
数据集 | 将睡前消息文稿整理至一个csv中
大邓和他的Python
共 3752字,需浏览 8分钟
· 2023-03-11
一直有观看马前卒工作室睡前消息的习惯, 感觉他的内容很理性, 透露着马列科学社会风。引爆全网的两个话题独山县债务问题、以岭药业连花清瘟胶囊事件。数据可以拿来练习词频统计、词云图制作、情感分析、lda话题建模。已整理为csv文件,留给需要的人。


一、原始数据
『睡前消息』截止2023年3月6日,已经更新至559期. 文稿资源来自
https://archive.bedtime.news/zh/main
原始数据集下载下来是这个样子
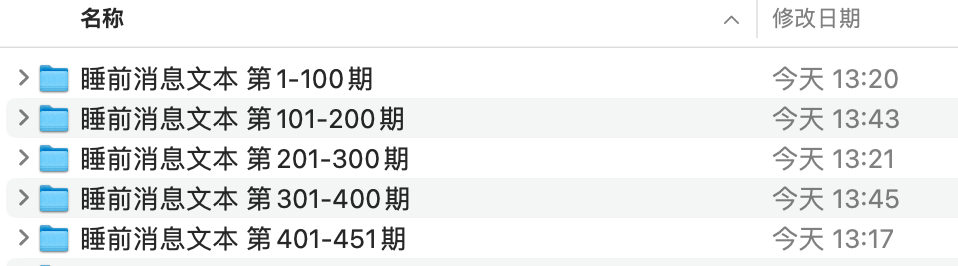

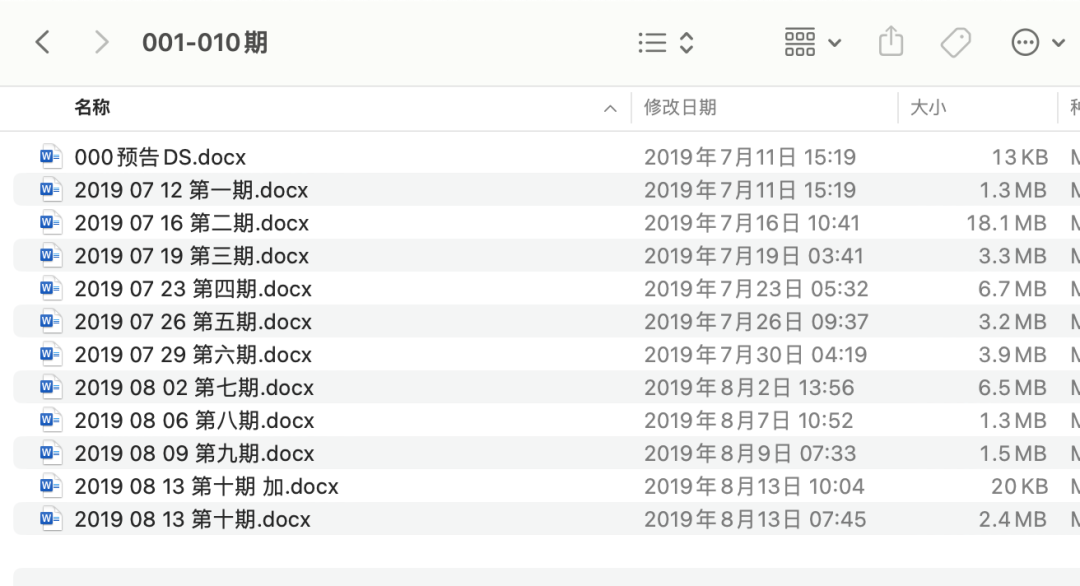
数据集文件夹的目录树结构
- 睡前消息文本 第1-100期
|- 001-010期
|- 2019 07 12 第一期.docx
|- 2019 07 16 第二期.docx
|- 2019 07 19 第三期.docx
|- 2019 07 23 第四期.docx
|- ...
|- 011-020期
|- 021-030期
|-...
- 睡前消息文本 第101-200期
- 睡前消息文本 第201-300期
- 睡前消息文本 第301-400期
- 睡前消息文本 第401-500期
- 睡前消息文本 第501-最新
- bedtime_news.csv
- code.ipynb
一、整理数据
原始数据docx文件存储,数据集是2层文件夹结构。可以使用glob库提供文件路径识别功能
import os
import glob
import csv
from pdfdocx import read_docx
with open('bedtime_news.csv', 'w', encoding='utf-8', newline='') as csvf:
fieldnames = ['date', 'name', 'text']
writer = csv.DictWriter(csvf, fieldnames = fieldnames)
writer.writeheader()
# 使用glob模块查找所有的docx文件路径
docx_files = glob.glob("**/*.docx", recursive=True)
docx_files = [f for f in docx_files if 'DS' not in f]
# 输出所有docx文件路径
for file_path in docx_files:
print(file_path)
file_name = re.sub('\s', '', file_path.split('/')[-1])
if file_name.startswith('22'):
file_name = '2022'+ file_name[2:]
date = re.findall('\d{8}', file_name)[0]
episode = re.sub('.docx', '', file_name.replace(date, ''))
text = read_docx(file_path)
data = {"date": str(date),
"name": file_path,
"text":text}
writer.writerow(data)
二、导入csv
import pandas as pd
df = pd.read_csv("bedtime_news.csv", converters={'date': str})
df.head()
Run

len(df)
Run
522
获取方式
链接: https://pan.baidu.com/s/1Qor_FNBnGuTsq4NpF3vzVQ 提取码: t8pq

精选文章
管理世界 | 用正则表达式、文本向量化、线性回归算法从md&a数据中计算 「企业融资约束指标」
可视化 | 词嵌入模型用于计算社科领域刻板印象等信息(含代码)
管理世界 | 用正则表达式、文本向量化、线性回归算法从md&a数据中计算 「企业融资约束指标」
可视化 | 词嵌入模型用于计算社科领域刻板印象等信息(含代码)
评论
python读取一个文件里面几百个csv数据集然后按照列名合并一个数据集
点击上方“Python爬虫与数据挖掘”,进行关注回复“书籍”即可获赠Python从入门到进阶共10本电子书今日鸡汤但使龙城飞将在,不教胡马度阴山。大家好,我是Python进阶者。一、前言前几天在Python最强王者交流群【FiNε_】问了一个Python自动化办公,问题如下:python 读取一个文
Python爬虫与数据挖掘
3
open-data-maker将大型 csv 文件转换成开放数据
open-data-maker 的目的是通过 API 便可以轻松地把很多大型 csv 文件转换成开放
open-data-maker将大型 csv 文件转换成开放数据
0
open-data-maker将大型 csv 文件转换成开放数据
open-data-maker的目的是通过API便可以轻松地把很多大型csv文件转换成开放数据,以及便于人们使用一个数据子集就可以下载小型的csv文件。安装和运行应用程序(开发者)可以查看安装指南 截
open-data-maker将大型 csv 文件转换成开放数据
0