
一文读懂自注意力机制:8大步骤图解+代码
共 5164字,需浏览 11分钟
· 2022-05-24
点击上方“小白学视觉”,选择加"星标"或“置顶”
重磅干货,第一时间送达

转自 | 新智元 来源 | towardsdatascience
作者 | Raimi Karim 编辑 | 肖琴

【导读】NLP领域最近的快速进展离不开基于Transformer的架构,本文以图解+代码的形式,带领读者完全理解self-attention机制及其背后的数学原理,并扩展到Transformer。
BERT, RoBERTa, ALBERT, SpanBERT, DistilBERT, SesameBERT, SemBERT, MobileBERT, TinyBERT, CamemBERT……它们有什么共同之处呢?答案不是“它们都是BERT”🤭。
正确答案是:self-attention🤗。
我们讨论的不仅是名为“BERT”的架构,更准确地说是基于Transformer的架构。基于Transformer的架构主要用于建模语言理解任务,它避免了在神经网络中使用递归,而是完全依赖于self-attention机制来绘制输入和输出之间的全局依赖关系。但这背后的数学原理是什么呢?
这就是本文要讲的内容。这篇文章将带你通过一个self-attention模块了解其中涉及的数学运算。读完本文,你将能够从头开始写一个self-attention模块。
让我们开始吧!
完全图解——8步掌握self-attention
self-attention是什么?
如果你认为self-attention与attention有相似之处,那么答案是肯定的!它们基本上共享相同的概念和许多常见的数学运算。
一个self-attention模块接收n个输入,然后返回n个输出。这个模块中发生了什么呢?用外行人的话说,self-attention机制允许输入与输入之间彼此交互(“self”),并找出它们应该更多关注的对象(“attention”)。输出是这些交互和注意力得分的总和。
写一个self-attention模块包括以下步骤
准备输入
初始化权重
推导key, query 和 value
计算输入1的注意力得分
计算softmax
将分数与值相乘
将权重值相加,得到输出1
对输入2和输入3重复步骤4-7
注:实际上,数学运算是矢量化的,,即所有的输入都一起经历数学运算。在后面的代码部分中可以看到这一点。
步骤1:准备输入

图1.1: 准备输入
在本教程中,我们从3个输入开始,每个输入的维数为4。

步骤2:初始化权重
每个输入必须有三个表示(见下图)。这些表示称为键(key,橙色)、查询(query,红色)和值(value,紫色)。在本例中,我们假设这些表示的维数是3。因为每个输入的维数都是4,这意味着每组权重必须是4×3。
注:
稍后我们将看到value的维度也是输出的维度。

图1.2:从每个输入得出键、查询和值的表示
为了得到这些表示,每个输入(绿色)都乘以一组键的权重、一组查询的权重,以及一组值的权重。在本示例中,我们将三组权重“初始化”如下。
key的权重:

query的权重:

value的权重:

注:
在神经网络设置中,这些权重通常是很小的数字,使用适当的随机分布(例如高斯、Xavier和Kaiming分布)进行随机初始化。
步骤3:推导键、查询和值
现在,我们有了三组权重,让我们实际获取每个输入的键、查询和值表示。
输入1的键表示:

使用相同的权重集合得到输入2的键表示:

使用相同的权重集合得到输入3的键表示:

一种更快的方法是对上述操作进行矢量化:


图1.3a:从每个输入推导出键表示
同样的方法,可以获取每个输入的值表示:


