
深度学习时代的机器视觉
点击上方“小白学视觉”,选择加"星标"或“置顶”
重磅干货,第一时间送达
本文转自:新机器视觉

由谭铁牛院士领衔的中国图象图形学学会将于6月2日-4日举办“图象图形学前沿讲习班”,第一期主题是“深度学习+视觉大数据”,主要讲述深度学习在计算机视觉中的应用,此次活动由中科院自动化所的王亮研究员担任学术主任,邀请6位国家杰出青年基金获得者、4位教育部长江学者特聘教授、3位国家优秀杰出青年基金获得者共聚一堂,讲述深度学习在计算机视觉前沿科技中的研究和应用。

在上世纪50年代,数学家图灵提出判断机器是否具有人工智能的标准:图灵测试。图灵测试是指测试者在与被测试者(一个人和一台机器)隔开的情况下,通过一些装置(如键盘)向被测试者随意提问。进行多次测试后,如果有超过30%的测试者不能确定出被测试者是人还是机器,那么这台机器就通过了测试,并被认为具有人类智能。
图灵测试一词来源于计算机科学和密码学的先驱阿兰·麦席森·图灵写于1950年的一篇论文《计算机器与智能》,其中30%是图灵对2000年时的机器思考能力的一个预测,但是从图灵测试提出来开始到本世纪初,50多年时间有无数科学家提出很多机器学习的算法,试图让计算机具有与人一样的智力水平,但直到2006年深度学习算法的成功,才带来了一丝解决的希望。
对于视觉算法来说,大致可以分为以下4个步骤:图像预处理、特征提取、特征筛选、推理预测与识别。计算机视觉可以说是机器学习在视觉领域的应用,所以计算机视觉在采用这些机器学习方法的时候,不得不自己设计前面3个部分。但对任何人来说这都是一个比较难的任务。
传统的计算机识别方法把特征提取和分类器设计分开来做,然后在应用时再合在一起,比如如果输入是一个摩托车图像的话,首先要有一个特征表达或者特征提取的过程,然后把表达出来的特征放到学习算法中进行分类的学习。
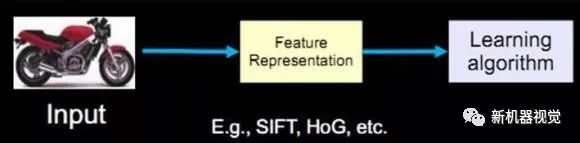
过去20年中出现了不少优秀的特征算子,比如最著名的SIFT算子,即所谓的对尺度旋转保持不变的算子。它被广泛地应用在图像比对,特别是所谓的structure from motion这些应用中,有一些成功的应用例子。另一个是HoG算子,它可以提取物体,比较鲁棒的物体边缘,在物体检测中扮演着重要的角色。
这些算子还包括Textons,Spin image,RIFT和GLOH,都是在深度学习诞生之前或者深度学习真正的流行起来之前,占领视觉算法的主流。
这些特征和一些特定的分类器组合取得了一些成功或半成功的例子,基本达到了商业化的要求但还没有完全商业化。比如指纹识别算法、基于Haar的人脸检测算法、基于HoG特征的物体检测。但这种成功例子太少了,因为手工设计特征需要大量的经验,需要你对这个领域和数据特别了解,然后设计出来特征还需要大量的调试工作。说白了就是需要一点运气。
另一个难点在于,你不只需要手工设计特征,还要在此基础上有一个比较合适的分类器算法。同时设计特征然后选择一个分类器,这两者合并达到最优的效果,几乎是不可能完成的任务。
深度学习的前世
我们不禁要问:似乎卷积神经网络设计也不是很复杂,98年就已经有一个比较像样的雏形了。自由换算法和理论证明也没有太多进展。那为什么时隔20年,卷积神经网络才能卷土重来,占领主流?
这一问题与卷积神经网络本身的技术关系不太大,与其它一些客观因素有关。
首先,深度卷积神经网络需要大量数据进行训练。网络深度太浅的话,识别能力往往不如一般的浅层模型,比如SVM或者boosting;如果做得很深,就需要大量数据进行训练,否则机器学习中的过拟合将不可避免。而2006年开始,正好是互联网开始大量产生各种各样的图片数据的时候,即视觉大数据开始爆发式地增长。
另外一个条件是运算能力。卷积神经网络对计算机的运算要求比较高,需要大量重复可并行化的计算,在当时CPU只有单核且运算能力比较低的情况下,不可能进行个很深的卷积神经网络的训练。随着GPU计算能力的增长,卷积神经网络结合大数据的训练才成为可能。
最后一点就是人和。卷积神经网络有一批一直在坚持的科学家(如Lecun)才没有被沉默,才没有被海量的浅层方法淹没。最后终于看到卷积神经网络占领主流的曙光。
人脸识别方面,工作比较超前的是汤晓鸥教授,他们提出的DeepID算法在LWF上做得比较好。最新的DeepID-3算法,在LWF达到了99.53%准确度,与肉眼识别结果相差无几。
物体检测方面,2014年的Region CNN算法、2015年的Faster R-CNN方法、FACEBOOK提出来的YOLO网络、在arXiv上出现的最新算法叫Single Shot MultiBox Detector在识别精度和速度上均与较大提升。
物体跟踪方面,DeepTrack算法是第一在线用深度学习进行跟踪的文章,当时超过了其它所有的浅层算法。此后越来越多的深度学习跟踪算法提出。
交流群
欢迎加入公众号读者群一起和同行交流,目前有SLAM、三维视觉、传感器、自动驾驶、计算摄影、检测、分割、识别、医学影像、GAN、算法竞赛等微信群(以后会逐渐细分),请扫描下面微信号加群,备注:”昵称+学校/公司+研究方向“,例如:”张三 + 上海交大 + 视觉SLAM“。请按照格式备注,否则不予通过。添加成功后会根据研究方向邀请进入相关微信群。请勿在群内发送广告,否则会请出群,谢谢理解~