图像分割网络FCN详解与代码实现
重磅干货,第一时间送达

全卷积网络(FCN)
卷积神经网络从图像分类到到对象检测、实例分割、到图像语义分割、是卷积特征提取从粗糙输出到精炼输出的不断升级,基于卷积神经网络的全卷积分割网络FCN是像素级别的图像语义分割网络,相比以前传统的图像分割方法,基于卷积神经网络的分割更加的精准,适应性更强。
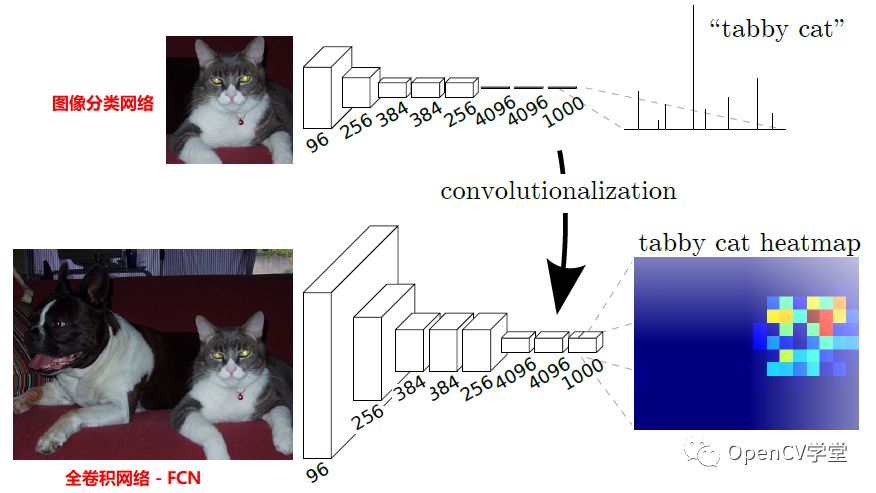
上图是FCN网络像素级别的预测,支持每个像素点20个类别预测,多出来的一个类别是背景。要把一个正常的图像分类网络,转换为一个全卷积网络,就是要对图像分类网络的全连接层重新变为卷积操作,变成携带空间信息多个维度feature maps,图示如下:
当网络转换为全卷积网络之后,对于正常的卷积输出是越来越小了,要实现密集层像素级别预测就需要多卷积输出进行上采样,在FCN网络作者的论文中,作者对如何上采样做了仔细的研究,主要的方法有三种:
-迁移与合并
-双线性插值上采样,对所有分类采用同一个filter,大小固定
-反向卷积(转置卷积),学习,在这个过程中,filters大小是可以设置的FCN网络论文作者经过对比觉得最后一种方法计算更加精准,可以通过卷积学习插值系数,是一种更好的上采样方法,所以FCN最终采样是反向卷积实现上采样,完成像素级别预测。
上采样方法
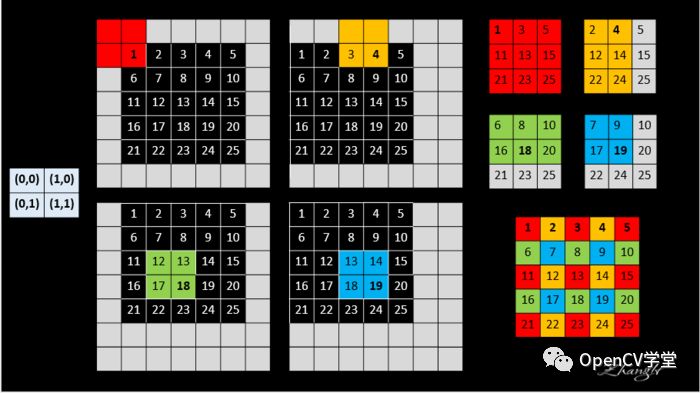
迁移与合并的工作原理可以通过下面这张图来解释
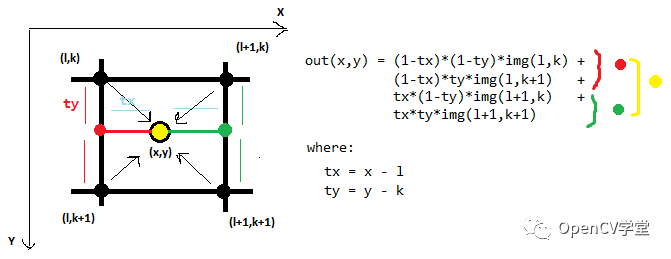
双线性插值比较low,大致看一张图就明白了:
通过双线性插值获取filter的代码如下:
def get_deconv_filter(self, f_shape):
width = f_shape[0]
heigh = f_shape[0]
f = ceil(width/2.0)
c = (2 * f - 1 - f % 2) / (2.0 * f)
bilinear = np.zeros([f_shape[0], f_shape[1]])
for x in range(width):
for y in range(heigh):
value = (1 - abs(x / f - c)) * (1 - abs(y / f - c))
bilinear[x, y] = value
weights = np.zeros(f_shape)
for i in range(f_shape[2]):
weights[:, :, i, i] = bilinear
init = tf.constant_initializer(value=weights,
dtype=tf.float32)
var = tf.get_variable(name="up_filter", initializer=init,
shape=weights.shape)
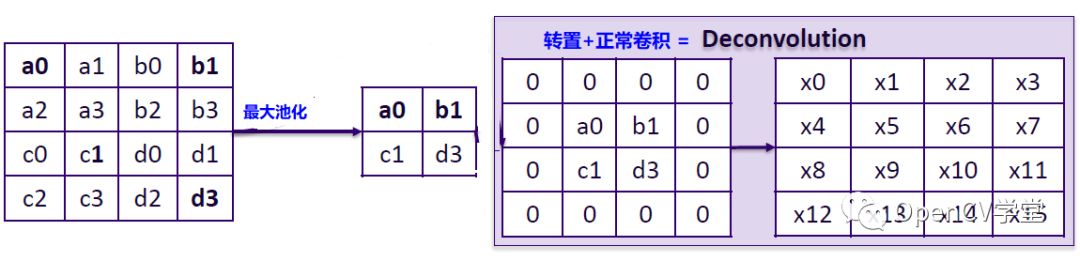
return var反向卷积/转置卷积可以通过下面一张图表示如下:
网络实现
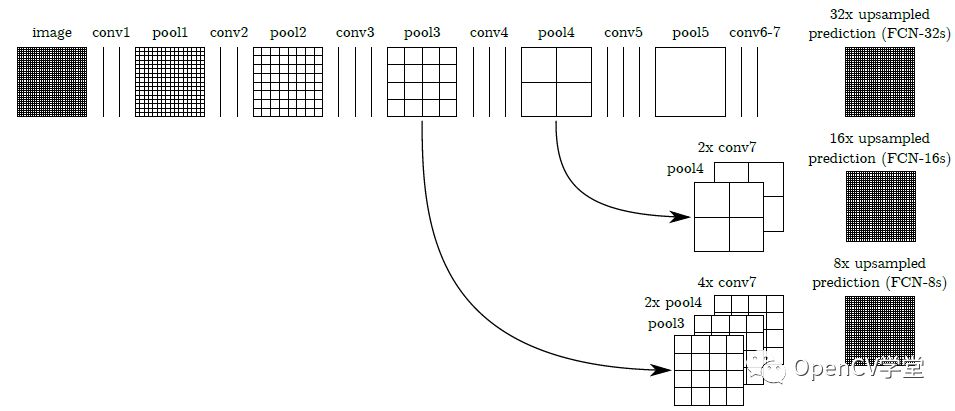
FCN的卷积网络部分可以采用VGG、GoogleNet、AlexNet等作为前置基础网络,在这些的预训练基础上进行迁移学习与finetuning,对反卷积的结果跟对应的正向feature map进行叠加输出(这样做的目的是得到更加准确的像素级别分割),根据上采样的倍数不一样分为FCN-8S、FCN-16S、FCN-32S,图示如下:
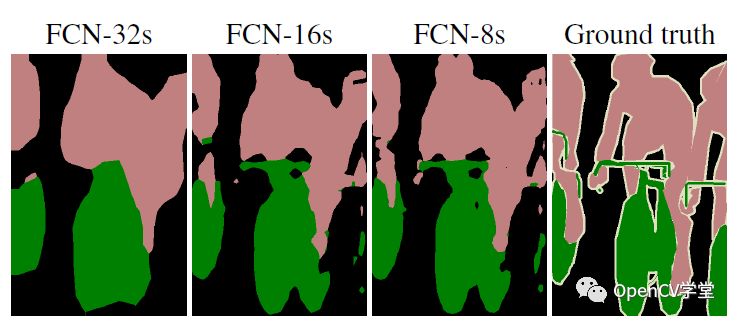
效果对比如下:
基于VGG-16实现tensorflow版本FCN网络模型代码如下
self.conv1_1 = self._conv_layer(bgr, "conv1_1")
self.conv1_2 = self._conv_layer(self.conv1_1, "conv1_2")
self.pool1 = self._max_pool(self.conv1_2, 'pool1', debug)