图1.3b:从每个输入推导出值表示
最后,得到查询表示

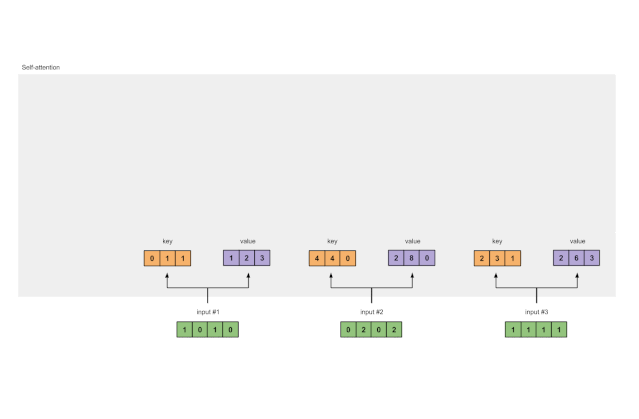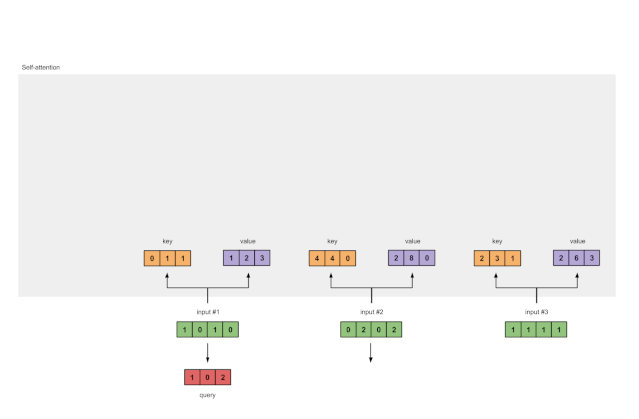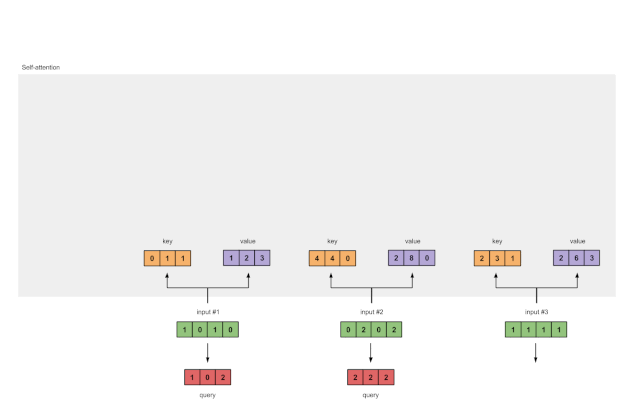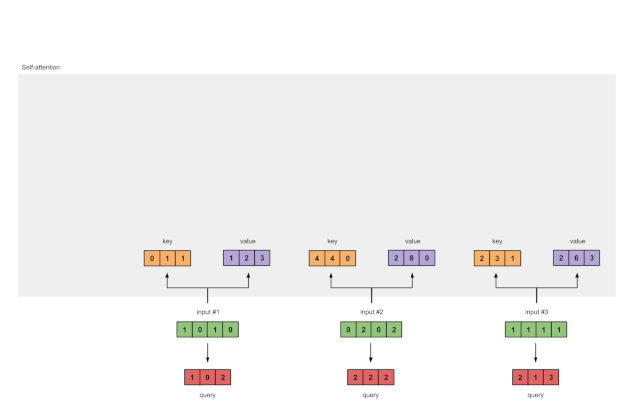
图1.3b:从每个输入推导出查询表示
注:
在实践中,偏差向量(bias vector )可以添加到矩阵乘法的乘积。
步骤4:计算输入1的attention scores
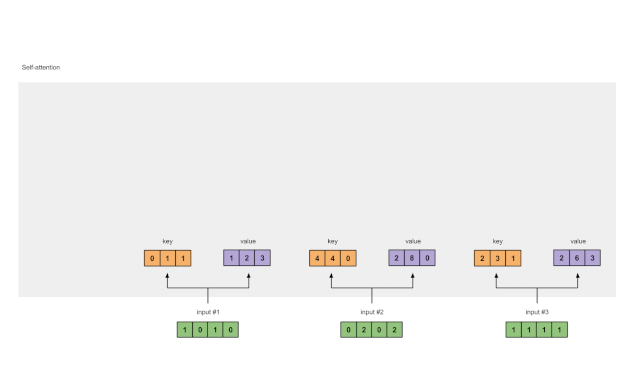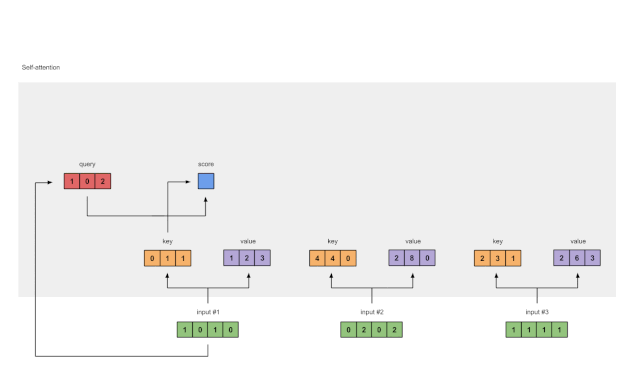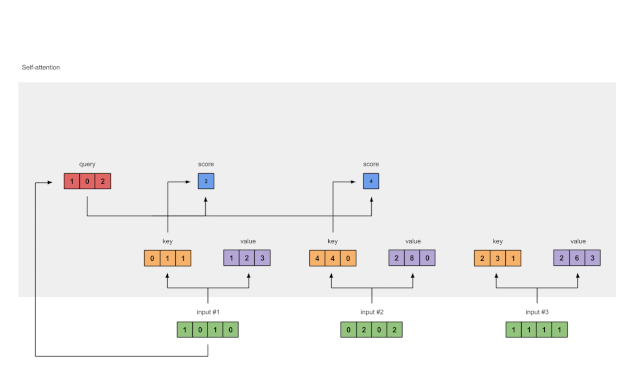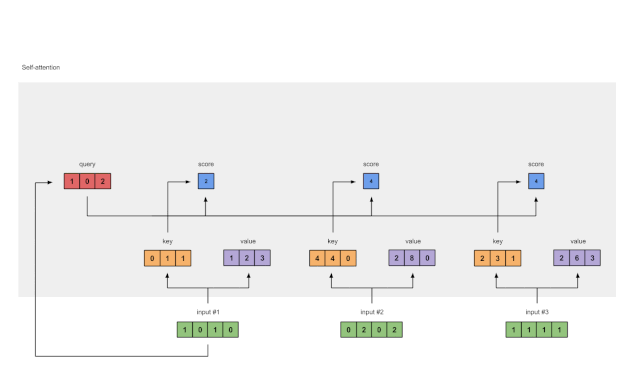
图1.4:从查询1中计算注意力得分(蓝色)
为了获得注意力得分,我们首先在输入1的查询(红色)和所有键(橙色)之间取一个点积。因为有3个键表示(因为有3个输入),我们得到3个注意力得分(蓝色)。

