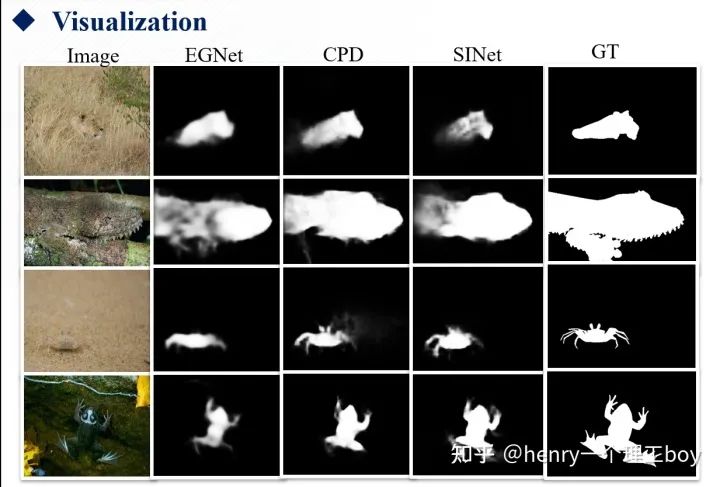
介绍完EGNet和PFANet两种方法以后,就剩下SINet了。SINet的思路来自于19年的一篇CVPR的文章《.Cascaded partial decoder for fast and accurate salient object detection》。这篇文章里提出了CPD的这样一个结构,具体的可以取搜索一下这篇论文,详细了解一下。
首先是我们的搜索模块,通过特征提取,我们得到了这么一些特征,我们希望能够从这些特征中搜索到我们想要的东西。那我们想要的是什么呢?自然就是我们的伪装线索了。所以我们需要对我们的特征们做一些增强的处理,来帮助我们完成搜索的这样一个任务。而我们用到的方法就是RF。我们来看一下具体是怎么样实现的。首先我们把整个模块分为5个分支,这五个分支都进行了1×1的卷积降维,我们都知道,空洞卷积的提出,其目的就是为了增大感受野,所以我们对第一个分支进行空洞数为3的空洞卷积,对第二个分支进行空洞数为5的空洞卷积,对第3个分支进行空洞数为7的空洞卷积,然后将前四个分支的特征图拼接起来,这时候,我们再采用一个1×1卷积降维的操作,与第五个分支进行相加的操作,最后输出增强后的特征图。 这个RF的结构来自于ECCV2018的一篇论文《 Receptive field block net for accurate and fast object detection》,其作用就是帮助我们获得足够的感受野。 我们用RF对感受野增大来进行搜索,那么搜索过后,我们得到了增强后的候选特征。我们要从候选特征得到我们最后要的伪装目标的检测结果,这里我们用到的方法是PDC模块(即是部分解码组件)。 具体操作是这样的,所以接下来就应该是对它们进行处理了逐元素相乘方式来减少相邻特征之间的差距。我们把RF增强后的特征图作为输入,输入到网络里面。首先对低层的进行一个上采样,然后进行3×3的卷积操作(这里面包含了卷积层,BN层还有Relu层),然后与更高一层的特征图进行乘法的这样一个操作,我们为什么使用逐元素相乘呢?因为逐元素相乘方式能减少相邻特征之间的差距。然后我们再与输入的低层特征进行拼接。 我们前面提到了,我们利用增强后的特征通过PDC得到了我们想要得到的检测结果,但这样的一个结果足够精细吗?其实,这样得到的检测结果是比较粗略的。这是为什么呢?这是因为我们的特征之间并不是有和伪装检测不相关的特征?对于这样的多余的特征,我们要消灭掉。我们将前面得到的检测图称之为 ,而我们要得到精细的结果图 ,就得使用我们的注意力机制了。这里我们引入了搜索注意力,具体是怎么实现的呢?大家想一想我们前面把特征分成了低层特征、高层特征还有中层特征。我们平时一般都叫低层特征和高层特征,很少有提到中层特征的。其实我们这里这样叫,是有打算的,我们认为中层特征他既不像低层特征那么浅显,也不像高层特征那样抽象,所以我们对他进行一个卷积操作(但是我们的卷积核用的是高斯核函数方差取32,核的尺寸我们取为4,我们学过数字图像处理,都知道这样的一个操作能起到一个滤波的作用,我们的不相关特征能被过滤掉)但是有同学就会问了,那你这样一过滤,有用的特征不也过滤掉了吗?基于这样的考虑,我们把过滤后的特征图与刚才的这个 再来做一个函数,什么函数呢?就是一个最大化函数,这样我们不就能来突出伪装图 初始的伪装区域了吗?