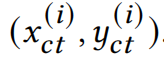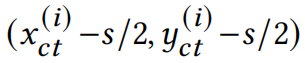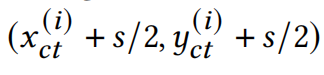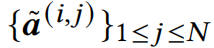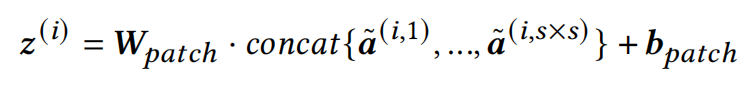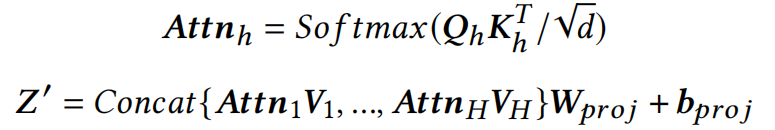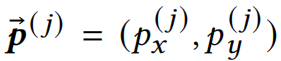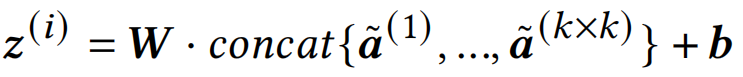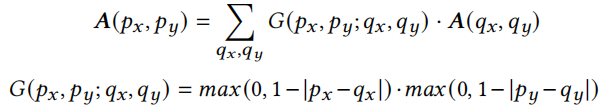点击下方“AI算法与图像处理”,一起进步!
重磅干货,第一时间送达
写在前面
目前,Transformer在计算机视觉方面取得了巨大的成功,但是如何在图像中更加有效的分割patch仍然是一个问题。现有的方法通常是将图片分成多个固定大小的patch,然后进行embedding,但这可能会破坏图像中的语义。
为了解决这个问题,作者提出了一个可变形的分patch(DePatch)模块,它以数据驱动的方式将图像自适应地分割成具有不同位置和大小的patch,而不是使用预定义的固定patch分割方式。通过这个方法,就可以避免原来方法对语义信息的破坏,很好地保留patch中的语义信息。
DePatch模块可以作为一个即插即用的模块,嵌入到不同的Transformer结构中,以实现端到端训练。作者将DePatch模块嵌入到Pyramid Vision Transformer (PVT)中,得到一个新的Transformer结构,Deformable Patch-based Transformer (DPT) 。
最后作者在分类和检测任务上进行了实验,结果表明,DPT在ImageNet分类上的准确率为81.9%;在MSCOCO数据集上,使用RetinaNet进行目标检测的准确率为43.7% box mAP,使用MaskR-CNN的准确率为44.3%。
论文和代码地址