注:现在只使用Input 1中的查询。稍后,我们将对其他查询重复相同的步骤。
步骤5:计算softmax

图1.5:Softmax注意力评分(蓝色)
在所有注意力得分中使用softmax(蓝色)。

步骤6:将得分和值相乘

图1.6:由值(紫色)和分数(蓝色)的相乘推导出加权值表示(黄色)
每个输入的softmaxed attention 分数(蓝色)乘以相应的值(紫色)。结果得到3个对齐向量(黄色)。在本教程中,我们将它们称为加权值。

步骤7:将加权值相加得到输出1
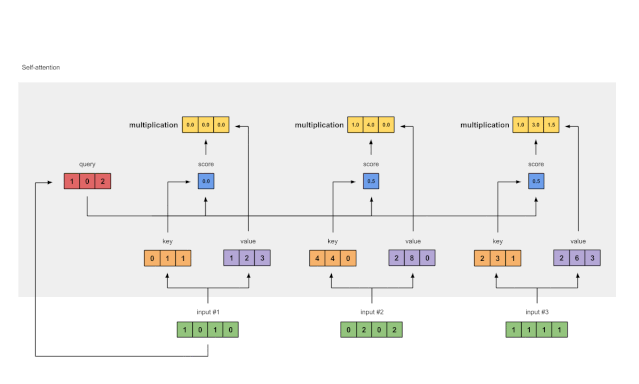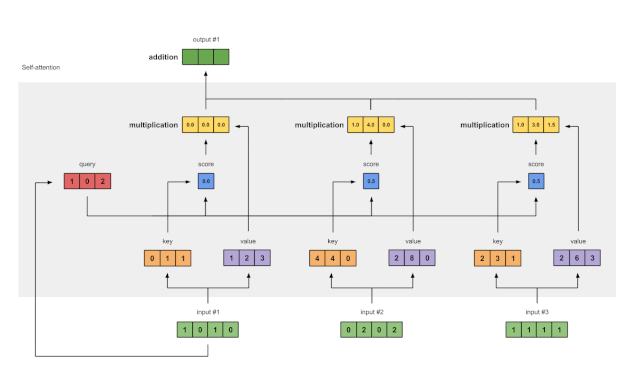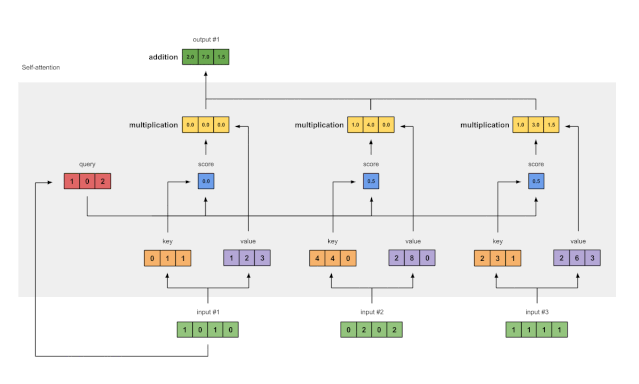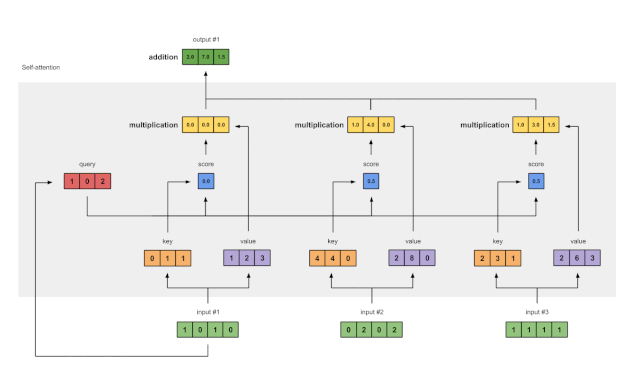
图1.7:将所有加权值(黄色)相加,得到输出1(深绿色)
将所有加权值(黄色)按元素指向求和:

结果向量[2.0,7.0,1.5](深绿色)是输出1,该输出基于输入1与所有其他键(包括它自己)进行交互的查询表示。
步骤8:重复输入2和输入3
现在,我们已经完成了输出1,我们对输出2和输出3重复步骤4到7。接下来相信你可以自己操作了👍🏼。
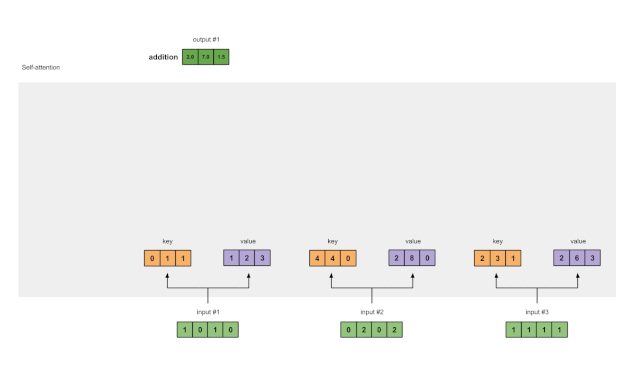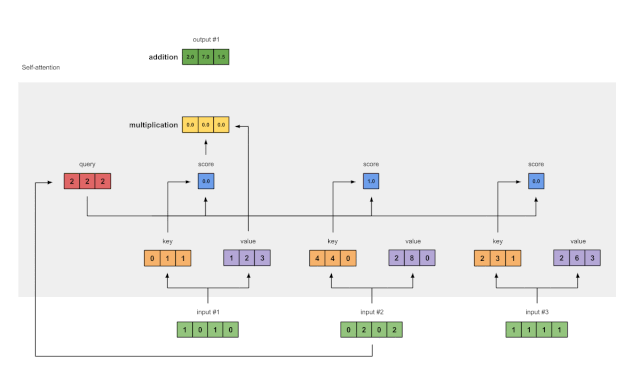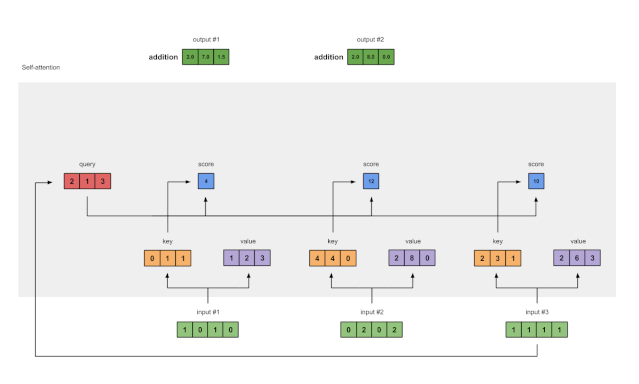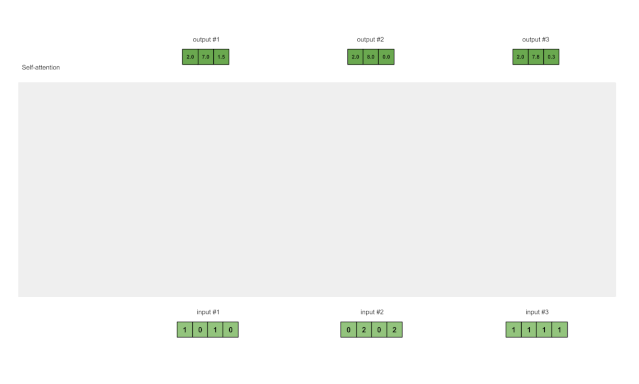
图1.8:对输入2和输入3重复前面的步骤
代码上手
这是PyTorch代码🤗,PyTorch是Python的一个流行的深度学习框架。
步骤1:准备输入
import torchx = [[1, 0, 1, 0], # Input 1[0, 2, 0, 2], # Input 2[1, 1, 1, 1] # Input 3]x = torch.tensor(x, dtype=torch.float32)
步骤2:初始化权重
w_key = [[0, 0, 1],[1, 1, 0],[0, 1, 0],[1, 1, 0]]w_query = [[1, 0, 1],[1, 0, 0],[0, 0, 1],[0, 1, 1]]w_value = [[0, 2, 0],[0, 3, 0],[1, 0, 3],[1, 1, 0]]w_key = torch.tensor(w_key, dtype=torch.float32)w_query = torch.tensor(w_query, dtype=torch.float32)w_value = torch.tensor(w_value, dtype=torch.float32)
步骤3: 推导键、查询和值
keys = x @ w_keyquerys = x @ w_queryvalues = x @ w_valueprint(keys)# tensor([[0., 1., 1.],# [4., 4., 0.],# [2., 3., 1.]])print(querys)# tensor([[1., 0., 2.],# [2., 2., 2.],# [2., 1., 3.]])print(values)# tensor([[1., 2., 3.],# [2., 8., 0.],# [2., 6., 3.]])
步骤4:计算注意力得分
attn_scores = querys @ keys.T# tensor([[ 2., 4., 4.], # attention scores from Query 1# [ 4., 16., 12.], # attention scores from Query 2# [ 4., 12., 10.]]) # attention scores from Query 3
步骤5:计算softmax
