
SCNet:利用全1X1卷积实现轻量图像超分辨率
共 4267字,需浏览 9分钟
· 2024-04-12
 作者丨CSJJJ@知乎(已授权) 来源丨https://zhuanlan.zhihu.com/p/687798736 编辑丨极市平台
作者丨CSJJJ@知乎(已授权) 来源丨https://zhuanlan.zhihu.com/p/687798736 编辑丨极市平台
极市导读
1×1卷积可以用来干什么?本文设计了一种完全基于1×1卷积的极简深度神经网络,实现了轻量图像超分辨率重建。 >>加入极市CV技术交流群,走在计算机视觉的最前沿
欢迎大家关注我们近期发表在Machine Intelligence Research上的工作《Fully 1 × 1 Convolutional Network for Lightweight Image Super-Resolution》

论文链接:https://arxiv.org/abs/2307.16140
代码链接:https://github.com/aitical/scnet
1. 引言
随着深度学习技术的飞速发展,单图超分辨率(SISR)技术取得显著进展。基于卷积神经网络的SISR方法如SRCNN, 从低分辨率(LR)输入学习到高分辨率(HR)输出的映射,并取得了比传统方法更优的性能。然而,这些基于CNN的模型通常需要深层或复杂的网络结构来提升性能,这不可避免地导致了模型参数和计算成本的大量增加,使得这些模型难以部署在移动或边缘设备等资源受限环境。现有的轻量化方法设计通常关注减少模型参数数量或浮点运算(FLOPs)来实现轻量化的神经网络。然而,绝大多数基于卷积神经网络的超分辨率模型使用3×3或者更大的卷积核来提升性能。大核卷积可以提升性能,但同时也会快速增加参数数量和计算成本。相对地,1×1卷积可以极大程度的减少参数数量,但却因固定的感受野和缺失局部特征聚合而限制了其学习能力。该工作提出了全1×1卷积的轻量化图像超分辨率模型。
为了解决1×1卷积特征提取能力的局限性,我们引入了无参数的空间位移操作。将输入特征图沿着通道维度分成不同的组,并对每个组应用不同方向的空间位移操作。这样确保了输出特征图中的每个像素沿着通道维度都可以获得近邻特征聚合,从而弥补了相较于3×3卷积在表示能力上的差距。我们将这种通过空间位移操作实现局部特征聚合的1×1卷积称为移位卷积(Shift-Conv Layer, 简称SC Layer)。与常规3×3卷积相比,SC层在保持可比性能的同时,可显著减少参数数量和计算量。
2. 方法
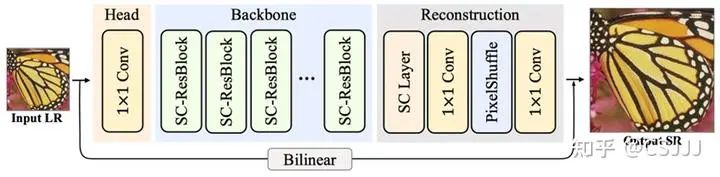 图1 SCNet的总体结构
图1 SCNet的总体结构
