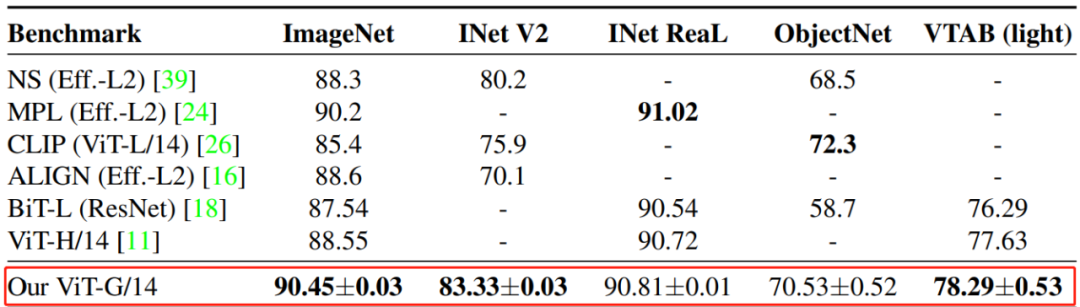
2020 年 10 月,谷歌大脑团队提出将标准 Transformer 应用于图像,提出了视觉 Transformer(ViT)模型,并在多个图像识别基准上实现了接近甚至优于当时 SOTA 方法的性能。近日,原 ViT 团队的几位成员又尝试将 ViT 模型进行扩展,使用到了包含 30 亿图像的 JFT-3B 数据集,并提出了参数量高达 20 亿参数的 ViT 变体模型 ViT G/14,在 ImageNet 图像数据集上实现了新的 SOTA Top-1 准确率。






© THE END
转载请联系原公众号获得授权
投稿或寻求报道:content@jiqizhixin.com

点个在看 paper不断!
评论