DPT: Deformable Patch-based Transformer for Visual Recognition
论文:https://arxiv.org/abs/2107.14467
代码:https://github.com/CASIA-IVA-Lab/DPT
Motivation
近年来,Transformer在自然语言处理和语音识别方面取得了重大进展,逐渐成为序列建模任务的主流方法。受此启发,一些研究者成功地将Transformer应用于计算机视觉领域,并在图像分类、目标检测和语义分割等方面取得了良好的性能。
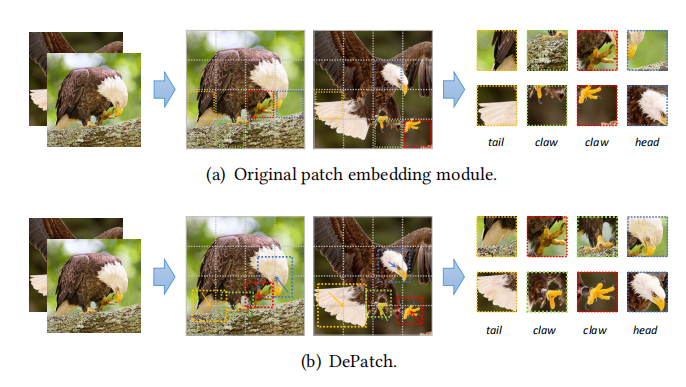
与NLP任务类似,Transformer通常将输入图像分成一系列固定大小的patch,然后通过Multi-head Self-Attention来建模不同patch之间的上下文关系。与卷积神经网络相比,Transformer可以有效地捕获序列内的长距离依赖关系,提取的特征包含更多的语义信息。虽然目前Vision Transformer在CV任务中达到了比较不错的效果,但依旧存在一些问题。目前的工作大多都没有考虑图像的内容信息,使用了一个固定大小的patch embedding。这种“hard” patch分割方法可能会带来两个问题:
1)图像中对象的局部结构被拆分 。(一个固定的patch很难捕获完整的与对象相关的局部结构,因为对象在不同的图像中具有不同的尺度。如上图a所示,老鹰的尾巴、头等局部结构都被拆分到了不同patch中)2)不同图像之间的语义不一致性 。(不同图像中的同一对象可能有不同的几何变化(缩放、旋转等)。分割图像patch的固定方法忽略了这种变化,可能将不同图片中的同一对象处理成不同的信息。)因此,这些固定的patch分割方法可能会破坏语义信息,从而导致性能下降。为了解决上述问题,本文提出了一个新的模块(DePatch),以一种可变形的方式对图像进行分割,从而在一个patch中保留语义信息,减少图像分割造成的语义破坏。具体实现上,DePatch模块能够根据输入的视觉特征,学习每个patch的偏移(offset)和大小(scale),从而生成可变形的patch(如上图b所示)。此外这是一个轻量级的即插即用模块,能够被用于各种Transformer结构中。在本文,作者将DePatch模块嵌入到了Pyramid Vision Transformer (PVT)中,形成Deformable Patch-based Transformer(DPT)。通过自适应调整的可变形patch,DPT能够基于局部的上下文信息为每个patch生成完整、鲁棒、有辨别性的特征。
方法
3.1. 回顾Vision Transformer
Vision Transformer由三部分组成,分别是:patch embedding层、Multi-head Self-Attention(MSA)层和feed-forward multi-layer perceptrons(MLP)层。网络从patch embedding层开始,该模块将输入图像转换为一系列token序列,然后通过MSA和MLP,获得最终的特征表示。patch embedding层将图像划分为固定大小和位置的patch,然后将他们通过一个线性的embedding层转换到token。我们用一个的张量表示输入的图像特征,先前的工作就是将特征转换到固定大小的N个patch,每个patch的大小为:现在我们将分Patch的过程,仔细的展开讲一下,第i个patch可以被看做是一个矩形区域,这个矩形的中心坐标可以表示为:因为Patch的大小和位置是固定的,所以就能够计算出这个patch左上角和右下角的坐标:
每个patch中有个像素,这些像素的坐标可以表示为:
将这些特征铺平,并由线性层处理,就能够获得当前patch的embedding的表示:
MSA聚合了整个输入序列上的相对信息,给每个token都能有全局感知。首先将这些token embedding到三个不同的空间Q、K、V,然后Q和K相乘得到attention map,再将attention map与V相乘得到新的特征:
3.2. DePatch模块

