
Block-wise LoRA | 直接对Stable Diffusion中UNet的细粒度特征微调
共 9909字,需浏览 20分钟
· 2024-04-11
点击下方卡片,关注「AI视界引擎」公众号

文本到图像个性化与风格化的目标是指引预训练的扩散模型分析用户引入的新概念,并将它们融入到期望的风格中。近来,参数高效微调(PEFT)方法被广泛采用以应对这一任务,并极大地推动了该领域的发展。尽管这些方法受到欢迎,现有的高效微调方法在T2I生成中仍然难以实现有效的个性化和风格化。
为了解决这个问题,我们提出了逐块低秩适应(LoRA)来进行对不同SD块的细粒度微调,这可以生成忠于输入提示和目标身份的图像,同时也能具备所需的风格。广泛的实验验证了所提方法的有效性。
Introduction
近来,文本到图像(T2I)生成在人工智能生成内容(AIGC)领域成为一个热门话题,许多基于扩散的生成模型在这一任务上取得了显著进展。其中,稳定扩散(Stable Diffusion,简称SD)能够根据输入提示生成真实且高质量的图像,并且由于其开源特性和相对可接受的计算成本而被广泛使用。然而,SD在以低成本有效吸收新角色身份或新颖风格概念方面存在困难。
各种微调算法,如Dreambooth,文本转换,以及低秩适应(Low-Rank Adaptation,简称LoRA),已被提出以增强对特定T2I生成任务的可适应性,并在个性化和风格化方面表现出令人信服的能力,例如,创作迈克尔·杰克逊在月球上的描绘或将蒙娜丽莎转化为漫画风格。在这些方法中,LoRA因其低成本和计算效率的优势而脱颖而出,并被艺术设计师和文本到图像爱好者广泛采用,使其对用户友好且适合消费设备。
然而,现有的基于LoRA的方法仍然未能同时解决涉及个性化和风格化的T2I生成问题,这可以从生成图像中不一致的个人身份和风格概念观察到。此外,在将不同的LoRA引入图像生成过程时,目标概念和期望的风格可能无法准确反映。
为了解决这个问题,我们提出了逐块LoRA,以在T2I生成中实现有效的个性化和风格化。逐块LoRA通过在针对不同类型T2I生成任务的LoRA基调整过程中跳过一些特定的SD块,改进了原始的LoRA。大量结果表明,逐块LoRA不仅可以降低训练速度,还可以减少不同LoRA模型之间的冲突,这使得角色ID与风格的结合更加和谐。此外,我们研究了使用不同的U-net块对生成过程的影响,并通过逐块结构对生成过程有了更深入的理解。
Related Work
Parameter-efficient Fine-tuning (PEFT)
参数高效的微调(PEFT)专注于以资源高效的方式优化和调整模型参数。这种方法旨在不要求大量额外数据或计算资源的情况下,提升预训练模型在特定任务或领域的性能。通过策略性地更新和微调最小化的参数集,该技术实现了有效的适应,特别是在标记数据有限或计算受限的场景中显得特别有价值。
在许多PEFT方法中,基于重参数化的方法是最具代表性的,并且已经得到了广泛研究。LoRA利用低秩近似来高效微调模型参数,在减轻计算需求的同时,实现更有效的适应。特别是为Stable Diffusion模型量身定制的LoRA,为提高涉及扩散过程的生成任务中的适应性和性能提供了有希望的方法。
在此基础上,不同的后续方法被提出以不断提高LoRA的性能。在本文中深入研究了一种细粒度的LoRA,通过为SD的不同块构建块级LoRA适配器,从而提高了在T2I生成任务中个性化的性能。
