
深度学习中用于张量重塑的 MLP 和 Transformer 之间的差异图解

来源:Deephub Imba 本文约1800字,建议阅读5分钟
本文介绍在设计神经网络时如何解决张量整形的问题。
计算机视觉中使用的神经网络张量通常具有 NxHxWxC 的“形状”(批次、高度、宽度、通道)。这里我们将关注空间范围 H 和 W 中形状的变化,为简单起见忽略批次维度 N,保持特征通道维度 C 不变。我们将 HxW 粗略地称为张量的“形状”或“空间维度”。 在 pytorch 和许多其他深度学习库的标准术语中,“重塑”不会改变张量中元素的总数。在这里,我们在更广泛的意义上使用 重塑(reshape) 一词,其中张量中的元素数量可能会改变。
如何使用 MLP 和 Transformers 来重塑张量?
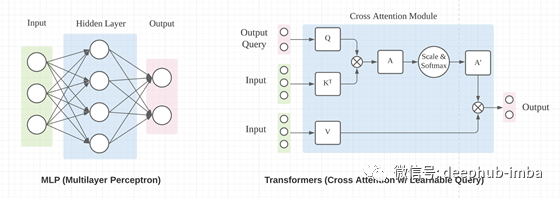
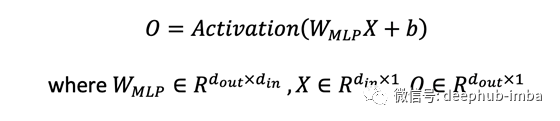
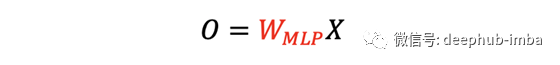
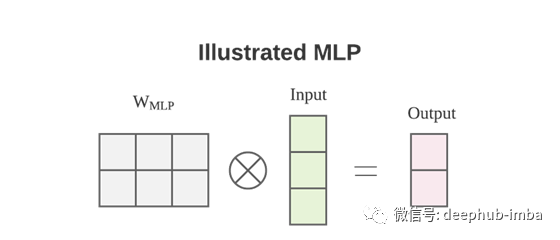
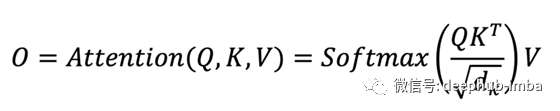
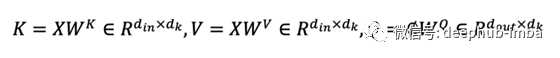
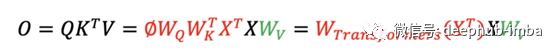
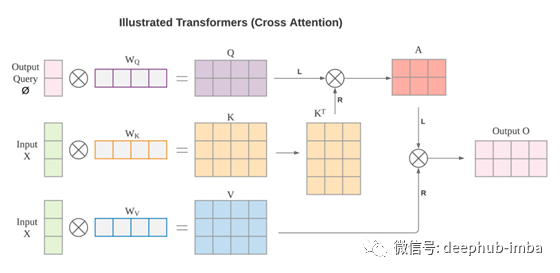
输出 O 通过了一个额外的线性投影,将特征通道从 1 的输入提升到 d_k 的输出。 Transformers 中的 W 矩阵取决于输入 X。
区别1:数据依赖
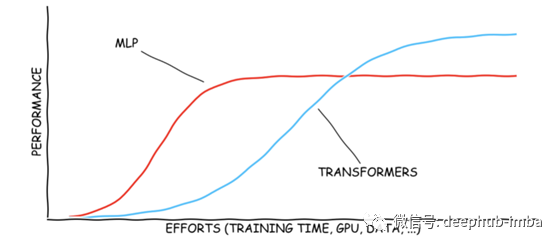
区别2:输入顺序
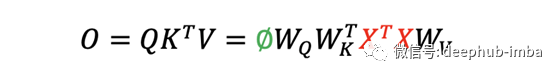


总结
MLP 和 Transformers(交叉注意力)都可以用于张量重塑。 MLP 的重塑机制不依赖于数据,而 Transformers 则依赖于数据。这种数据依赖性使 Transformer 更难训练,但可能具有更高的上限。 注意力不编码位置信息。自注意力是排列等变的,交叉注意力是排列不变的。MLP 对排列高度敏感,随机排列可能会完全破坏 MLP 结果。
引用
Attention is All you Need, NeurIPS 2017 Mathematical properties of Attention in Transformers, Professor Shuiwang Ji’s class notes, TAMU
评论