from torch.nn.functional import softmaxattn_scores_softmax = softmax(attn_scores, dim=-1)# tensor([[6.3379e-02, 4.6831e-01, 4.6831e-01],# [6.0337e-06, 9.8201e-01, 1.7986e-02],# [2.9539e-04, 8.8054e-01, 1.1917e-01]])# For readability, approximate the above as followsattn_scores_softmax = [[0.0, 0.5, 0.5],[0.0, 1.0, 0.0],[0.0, 0.9, 0.1]]attn_scores_softmax = torch.tensor(attn_scores_softmax)
步骤6:将得分和值相乘
weighted_values = values[:,None] * attn_scores_softmax.T[:,:,None]# tensor([[[0.0000, 0.0000, 0.0000],# [0.0000, 0.0000, 0.0000],# [0.0000, 0.0000, 0.0000]],## [[1.0000, 4.0000, 0.0000],# [2.0000, 8.0000, 0.0000],# [1.8000, 7.2000, 0.0000]],## [[1.0000, 3.0000, 1.5000],# [0.0000, 0.0000, 0.0000],# [0.2000, 0.6000, 0.3000]]])
步骤7:求和加权值
outputs = weighted_values.sum(dim=0)# tensor([[2.0000, 7.0000, 1.5000], # Output 1# [2.0000, 8.0000, 0.0000], # Output 2# [2.0000, 7.8000, 0.3000]]) # Output 3
扩展到Transformer
那么,接下来怎么办呢?Transformer!
的确,我们生活在一个深度学习研究和高计算资源的激动人心的时代。Transformer是Attention is All You Need里面提出的,最初用于执行神经机器翻译。研究人员在此基础上进行了重组、切割、添加和扩展,并将其应用到更多的语言任务中。
在这里,我将简要地介绍如何将self-attention扩展到Transformer架构。
在self-attention模块中:
Dimension
Bias
self-attention模块的输入:
Embedding module
Positional encoding
Truncating
Masking
增加更多的self-attention模块:
Multihead
Layer stacking
self-attention模块之间的模块:
Linear transformations
LayerNorm
这就是所有了!希望你觉得内容简单易懂。