T2I Personalization via Fine-tuning
T2I个性化目标的任务是教导预训练模型根据输入提示生成具有高主体保真度的新颖图像,同时包含特定的风格。许多近期的研究提出了不同的微调技术来应对这一任务。基于文本反转的方法将文本信息反转翻译为个性化的视觉表示,并提高了基于扩散的生成模型的适应性和定制性,提供了一种生产与输入文本中描述的个性化内容紧密匹配的图像的方法。
DreamBooth及其后续方法通过优化整个SD网络权重来学习特定主体的先验,这使得输出图像具有更高的主体保真度。与之不同,由LoRA为代表的几项工作通过不同的重参数化方法解决这一任务,这更加轻量级且高效。然而,尽管这些基于重参数化的方法能够生成高质量的以主体为驱动生成物,它们很少探索针对SD不同模块的细粒度参数优化。
Preliminaries
LoRA 首先被提出作为NLP领域中大型语言模型的微调方法,后来被引入到SD模型中,用于高效的文本到图像(T2I)生成。
LoRA指出,预训练模型的权重矩阵具有低内在特征维度,因此将模型权重更新 分解为两个低维矩阵, 和 ,其中 是这两个矩阵的维度。在微调过程中,冻结原始权重,只调整矩阵 和 。因此,前向计算过程 可以更新为:
其中 是输出特征图。在应用的早期阶段,LoRA仅用于SD的跨注意力层。在此基础上,针对卷积网络的LoRA(LoCon)进一步将LoRA扩展到卷积层。
对于一个具有权重更新 的卷积层,其中 是核大小, 和 分别是输入和输出通道数。卷积层可以通过两个连续的卷积层近似,这两个卷积层的权重更新分别为 和 。
Method
Block-wise Fine-grained Fine-tuning
为了增强文本到图像生成中的个性化和风格化,我们提出了一种逐块进行的LoRA方法,用于对SD进行细粒度的微调。一般来说,SD中的LoRA是通过在SD的U-Net所有块中执行低秩微调注意力层来实现的(卷积层进一步涉及到LoCon)。
然而,在结合不同类型的全块微调LoRA进行T2I生成时,往往无法获得满意的生成结果。因此,为了提高混合LoRA的生成质量,我们专注于研究U-Net的哪些部分应该进行微调,以获得更好的个性化和风格化。具体来说,通过将LoRA矩阵的秩设置为零,我们可以跳过当前块的LoRA微调。这样,SD使用原始的预训练权重,而不是添加LoRA的权重:
因此,通过控制SD中U-Net不同部分的LoRA微调,可以学习到分块LoRA对T2I输出结果潜在的影像。
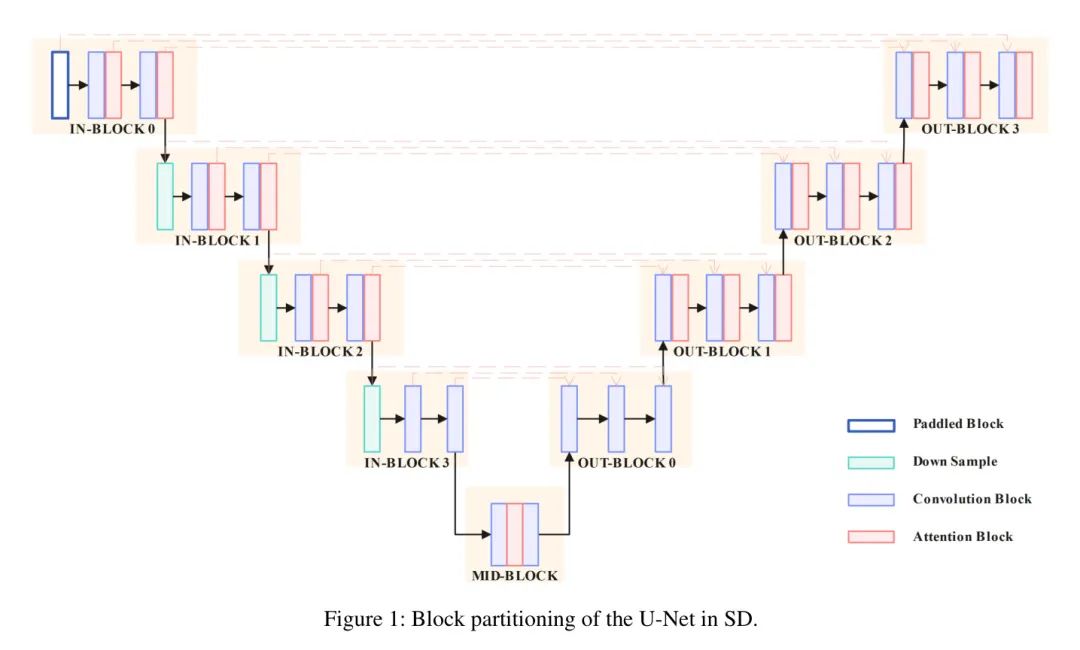
如图1所示,我们将SD中的U-Net划分为几个部分,包括四个内部块、一个中间块和四个外部块。通过这种设计,我们可以对不同U-Net块的细粒度低秩进行微调,并分别评估个性化与风格化任务中不同设置的生成性能。在这项工作中选择使用全块LoRA/LoCon来训练角色,并以块的方式进行风格低秩微调,具体将在实验部分进行讨论。
Experiments
Implementation details
我们使用了Manga Face Dataset作为漫画风格LoRA的训练数据集。对于其他风格LoRA和角色LoRA,我们使用了自定义的训练数据集。每个数据集都设置为包含20张图像重复25次,并由基础模型生成的约500张正则化图像作为补充。