图像超分辨率旨在将LR图像 转换为相应的HR图像 ,从而生成SR结果 。本文提出了一个全逐点卷积实现的轻量级图像超分辨率网络SCNet。参照现有基于卷积神经网络的一般架构设计,SCNet主要包含了:浅层特征提取、深层特征提取和HR图像重建模块三部分组成,具体实现如图1所示。
2.1 整体框架
给定一个低分辨率图像,首先浅层特征提取器将其映射到指定的隐层特征空间,得到特征图。接着,浅层特征图通过深层特征提取器,提取深层特征图。最后,使用高分辨图像重建模块对深层特征进行上采样,获得最终的超分辨率结果。学习的目标函数是最小化超分辨率结果与目标高分辨图像的误差。本文提出的SCNet的整体框架和训练过程如上所述,下面介绍移位卷积和移位残差单元的具体实现细节。
2.2 移位卷积层
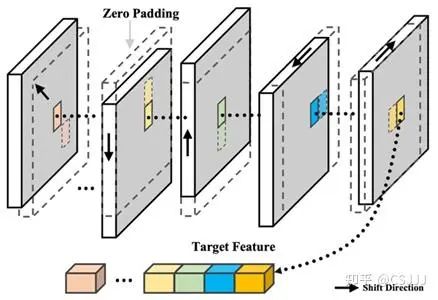 图2 空间移位操作示意
图2 空间移位操作示意
移位卷积包含逐点卷积和空间移位操作。通过空间移位操作沿着通道方向实现近邻特征对齐,从而实现局部特征聚合。具体的空间移位操作实现如图2所示。对输入特征图首先进行通道拆分,均匀划分为N组,N这里表示移位的近邻特征数量。为了与3×3卷积保持一致,我们默认采取八组。接着对不同的组分别沿着不同的方向移动指定步长。如图2所示,沿着不同方向移动后实现了对应位置处近邻特征的聚合。在这里,为了跟3×3卷积保持一致,采用8个方向和步长为1作为默认设置。值得注意的是,移位卷积相较于3×3卷积,不仅实现了局部特征聚合,通过控制移位的特征点位选取,还可以进一步扩展到长距特征关系提取。
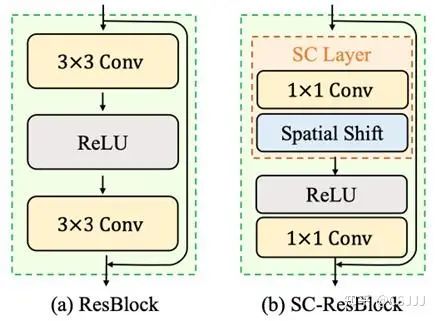 图3 (a)残差单元和(b)本文提出的移位残差单元
图3 (a)残差单元和(b)本文提出的移位残差单元
2.3 移位残差单元
基于上述的移位卷积层,我们将标准残差结构中的3×3卷积全部替换成逐点卷积,其中嵌入空间移位操作。改进后的移位残差单元包含一个移位卷积和一个逐点卷积以及激活层,具体的实现细节见图3。基于移位残差单元,我们通过堆叠不同的移位残差块实现了不同规模的SCNet。
3 实验
3.1 实验设置
数据集和指标。 我们的模型是在DIV2K和Flickr2K上训练,训练数据共包含3450张高分辨率图像。本文验证了2倍、3倍和4倍超分辨率模型。训练时将输入低分辨图像裁剪至64×64大小的块。测试时利用峰值信噪比(PSNR)和结构相似度(SSIM)指标作为评估指标,并在YCbCr空间的Y通道进行计算。
实验细节。 我们堆叠不同大小的移位残差单元实现了不同规模的轻量级SCNet,其中最小的模型SCNet-T是16个64通道的移位残差块实现,基础模型SCNet-B是64个64通道的移位残差块实现,最大的SCNet-L是32个128维的移位残差块实现。
