
多媒体领域顶会ACM MM 2023 闭幕,获奖论文一览!

多媒体领域顶会
国际多媒体会议(The 31th ACM International Conference on Multimedia,ACM MM)于2023年10月28日至11月3日在加拿大渥太华举行,该会议是计算机图形学与多媒体领域顶级会议,被中国计算机学会列为A类会议。
ACM MM 研究内容广泛,涵盖图像、视频、语音、文本等内容的分析、检索、编码、通信、交互、隐私保护等众多主题。
在今天这个多媒体数据爆炸式产生的时代,相关技术的创新引起了企业和学术界越来越多的关注,ACM MM 2023 共收到3072篇有效投稿(相比去年激增24%),接收论文902篇。
趋动云的众多客户正在从事相关技术研究与业务创新,本文将带领大家一览ACM MM 上的获奖论文(项目)。
获奖论文(项目)一览
最佳论文奖
CATR: Combinatorial-Dependence Audio-Queried Transformer for Audio-Visual Video Segmentation
-
论文链接:https://arxiv.org/abs/2309.09709 -
开源地址:https://github.com/aspirinone/CATR.github.io -
作者单位:Zhejiang University;Finvolution Group;
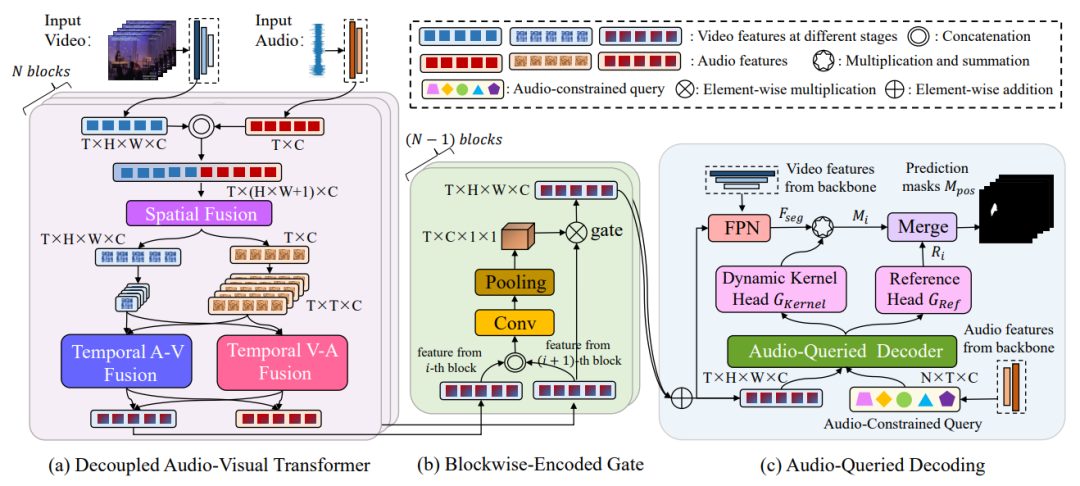
研究领域:最佳论文研究内容为Audio-visual video segmentation ,旨在生成图像内产生声音的对象的像素级掩码标注,不仅如此还要将声音与发出声音的对象关联起来,比如在视频中识别和分割唱歌的人。
方法创新:提出的方法 CATR 采用编码器-解码器结构。
-
在编码过程中,合并音频和视频特征,并捕获它们的时空依赖关系。 -
设计了一个基于块的门控方法,以此平衡多个编码器块的贡献。 -
在解码过程中,引入音频约束查询,利用音频特征来提取对象级信息,引导目标对象的分割,确保解码后的掩码与声音保持一致。
结果:作者使用两种骨干网络在三个数据集上的实验证明该方法性能达到了 SOTA 。作者称代码将开源,期待类似新技术能催生更多创新应用。
荣誉提名奖
RefineTAD: Learning Proposal-free Refinement for Temporal Action Detection
-