根据[23]的工作,使用标签作为标题的培训效果,形式为$
对于所有实验,我们采用Stable Diffusion 1.4作为基础的T2I生成模型,并将微调步骤设置为11,000,批量大小为2。在推断过程中采用_DPM 2M++ Karras_作为采样器,采样步骤为25,无分类器指导(CFG)尺度为7.0,生成图像的分辨率与训练图像保持一致。为了进行公平的比较,我们为所有方法保持了推断提示和所有超参数固定。
Results
首先,比较了所提出的按块细调方法与原始的LoRA/LoCon,如图2和图3所示。这里我们方法的成果是在最佳设置下生成的,即字符LoRA/LoCon + 按块风格LoRA/LoCon,这一设置将在消融研究中介绍。

结果显示,我们可以很容易地看出,按块LoRA/LoCon模型在个性化和风格化性能上比LoRA/LoCon模型的设置要好。同时,LoRA/LoCon未能生成具有目标风格的图像。此外,如图2和图3所示,与仅在推断过程中对SD的特定块使用调试良好的LoRA/LoCon相比,我们提出的按块LoRA/LoCon细调在个性化方面具有明显优势。

在消融研究中,我们首先评估了三种不同类型的角色LoCon和风格LoCon组合的性能。每个块状的LoCon组合都能将角色与风格混合。然而,如图4(a)所示,块状ID LoCon + 风格LoCon组合的风格与风格LoCon输入不匹配,块状ID LoCon + 块状风格LoCon失去了太多角色的个人细节。

因此,我们认为ID LoCon + 块状风格LoCon组合在这组消融研究中效果最好,它不仅能保持角色的个人细节,还能像LoCon输入一样改变其绘画风格。此外,我们探讨了在ID LoCon + 块状LoCon组合中应该保留哪些块。首先,我们将块状Locon块均匀地分为三部分。然后,在每次训练过程中,我们激活其中一部分块。根据图1所示,"上部块"是In-Block0 + Out-Block3,"中部块"是IN-Block1 + Out-Block2,而"底部块"是In-Block2 + Out-Block1。结果在图4(b)中提供。我们可以看到,当仅激活上部块时,即顶部输入块和顶部输出块,输出图像完美保持了角色和风格的细节。当仅激活中部块时,输出失去了风格,但图片中出现了更多角色的细节。当仅激活底部块时,所有的目标信息和概念都消失了。
Conclusion
在本文中,我们展示了当使用多个LoRA适配器与基于SD的T2I生成模型生成具有目标个人身份和风格概念的图像时,对SD的特定块进行LoRA微调可以显著优于直接执行原始LoRA微调。
此外,在LoRA模型中选择跳过特定块深刻地影响着T2I模型的输出。因此,本文提出的逐块LoRA微调可被视为在多个LoRA模型协作生成图像时的有效方法,增强了个性化和风格化性能。
未来的实验将集中在结合逐块LoRA和控制网(ControlNet)以实现细粒度控制视觉图引导的T2I生成。将其他重参数化方法,如正交分解,引入到逐块LoRA中,对于更有效和高效的PEFT也是有意义的。
参考
[1].Block-wise LoRA: Revisiting Fine-grained LoRA for Effective Personalization and Stylization in Text-to-Image Generation.
点击上方卡片,关注「AI视界引擎」公众号