self.conv2_1 = self._conv_layer(self.pool1, "conv2_1")
self.conv2_2 = self._conv_layer(self.conv2_1, "conv2_2")
self.pool2 = self._max_pool(self.conv2_2, 'pool2', debug)
self.conv3_1 = self._conv_layer(self.pool2, "conv3_1")
self.conv3_2 = self._conv_layer(self.conv3_1, "conv3_2")
self.conv3_3 = self._conv_layer(self.conv3_2, "conv3_3")
self.pool3 = self._max_pool(self.conv3_3, 'pool3', debug)
self.conv4_1 = self._conv_layer(self.pool3, "conv4_1")
self.conv4_2 = self._conv_layer(self.conv4_1, "conv4_2")
self.conv4_3 = self._conv_layer(self.conv4_2, "conv4_3")
if use_dilated:
pad = [[0, 0], [0, 0]]
self.pool4 = tf.nn.max_pool(self.conv4_3, ksize=[1, 2, 2, 1],
strides=[1, 1, 1, 1],
padding='SAME', name='pool4')
self.pool4 = tf.space_to_batch(self.pool4,
paddings=pad, block_size=2)
else:
self.pool4 = self._max_pool(self.conv4_3, 'pool4', debug)
self.conv5_1 = self._conv_layer(self.pool4, "conv5_1")
self.conv5_2 = self._conv_layer(self.conv5_1, "conv5_2")
self.conv5_3 = self._conv_layer(self.conv5_2, "conv5_3")
if use_dilated:
pad = [[0, 0], [0, 0]]
self.pool5 = tf.nn.max_pool(self.conv5_3, ksize=[1, 2, 2, 1],
strides=[1, 1, 1, 1],
padding='SAME', name='pool5')
self.pool5 = tf.space_to_batch(self.pool5,
paddings=pad, block_size=2)
else:
self.pool5 = self._max_pool(self.conv4_3, 'pool4', debug)
self.fc6 = self._fc_layer(self.pool5, "fc6")
if train:
self.fc6 = tf.nn.dropout(self.fc6, 0.5)
self.fc7 = self._fc_layer(self.fc6, "fc7")
if train:
self.fc7 = tf.nn.dropout(self.fc7, 0.5)
if use_dilated:
self.pool5 = tf.batch_to_space(self.pool5, crops=pad, block_size=2)
self.pool5 = tf.batch_to_space(self.pool5, crops=pad, block_size=2)
self.fc7 = tf.batch_to_space(self.fc7, crops=pad, block_size=2)
self.fc7 = tf.batch_to_space(self.fc7, crops=pad, block_size=2)
return