下载1:OpenCV-Contrib扩展模块中文版教程 在「小白学视觉」公众号后台回复:扩展模块中文教程,即可下载全网第一份OpenCV扩展模块教程中文版,涵盖扩展模块安装、SFM算法、立体视觉、目标跟踪、生物视觉、超分辨率处理等二十多章内容。 下载2:Python视觉实战项目52讲 在「小白学视觉」公众号后台回复:Python视觉实战项目,即可下载包括图像分割、口罩检测、车道线检测、车辆计数、添加眼线、车牌识别、字符识别、情绪检测、文本内容提取、面部识别等31个视觉实战项目,助力快速学校计算机视觉。 下载3:OpenCV实战项目20讲 在「小白学视觉」公众号后台回复:OpenCV实战项目20讲,即可下载含有20个基于OpenCV实现20个实战项目,实现OpenCV学习进阶。 交流群
欢迎加入公众号读者群一起和同行交流,目前有SLAM、三维视觉、传感器、自动驾驶、计算摄影、检测、分割、识别、医学影像、GAN、算法竞赛等微信群(以后会逐渐细分),请扫描下面微信号加群,备注:”昵称+学校/公司+研究方向“,例如:”张三 + 上海交大 + 视觉SLAM“。请按照格式备注,否则不予通过。添加成功后会根据研究方向邀请进入相关微信群。请勿在群内发送广告,否则会请出群,谢谢理解~