
(附论文)综述 | 少样本学习
目标检测与深度学习
共 2697字,需浏览 6分钟
· 2021-08-07
点击左上方蓝字关注我们

转载自 | Jy的炼丹炉@知乎
链接 | https://zhuanlan.zhihu.com/p/389689066
论文地址:https://arxiv.org/abs/1904.05046


下面对上述的方法进行详细介绍。
01
举个栗子:在视频手势识别中,有研究团队使用一个大但弱标记的手势库。通过训练集训练的分类器,来从若标记手势库中选择与训练集相同的手势样本,然后使用这些选择的示例构建最后的手势分类器。
新奇的思路:老虎数据集类似于猫数据集,因此可以使用生成对抗网络(GAN),从老虎数据集中合成猫的新样本。
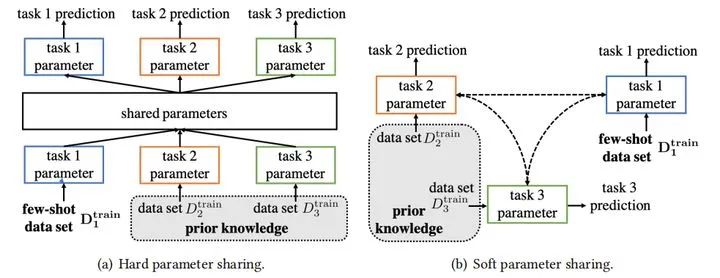
软参数共享:此策略不会在各个任务中显式地共享参数。相反,每个任务都有自己的假设空间和参数。它只鼓励不同任务的参数相似,从而导致类似的假设空间。
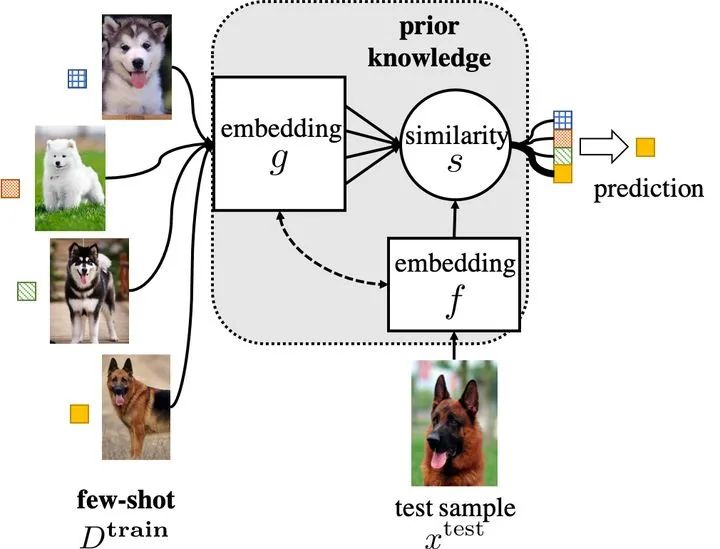

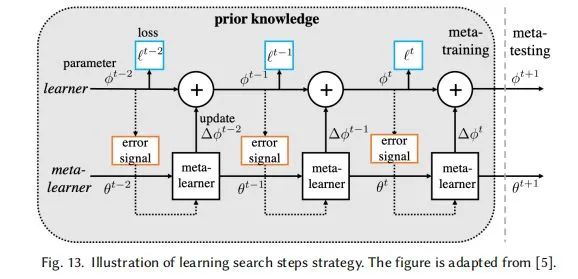
END
整理不易,点赞三连↓
评论