
BatchNorm的避坑指南(上)
 点蓝色字关注“机器学习算法工程师”
点蓝色字关注“机器学习算法工程师”
设为星标,干货直达!
BatchNorm作为一种特征归一化方法基本是CNN网络的标配。BatchNorm可以加快模型收敛速度,防止过拟合,对学习速率更鲁棒,但是BatchNorm由于在batch上进行操作,如果使用不当可能会带来副作用。近期Facebook AI的论文Rethinking "Batch" in BatchNorm系统且全面地对BatchNorm可能会带来的问题做了总结,同时也给出了一些规避方案和建议,堪称一份“避坑指南”。
BatchNorm
BatchNorm主要在CNN网络中应用,对于NLP领域,常采用的transformer采用的是LayerNorm,所以这里只讨论BatchNorm2D。在训练阶段,对于shape为的mini-batch ,BatchNorm首先计算各个channel的均值和方差:
然后BatchNorm对shape为特征进行归一化:
可以看到计算均值和方差是依赖batch的,这也就是BatchNorm的名字由来。在测试阶段,BatchNorm采用的均值和方差是从训练过程估计的全局统计量(population statistics):和,这两个参数也是从训练数据学习到的参数(但不是可训练参数,没有BP过程)。常规的做法在训练阶段采用EMA( exponential moving average,指数移动平均,在TensorFlow中EMA产生的均值和方差称为moving_mean和moving_var,而PyTorch则称为running_mean和running_var)来估计:
训练阶段采用的是mini-batch统计量,而测试阶段是采用全局统计量,这就造成了BatchNorm的训练和测试不一致问题,这个后面会详细讨论。
除了归一化,BatchNorm还包含对各个channel的特征做affine transform(增加特征表征能力):
这里的和是可训练的参数,但是这个过程其实没有batch的参与,从实现上等价于额外增加一个depthwise 1 × 1卷积层。BatchNorm的麻烦主要来自于mini-batch统计量的计算和归一化中,这个affine transform不是影响因素,所以后面的讨论主要集中在前面。
围绕着batch所能带来的问题,论文共讨论了BatchNorm的四个方面:
Population Statistics:EMA是否能够准确估计全局统计量以及PreciseBN; Batch in Training and Testing:训练采用mini-batch统计量,而测试采用全局统计量,由此带来的不一致问题; Batch from Different Domains:BatchNorm在multiple domains中遇到的问题; Information Leakage within a Batch:BatchNorm所导致的信息泄露问题;
第二个应该是大家都熟知的问题,但是其实BatchNorm可能影响的方面是很多的,如域适应(domain adaptation)和对比学习中信息泄露问题。另外,这里讨论的4个方面也不是独立的,它们往往交织在一起。
Population Statistics
训练过程中的均值和方差是mini-batch计算出来的,但是在推理阶段往往是每次只处理一个sample,没有办法再计算依赖batch的统计量。BatchNorm采用的方法是训练过程中用EMA估计全局统计量,但是这个估计可能会够好:当较大时,每个iteration中mini-batch的统计量对全局统计量贡献很少,这会导致更新过慢;当较大时,每个iteration中mini-batch的统计量会起主导作用,导致估计值不能代表全局。一般情况取一个较大的值,如0.9或0.99,这是一个超参数。论文中在ResNet50的训练过程(256 GPU,每个GPU batch_size=32)随机选择模型的某个BatchNorm层的某个channel,绘制了其EMA mean以及population mean,这里的population mean采用当前模型在100 mini-batches的batch mean的平均值来估计,这个可以代表当前模型的全局统计量,对比图如下所示。在训练前期,从图a可以看到EMA mean和当前的batch mean是有距离的,而图b说明EMA mean是落后于当前模型的近似全局统计量的,但是到训练中后期EMA mean就比较准确了。
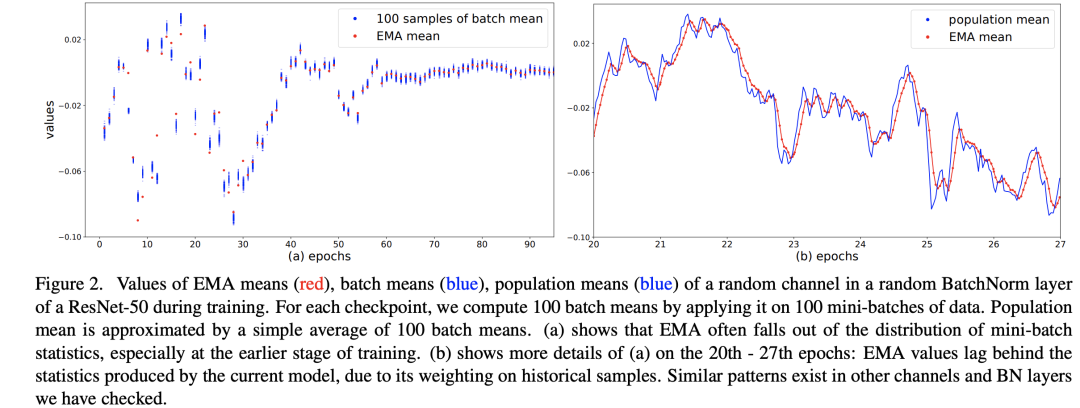
这说明EMA统计量在训练早期是有偏差的。一个准确的全局统计量应该是:使用整个训练集作为一个batch计算特征的均值和方差,但是这个计算成本太高了,论文中提出采用一种近似方法来计算:首先采用固定模型(训练好的)计算很多mini-batch;然后聚合每个mini-batch的统计量来得到全局统计量。假定共需要计算个samples,batch_size为,那么共计算个mini-batch,记它们的统计量为,那么全局统计量可以近似这样计算:
这其实只是一种聚合方式,论文附录也讨论了其它计算方式,结果是类似的。这种BatchNorm称为PreciseBN,具体代码实现可以参考fvcore.nn.precise_bn:
class _PopulationVarianceEstimator:
"""
Alternatively, one can estimate population variance by the sample variance
of all batches combined. This needs to use the batch size of each batch
in this function to undo the bessel-correction.
This produces better estimation when each batch is small.
See Appendix of the paper "Rethinking Batch in BatchNorm" for details.
In this implementation, we also take into account varying batch sizes.
A batch of N1 samples with a mean of M1 and a batch of N2 samples with a
mean of M2 will produce a population mean of (N1M1+N2M2)/(N1+N2) instead
of (M1+M2)/2.
"""
def __init__(self, mean_buffer: torch.Tensor, var_buffer: torch.Tensor) -> None:
self.pop_mean: torch.Tensor = torch.zeros_like(mean_buffer) # population mean
self.pop_square_mean: torch.Tensor = torch.zeros_like(var_buffer) # population variance
self.tot = 0 # total samples
# update per mini-batch, is called by `update_bn_stats`
def update(
self, batch_mean: torch.Tensor, batch_var: torch.Tensor, batch_size: int
) -> None:
self.tot += batch_size
batch_square_mean = batch_mean.square() + batch_var * (
(batch_size - 1) / batch_size
)
self.pop_mean += (batch_mean - self.pop_mean) * (batch_size / self.tot)
self.pop_square_mean += (batch_square_mean - self.pop_square_mean) * (
batch_size / self.tot
)
@property
def pop_var(self) -> torch.Tensor:
return self.pop_square_mean - self.pop_mean.square()
论文中以ResNet50的训练为例对比了EMA和PreciseBN的效果,如下图所示,可以看到PreciseBN比EMA效果更加稳定,特别是训练早期(此时模型未收敛),虽然最终两者的效果接近。
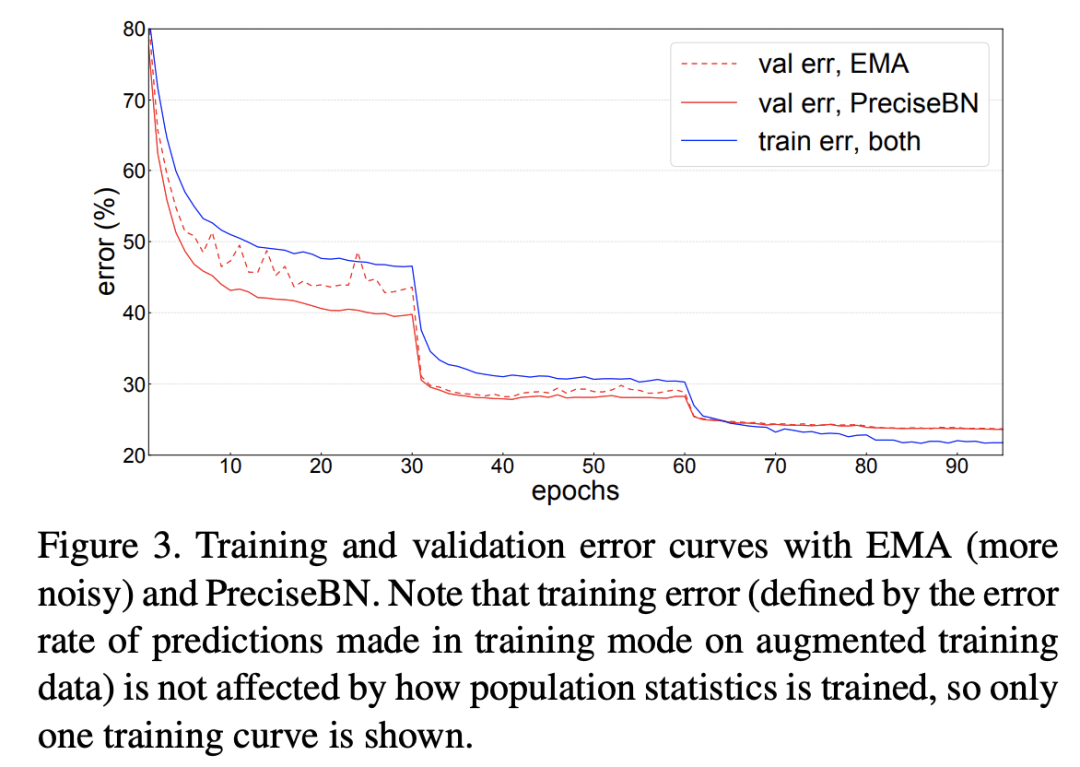
进一步地,如果训练采用更大的batch size,实验发现EMA在训练过程中的抖动更大,但此时PreciseBN效果比较稳定。当采用larger batch训练时,学习速率增大,而且EMA更新次数减少,这些都会对EMA产生较大影响。综上,虽然EMA和PreciseBN最终效果接近(因此EMA的缺点往往被忽视),但是在模型未收敛的训练早期,PreciseBN更加稳定,像强化学习需要在训练早期评估模型效果这种场景,PreciseBN能带来更加稳定可靠的结果。
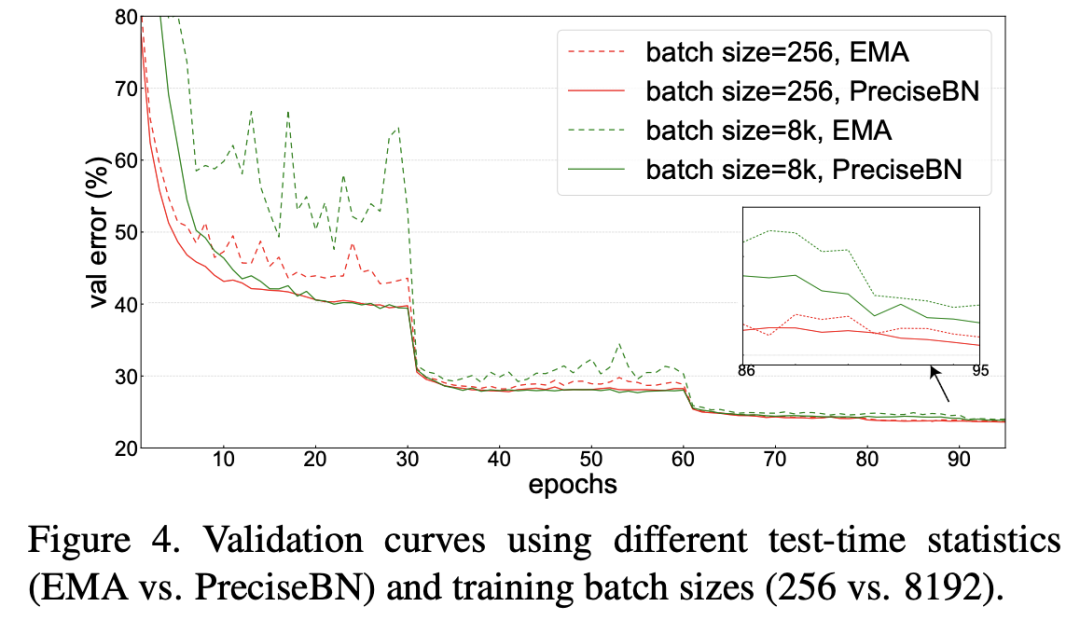
此外,论文也通过实验证明了PreciseBN只需要 samples就可以得到比较好的结果,以ImageNet训练为例,采用PreciseBN评估只需要增加0.5%的训练时间。

另外,论文里还对比了batch size对PreciseBN的影响。这里先理清楚两个概念:(1)normalization batch size(NBS):实际计算统计量的mini-batch的size;(2)total batch size或者SGD batch size:每个iteration中mini-batch的size,或者说每执行一次SGD算法的batch size;两者在多卡训练过程是不等同的(此时NBS是per-GPU batch size,而SyncBN可以实现两者一致)。从结果来看,NBS较小时,模型效果会变差,但是PreciseBN的batch size是相对NBS独立的,所以选择batch size 时PreciseBN可以取得稳定的效果,并且在NBS较小时相比EMA提升效果。