上面描述的patch embedding过程是固定不变的。位置和大小𝑠是固定的,因此每个patch的矩形区域不可更改。为了更好地定位重要的结构和处理几何变形,作者提出了一个可变形的patch embedding。
首先,作者将每个patch的位置和大小转换为基于输入内容的预测参数。对于每一个位置,模型预测了一个偏移量,允许patch围绕着原始中心移动。至于大小,模型只需用预测的和替换固定的patch大小的𝑠。这样就可以得到一个新的矩形区域,将其左上角表示为,右下角表示为。根据预测的,和可以表示为:如上图所示,作者添加了一个新的分支来预测这些参数。基于输入特征图,模型首先预测所有patch的参数,然后将其预测区域的特征进行embedding。
其中,是一个线性层。在训练的开始,初始化为s,其他所有的参数都被初始化为0(为了保证最开始优化的时候,就是以前ViT的patch embedding方法)。
在确定矩形区域后,就可以提取每个patch的特征。现在主要的问题是区域具有不同的大小,并且预测的坐标通常是小数的。作者采用采样和插值的方式解决了这个问题。给定区域的左上角和右下角坐标(𝑥_1,𝑦_1)(𝑥_2,𝑦_2)k \times kk是一个超参数。embedding的过程为将采样点的特征用FC进行embedding,得到patch embedding:
采样点的坐标大多是小数的,在计算采样点的特征是,作者采用了双线性插值,用周围点的特征,通过双线性插值得到当前点的特征:
3.3. Overall Architecture
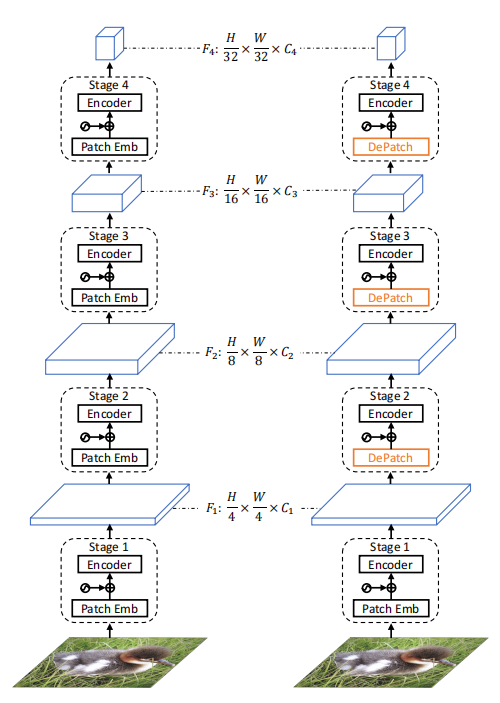
上图展示了VPT和DPT的结构,左边为VPT的结构,右边为DPT的结构。
DePatch是一个自适应的模块,可以改变patch的位置和大小。由于DePatch可以作为一个即插即用模块,因此很容易地可以将DePatch合并到各种Vision Transformer中。作者基于PVT实现了DPT,PVT有四个stage,因此就有四个不同尺度的特征(上图左)。作者将PVT中stage2、stage3、stage4的patch embedding模块换成了DePatch,其他设置保持不变(上图右)。
实验
4.1. Image Classification
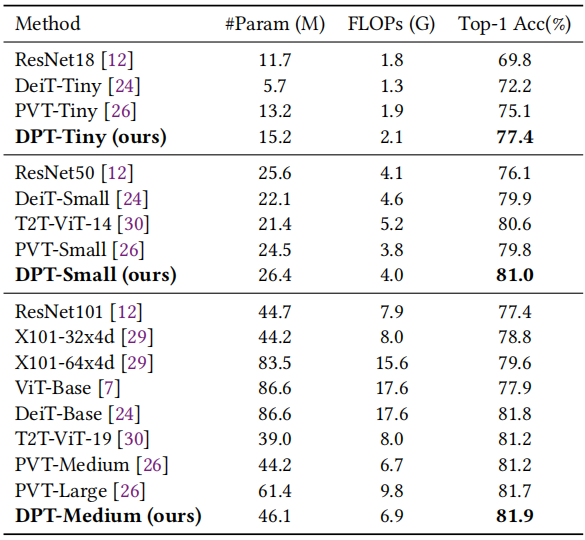
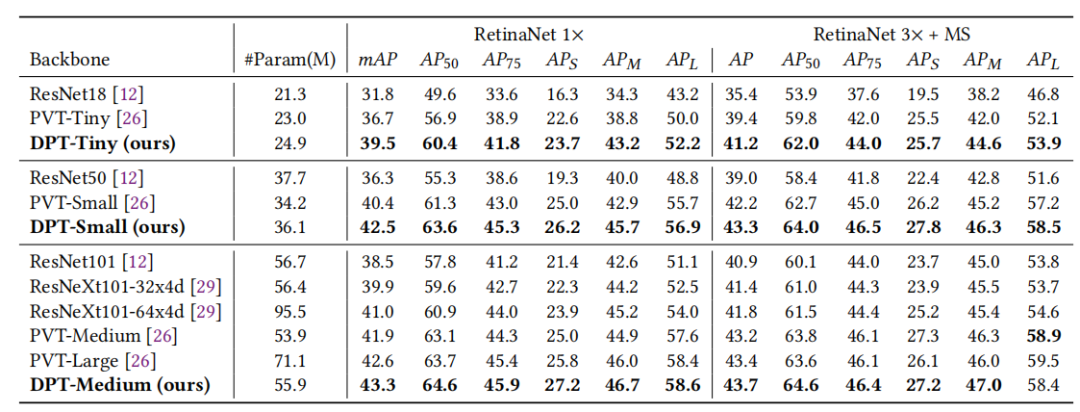
如上表所示,最小的DPT-Tiny获得了77.4%的top-1精度,比相应的baseline PVT模型高出2.3%。DPT-Medium实现了81.9%的top-1精度,甚至优于具有更多参数和计算量的模型,如PVT-Large和DeiT-Base。
4.2. Object Detection