论文链接:https://dl.acm.org/doi/pdf/10.1145/3581783.3611872 -
作者单位:Nanjing University of Aeronautics and Astronautics;Nanjing University
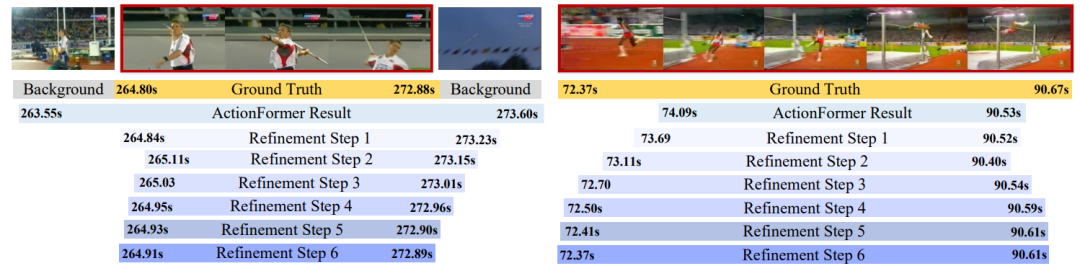
研究领域:时间动作检测(TAD),旨在定位视频中动作的起始帧和结束帧。
方法创新:提出了一种更具普适性和易用性的定位优化框架,将定位细化过程与传统动作检测方法进行解耦,在每个时间点生成多尺度的定位细化信息;同时提出一种偏移聚焦策略,以由粗到精的方式逐步增强模型的检测效果。
结果:在三个具有挑战性的数据集上进行了广泛的实验,结果表明 RefineTAD 能在保持较低计算开销的情况下显著提升动作边界定位的精度。
最佳学生论文奖
Cal-SFDA: Source-Free Domain-adaptive Semantic Segmentation with Differentiable Expected Calibration Error
-
论文链接:https://arxiv.org/abs/2308.03003 -
作者单位:The University of Queensland

研究内容:语义分割在图像视频理解任务中具有基础的作用,这篇论文关注的是域自适应语义分割(domain adaptive semantic segmentation)问题,涉及到将一个域中训练的语义分割模型应用到另一个域中,在进行域适应时不依赖于源域的数据。
创新方法:研究者在这个背景下提出了一种 "Cal-SFDA" 框架,借助源端和目标端的模型校准,有效地解决了无源域语义分割域适应的难题。
结果:在两个广泛使用的合成数据到真实数据的语义分割迁移实验中,该文提出的新方法均取得了显著的性能提升。
勇敢创新奖
Semantics2Hands: Transferring Hand Motion Semantics between Avatars
-
论文链接:https://arxiv.org/abs/2308.05920 -
开源地址:https://github.com/abcyzj/Semantics2Hands -
作者单位:Tsinghua University;Tsinghua University Beijing National Research Center for Information Science and Technology
