
解决训练难题,1000层的Transformer来了,训练代码很快公开
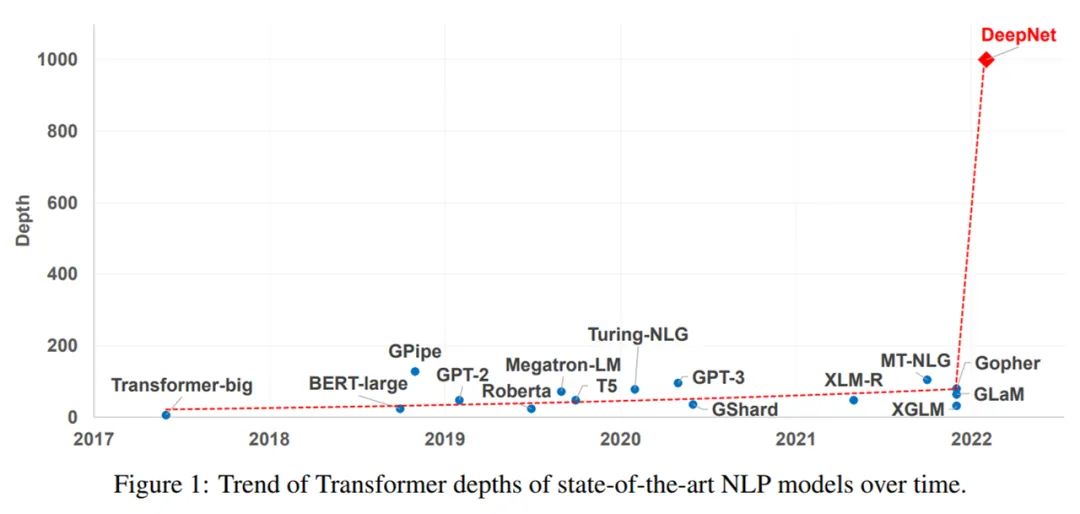
1000 层的 Transformer,深得吓人。