Batch in Training and Testing
前面已经说过BatchNorm在训练时采用的是mini-batch统计量,而测试时采用的全局统计量,这就导致了训练和测试的不一致性,从而带来对模型性能的影响。为此,论文还是以ResNet50训练为例分析这种不一致带来的影响,这里还同时比较了不同NBS带来的差异(SGD batch size固定在1024,此时NBS从2~1024变化),分别对比不同NBS下的三个指标:(1)采用mini-batch统计量在训练集上的分类误差;(2)采用mini-batch统计量在验证集上的分类误差;(3)采用全局统计量在验证集上的分类误差。这里(1)和(3)其实是常规评估方法,而(2)往往不会这样做,但是(1)和(2)就保持一致了(训练和测试均采用mini-batch统计量)。对比结果如下所示,从中可以得到三个方面的结论:
training noise:训练集误差随着NBS增大而减少,这主要是由于SGD训练噪音所导致的,当NBS较小时,mini-batch统计量波动大导致优化困难,从而产生较大的训练误差; generalization gap:对比(1)和(2),两者均采用mini-batch统计量,差异就来自数据集不同,这部分性能差异就是泛化gap; train-test inconsistency:对比(2)和(3),两者数据集一样,但是(2)采用mini-batch统计量,而(3)采用全局统计量,这部分性能差异就是训练和测试不一致所导致的;
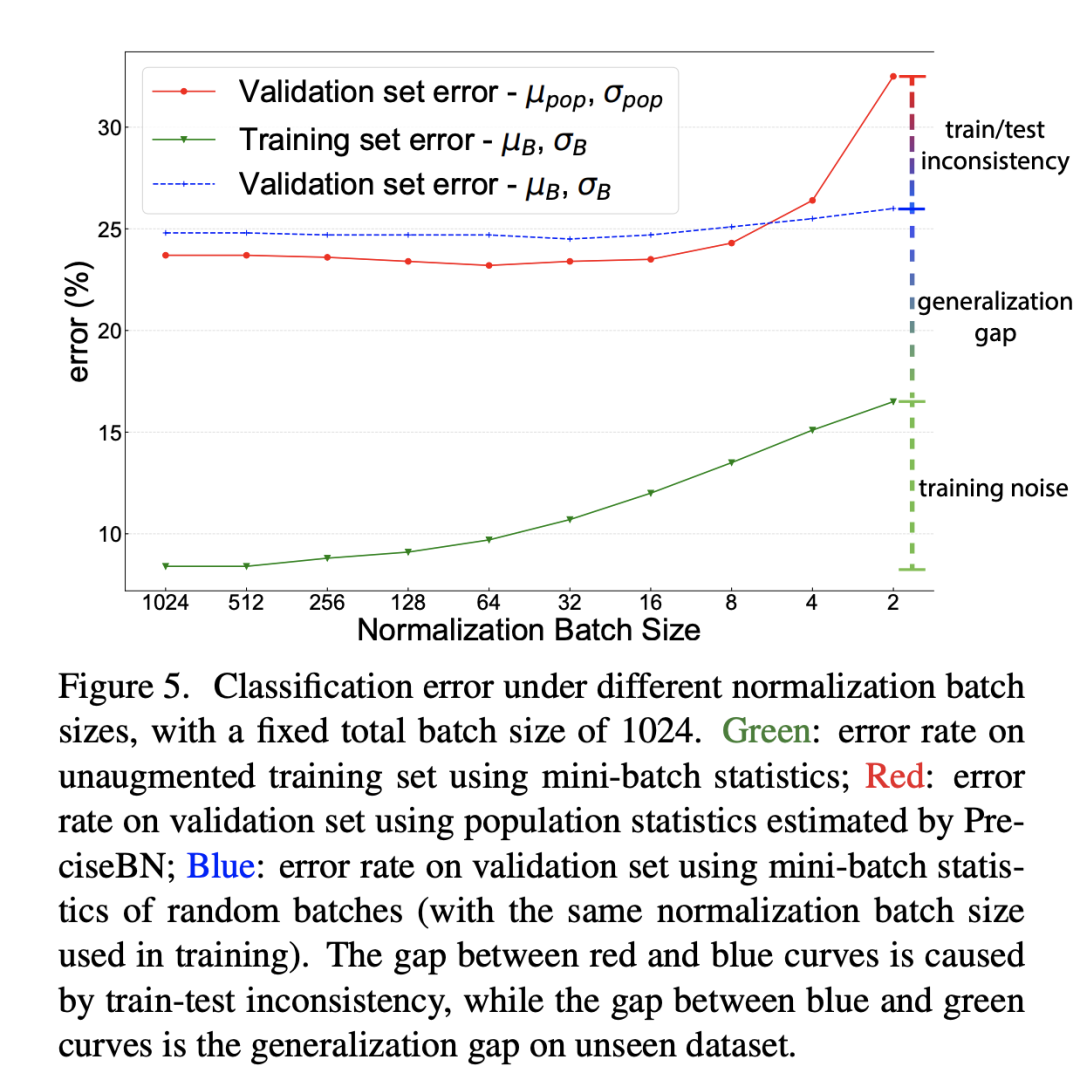
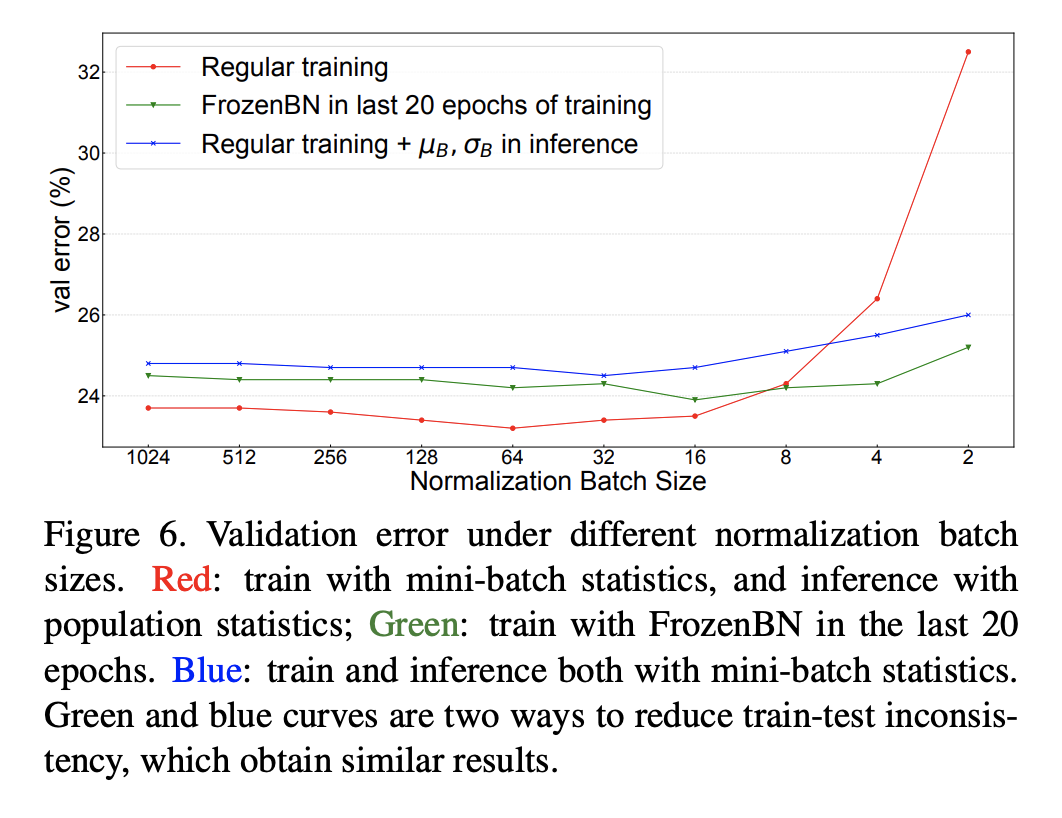
另外,我们可以看到当NBS较小时,(2)和(3)的性能差距是比较大的,这说明如果训练的NBS比较小时在测试时采用mini-batch统计量效果会更好,此时保持一致是比较重要的(这点至关重要)。当NBS较大时,(2)和(3)的差异就比较小,此时mini-batch统计量越来越接近全局统计量。