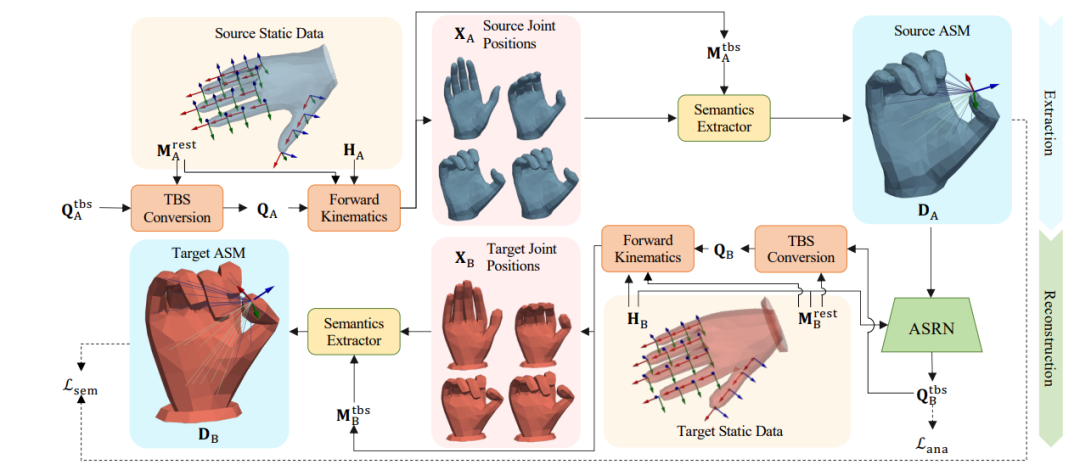
研究内容:在动画制作和人机交互中,保持虚拟人物的手部动作语义前提下进行手部动作迁移。
创新方法:研究者引入了一种新的基于解剖学的语义矩阵(Anatomy-based Semantic Matrix,ASM),用于编码手部动作的语义信息。基于此的语义重建网络实现从源ASM到目标手部关节旋转的映射函数。作者使用半监督学习策略来训练该模型。
结果:在同域和不同域的数据实验中,新方法在维护手部动作语义的同时,均可以有效地实现虚拟人物模型之间的手部动作迁移,提高了用户体验。作者已将代码开源。
开源奖
Emotion Recognition ToolKit (ERTK): Standardising Tools For Emotion Recognition Research
-
论文链接:https://dl.acm.org/doi/pdf/10.1145/3581783.3613459 -
开源地址:https://github.com/Strong-AI-Lab/emotion -
作者单位:University of Auckland
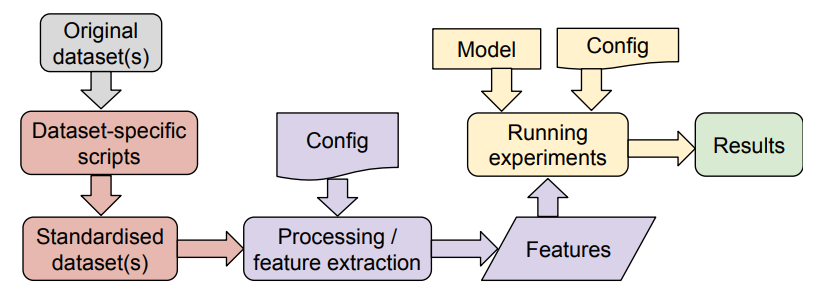
开源奖颁发给了ERTK,这是一个基于语音数据,用于情感识别的 Python 库。其包括完善的数据集处理脚本、特征提取器的标准接口以及使用配置文件定义实验的框架,具有模块化和可扩展性的特点。
开发者可以很方便使用这个库进行语音情感识别,还可以很方便地将其引入自己的开发项目或者接入其他平台。
最佳演示奖
Open-RoadAtlas: Leveraging VLMs for Road Condition Survey with Real-Time Mobile Auditing
-
论文链接:https://dl.acm.org/doi/pdf/10.1145/3581783.3612668 -
作者单位:The University of Queensland;
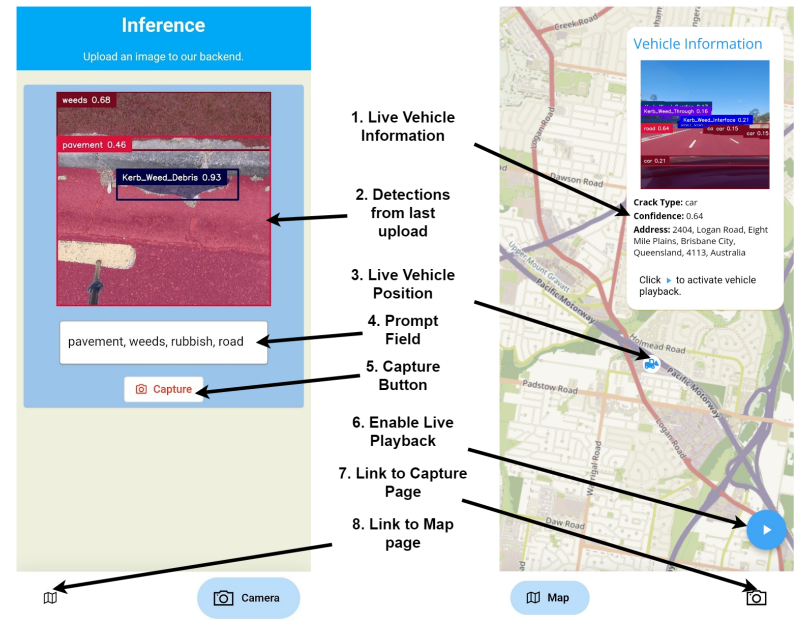
最佳演示奖颁发给了一个道路检测管理系统应用Open-RoadAtlas,比较有意思的是,它不是一套常规的仅基于视觉的道路缺陷检测系统,由于结合了最新的视觉语言模型VLM,还可以通过拒绝VLM识别的兴趣区域之外的预测来减少假阳性。