 图4 SCNet与其他方法的主观结果对比
图4 SCNet与其他方法的主观结果对比
3.2 对比试验
主观结果。 图4显示了从_Urban100_选择的几张图像的4倍超分辨率结果。可以看到,SCNet超分辨率结果相较于其他CNN方法有着更清晰的主观效果。同时,对于一些边缘和纹理部分,SCNet也都能更好地重建出来。
客观结果。 表1~3提供了2倍3倍和4倍超分辨率任务的结果,可以看到提出的SCNet在不同模型容量下均可以取得更好的性能和模型容量的平衡。相较于广泛作为基准的IMDN和SRResNet,SCNet-L分别提升了0.26 dB和0.28 dB。此外,定量的客观结果中我们按照方法模型的大小进行了划分,以4倍超分辨率为例,可以看到在不同规模的方法比较中,SCNet都取得了非常好的效果。尤其是SCNet-B,仅有700K不到的参数就已经超过了现有CNN方法,除了在Set5上比LBNet低一些,但是LBNet包含了更多的参数。此外,具体的计算复杂度对比总结在表2中。可以看到,不同规模的SCNet在性能和计算复杂度上取得了更好的平衡。与小参数量的LAPAR-C相比,SCNet-T包含较多参数时却拥有更低的计算复杂度。与较大的SRResNet相比,SCNet-L拥有更少的参数量和计算复杂度,并且取得了更好的效果。这是因为逐点卷积计算量和参数量是3×3卷积的九分之一,我们扩展出更深的拟合能力更强的SCNet,尤其是SCNet-B,堆叠了64个移位残差单元,仅SRResNet三分之一的计算量就取得了更好的超分辨率结果。
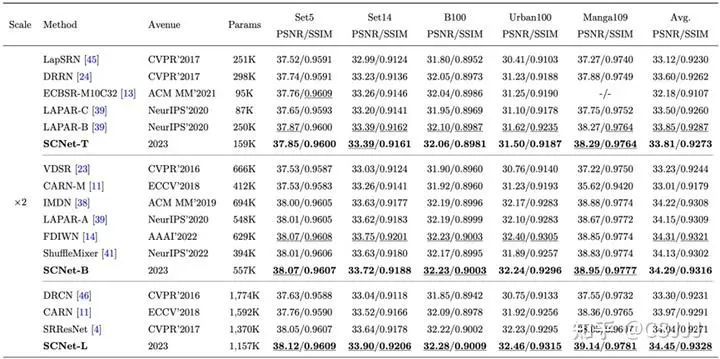 表1 2倍超分辨率客观指标结果(最好的结果被标记下划线,本文提出的SCNet的结果加粗)
表1 2倍超分辨率客观指标结果(最好的结果被标记下划线,本文提出的SCNet的结果加粗)
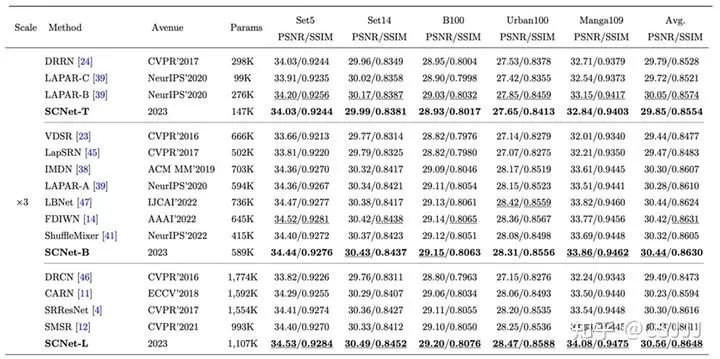 表2 3倍超分辨率客观指标结果
表2 3倍超分辨率客观指标结果
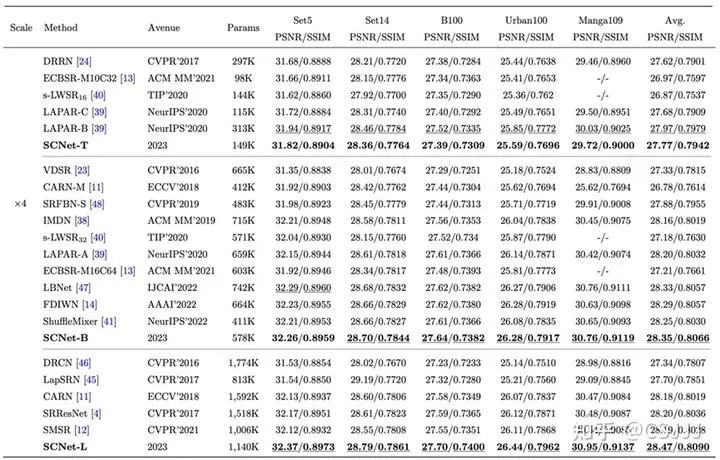 表3 4倍超分辨率客观指标结果
表3 4倍超分辨率客观指标结果
3.3 消融分析
为了验证提出的SCNet中每个成分的作用,我们进一步进行了一系列消融研究。