虽然NBS较小时,在测试时采用mini-batch统计量效果更好,但是在实际场景中几乎不会这样处理(一般情况下都是每次处理一个样本)。不过还是有一些特例,比如两阶段检测模型R-CNN中,R-CNN的head输入是每个图像的一系列region-of-interest (RoIs),一般情况下一个图像会有个RoIs,实际情况这些RoIs是组成batch进行处理的,训练过程是所有图像的RoIs,而测试时是单个图像的RoIs组成batch,在这种情况中测试时就可以选择mini-batch统计量。这里以Mask R-CNN为实验模型,将默认的2fc box head(2个全连接层)换成4conv1fc head(4个卷积层加一个,并且在box head和mask head的每个卷积层后面都加上BatchNorm层,实验结果如下,可以看到采用mini-batch统计量是优于采用全局统计量的,另外在训练过程中每个GPU只用一张图像时,此时测试时采用全局统计量效果会很差,这里有另外的过拟合问题存在,后面再述(BatchNorm导致的信息泄露)。另外R-CNN的head还存在另外的一种训练和测试的inconsistency:训练时mini-batch是正负样本抽样的,而测试时是按score选取的topK,mini-batch的分布就发生了变化。

另外一个避免训练和测试的inconsistency可选方案是训练也采用全局统计量,常用的方案是Frozen BatchNorm (FrozenBN)(训练中直接采用EMA统计量模型无法训练),FrozenBN指的是采用一个提前算好的固定全局统计量,此时BatchNorm的训练优化就只有一个linear transform了。FrozenBN采用的情景是将一个已经训练好的模型迁移到其它任务,如在ImageNet训练的ResNet模型在迁移到下游检测任务时一般采用FrozenBN。不过我们也可以在模型的训练过程中采用FrozenBN,论文中还是以ResNet50为例,在前80个epoch采用正常的BN训练,在后20个epoch采用FrozenBN,对比效果如下,可以看到FrozenBN在NBS较小时也是表现较好,优于测试时采用mini-batch统计量,这不失为一种好的方案。这里值得注意的是当NBS较大时,FrozenBN还是测试时采用mini-batch统计量均差于常规方案(BN训练,测试时采用全局统计量)。
推荐阅读
谷歌AI用30亿数据训练了一个20亿参数Vision Transformer模型,在ImageNet上达到新的SOTA!
"未来"的经典之作ViT:transformer is all you need!
PVT:可用于密集任务backbone的金字塔视觉transformer!
涨点神器FixRes:两次超越ImageNet数据集上的SOTA
不妨试试MoCo,来替换ImageNet上pretrain模型!
机器学习算法工程师
一个用心的公众号