if random_init_fc8:
self.score_fr = self._score_layer(self.fc7, "score_fr",
num_classes)
else:
self.score_fr = self._fc_layer(self.fc7, "score_fr",
num_classes=num_classes,
relu=False)
self.pred = tf.argmax(self.score_fr, dimension=3)
self.upscore2 = self._upscore_layer(self.score_fr,
shape=tf.shape(self.pool4),
num_classes=num_classes,
debug=debug, name='upscore2',
ksize=4, stride=2)
self.score_pool4 = self._score_layer(self.pool4, "score_pool4",
num_classes=num_classes)
self.fuse_pool4 = tf.add(self.upscore2, self.score_pool4)
self.upscore4 = self._upscore_layer(self.fuse_pool4,
shape=tf.shape(self.pool3),
num_classes=num_classes,
debug=debug, name='upscore4',
ksize=4, stride=2)
self.score_pool3 = self._score_layer(self.pool3, "score_pool3",
num_classes=num_classes)
self.fuse_pool3 = tf.add(self.upscore4, self.score_pool3)
self.upscore32 = self._upscore_layer(self.fuse_pool3,
shape=tf.shape(bgr),
num_classes=num_classes,
debug=debug, name='upscore32',
ksize=16, stride=8)
self.pred_up = tf.argmax(self.upscore32, dimension=3)文章参考链接
https://leonardoaraujosantos.gitbooks.io/artificial-inteligence/content/image_segmentation.html
https://datascience.stackexchange.com/questions/6107/what-are-deconvolutional-layers
https://github.com/muyang0320/tf-fcn下载1:OpenCV-Contrib扩展模块中文版教程 在「小白学视觉」公众号后台回复:扩展模块中文教程,即可下载全网第一份OpenCV扩展模块教程中文版,涵盖扩展模块安装、SFM算法、立体视觉、目标跟踪、生物视觉、超分辨率处理等二十多章内容。 下载2:Python视觉实战项目52讲 在「小白学视觉」公众号后台回复:Python视觉实战项目,即可下载包括图像分割、口罩检测、车道线检测、车辆计数、添加眼线、车牌识别、字符识别、情绪检测、文本内容提取、面部识别等31个视觉实战项目,助力快速学校计算机视觉。 下载3:OpenCV实战项目20讲 在「小白学视觉」公众号后台回复:OpenCV实战项目20讲,即可下载含有20个基于OpenCV实现20个实战项目,实现OpenCV学习进阶。 交流群
欢迎加入公众号读者群一起和同行交流,目前有SLAM、三维视觉、传感器、自动驾驶、计算摄影、检测、分割、识别、医学影像、GAN、算法竞赛等微信群(以后会逐渐细分),请扫描下面微信号加群,备注:”昵称+学校/公司+研究方向“,例如:”张三 + 上海交大 + 视觉SLAM“。请按照格式备注,否则不予通过。添加成功后会根据研究方向邀请进入相关微信群。请勿在群内发送广告,否则会请出群,谢谢理解~