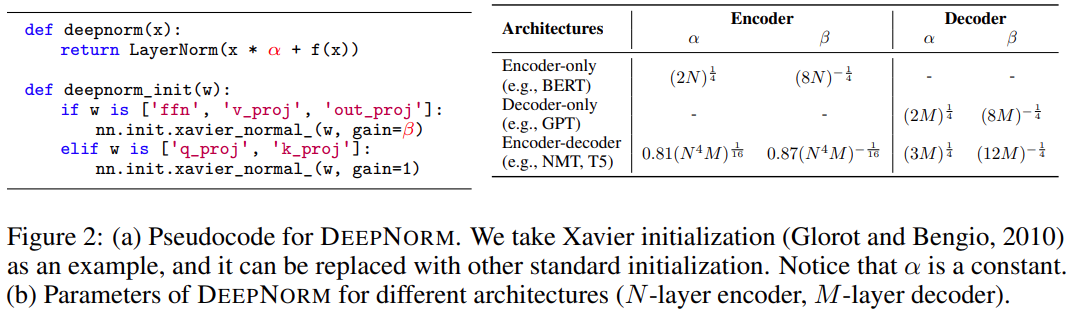
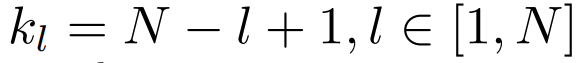 down-scale 第 l 层的权重。例如,第 l 层 FFN 的输出投影
down-scale 第 l 层的权重。例如,第 l 层 FFN 的输出投影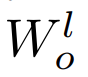 被初始化为
被初始化为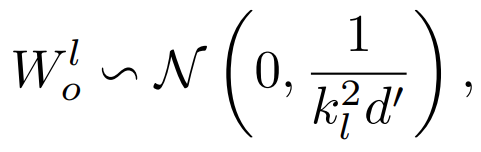 其中 d’是输入和输出维度的平均值。研究者将此模型命名为 Post-LN-init。请注意,与之前的工作(Zhang et al., 2019a)不同, Post-LN-init 是缩窄了较低层的扩展而不是较高层。研究者相信这种方法有助于将梯度扩展的影响与模型更新区分开来。此外,Post-LN-init 与 Post-LN 具有相同的架构,从而消除了架构的影响。
其中 d’是输入和输出维度的平均值。研究者将此模型命名为 Post-LN-init。请注意,与之前的工作(Zhang et al., 2019a)不同, Post-LN-init 是缩窄了较低层的扩展而不是较高层。研究者相信这种方法有助于将梯度扩展的影响与模型更新区分开来。此外,Post-LN-init 与 Post-LN 具有相同的架构,从而消除了架构的影响。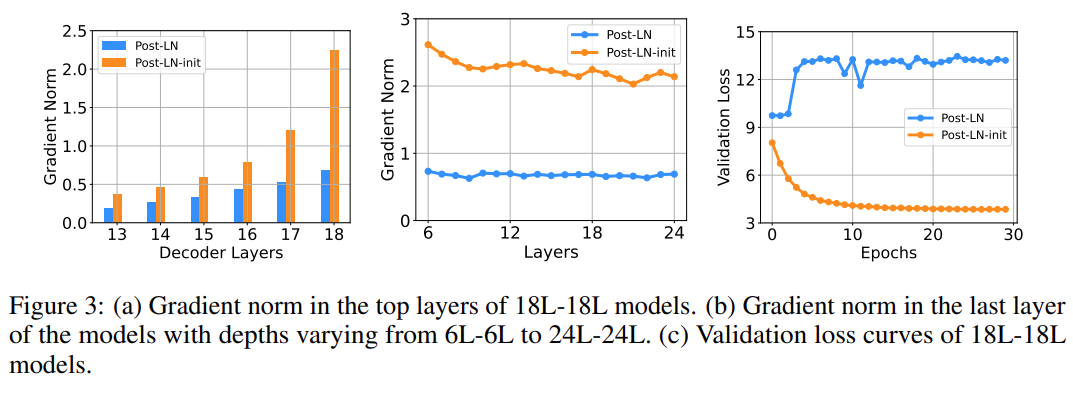
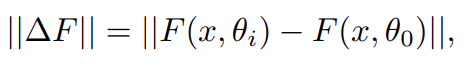
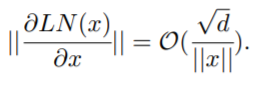
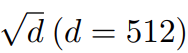 。这解释了 Post-LN 训练中出现的梯度消失问题(见图 4 (d))。
。这解释了 Post-LN 训练中出现的梯度消失问题(见图 4 (d))。
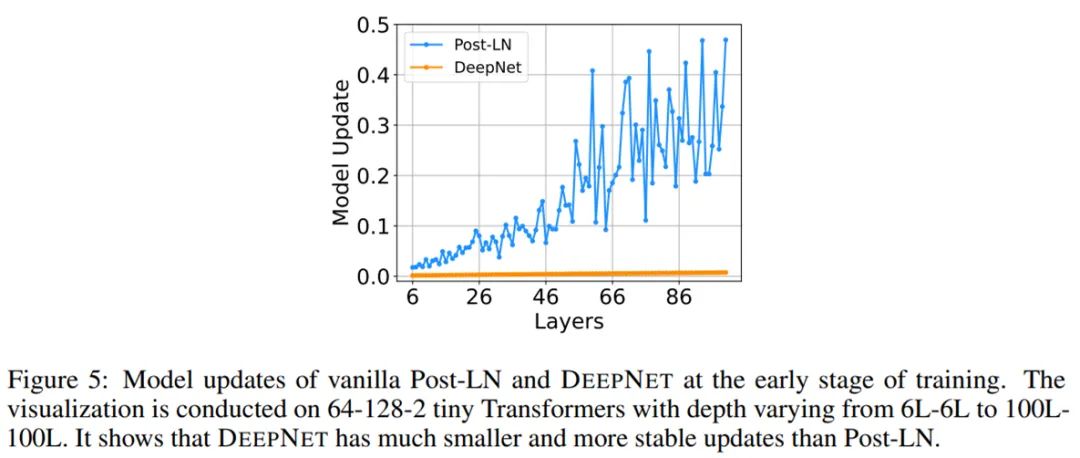
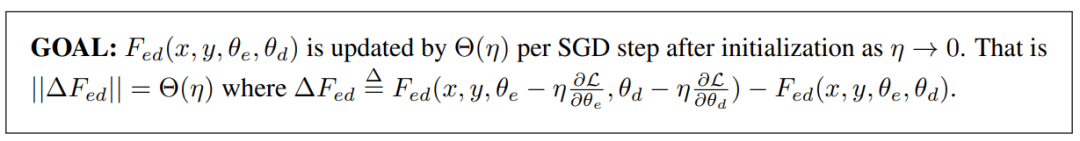



——The End——


评论