移位卷积分析。 首先,分析了移位卷积中不同移动策略的影响。我们设计了5种不同的移动策略如图5所示。这里我们选取了4个点位,并且拆分成了不同方向的两组,如图5(a)和图5(b)所示。默认采用的8个点位如图5(c)所示,进一步地我们扩展了移动步长,得到了图5(d)。最后,我们将图5(c)和图5(d)中的点位进行合并,得到图5(e)来验证点位数量的影响。具体的结果展示在表4中。我们可以看到,不同的移位操作设置对模型最终的性能有着重大影响。当移位操作仅选取4个点位时,SCNet指标整体下降。这是因为仅选取4个点位的特征难以有效建模近邻关系。相较于默认的8点位,空洞8点位的移位设置取得了更好的效果。我们认为这主要是由于空洞移位引入了更大的感受野。这也验证了移位操作可以通过设计不同的参数先验,甚至获取长距离关系建模,相较于一般的卷积有着更好的灵活性。最后,采用16点位的SCNet的整体效果下降了,这主要是由于16点位需要将特征划分成16组,此时每组的特征数量太少难以进行有效的关系建模。
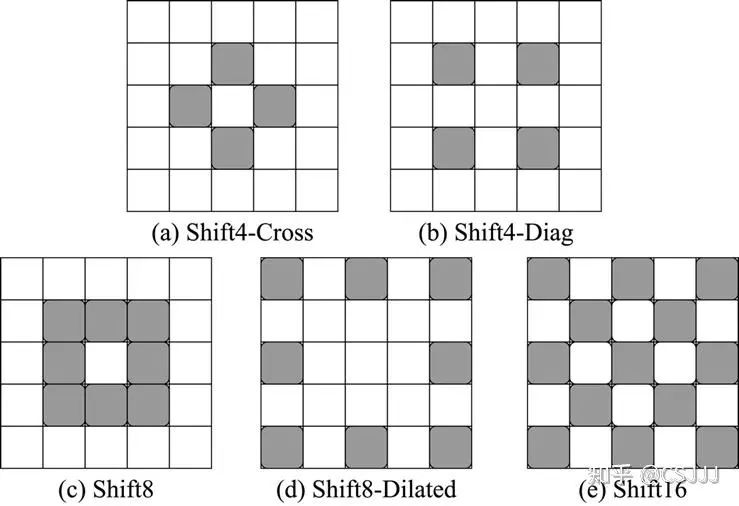 图5 多种移位操作的特征选取
图5 多种移位操作的特征选取
 表4 移位操作的消融分析结果
表4 移位操作的消融分析结果
模型容量分析。 得益于移位卷积仅需要非常少的参数量和计算量,我们可以很轻松地对SCNet进行扩展,这里主要消融SCNet的可扩展性。我们设计了不同大小的SCNet,并在4倍超分辨率任务上进行验证,客观指标展示在表5中。可以发现,仅由逐点卷积实现的SCNet有着良好的可扩展性,可以有效地扩展到不同规模的参数量。这里我们从深度和宽度(特征维度)两方面进行消融验证,总的来说,扩充深度带来的收益要比使用更大的特征维度更好。
 表5 不同模型大小的SCNet消融分析结果
表5 不同模型大小的SCNet消融分析结果
3 结论
本文提出了一个完全使用逐点卷积实现的轻量级图像超分辨率网络SCNet。与一般的3×3卷积相比,逐点卷积包含的参数更少,计算成本也更低,但缺失了局部特征融合这一关键特性。为了解决这个问题,我们通过空间移位操作扩展了逐点得到移位卷积,通过手动特征聚合使其具有了特征聚合的能力,而且空间移位操作是没有额外计算成本的。基于移位卷积,我们替换标准残差结构中的3×3卷积并提出了移位残差单元。通过堆叠不同规模的移位残差单元实现了不同模型大小的SCNet。最后在多个公开测试数据集上提出的SCNet取得了最好的结果。此外,我们也通过详细的消融分析,验证了本文提出的不同模块的有效性。
公众号后台回复“ 数据集 ”获取100+深度学习各方向资源整理
极市干货
技术专栏: 多模态大模型超详细解读专栏 | 搞懂Tranformer系列 | ICCV2023论文解读 | 极市直播 极视角动态 :欢迎高校师生申报极视角2023年教育部产学合作协同育人项目|新视野+智慧脑,「无人机+AI」成为道路智能巡检好帮手! 技术综述: 四万字详解Neural ODE:用神经网络去刻画非离散的状态变化 | transformer的细节到底是怎么样的?Transformer 连环18问!
点击阅读原文进入CV社区
收获更多技术干货