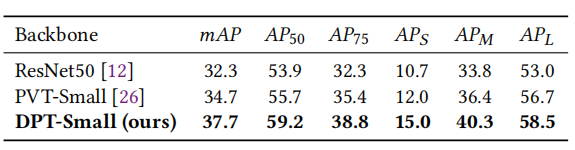
上表比较了DPT与PVT、ResNe(X)t的结果。在相似的计算量下,DPTSmall的性能比PVT-Small好2.1% mAP、比Resnet50好6.2% mAP。
Mask-RCNN上的结果相似。DPT-Small模型在1×schedule下,实现了43.1%的box mAP和39.9%的mask mAP,比PVT-Small高出2.7%和2.1%。
在DETR上,DPT-Small实现了37.7%的box mAP,比PVT-Small高3.0%,比ResNet50高5.4%。
4.3. Ablation Studies
Effect of module position
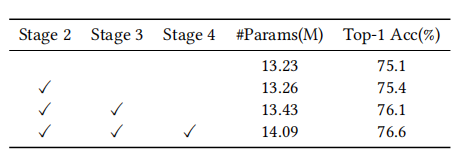
在PVT中,有四个patch embedding模块,第一个直接操作输入图像,其余的操作上一个stage输出的特征。由于原始图像包含的语义信息很少,因此第一个模块很难预测其自身区域之外的偏移量和大小。因此,作者只尝试替换其余的三个patch embedding模块。结果见上表。第2阶段、第3阶段和第4阶段获得的提升分别为0.3%、1.0%和1.5%。替换的patch embedding模块越多,得到的提升就越多。
Effect of number of sampling points
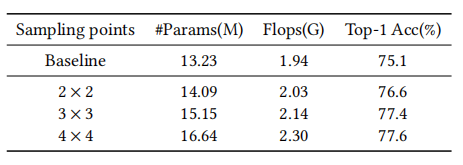
作者通过实验来探究应该在一个预测区域采样多少点。采样更多的点会略微增加FLOPs,但也能根据更大的区域获取特征。将采样点从2×2增加到3×3又提高了0.8%,而进一步增加到4×4仅提高了0.2%。由于采样4×4点只得到很少改善。在实验中,作者将𝑘=3作为默认配置。

采样更多的点将有利于DPT与更强的能力,从更大的区域提取特征。从上图可以看出,随着采样点数量的增加,模型预测的scale也会增大。
Decouple offsets and scales

DePatch学习了每个patch的偏移量和大小。作者解耦了这两个因素,以探究每个因素如何影模型,结果如上表所示。只有预测偏移量能比baseline提高1.5%,再预测scale得到0.8%的提升。
Analysis for fast convergence

从上图可以看出,加入DePatch之后,模型的收敛速度加快。
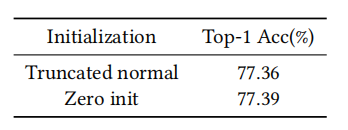
Effect of parameter initialization
4.4. 可视化

上图说明了DePatch预测的patch位置和大小良好,可以捕获重要特征。
总结
本文介绍了一种用于Patch分割的可变形模块DePatch,避免了以前方法分Patch时对模型性能造成的损失。它促使模型从对象相关区域提取Patch信息,使模型对几何变形更加鲁棒。该模块可作为即插即用模块,改进各种Vision Transformer结构,因此作者在PVT上加入了DePatch模块,得到DPT。大量的图像分类和目标检测实验表明,DPT可以提取更好的特征,其性能优于基于CNN的模型和其他Vision Transformer结构。
下载1:何恺明顶会分享
在「AI算法与图像处理」公众号后台回复:何恺明,即可下载。总共有6份PDF,涉及 ResNet、Mask RCNN等经典工作的总结分析
下载2:终身受益的编程指南:Google编程风格指南
在「AI算法与图像处理」公众号后台回复:c++,即可下载。历经十年考验,最权威的编程规范!
在「AI算法与图像处理」公众号后台回复:CVPR,即可下载1467篇CVPR 2020论文 和 CVPR 2021 最新论文